AlignTune: Modular Toolkit for Post-Training Alignment of Large Language Models
作者: R E Zera Marveen Lyngkhoi, Chirag Chawla, Pratinav Seth, Utsav Avaiya, Soham Bhattacharjee, Mykola Khandoga, Rui Yuan, Vinay Kumar Sankarapu
分类: cs.CL, cs.LG
发布日期: 2026-02-10
备注: https://github.com/Lexsi-Labs/aligntune
💡 一句话要点
AlignTune:用于大语言模型后训练对齐的模块化工具包
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 后训练对齐 强化学习 监督微调 模块化工具包
📋 核心要点
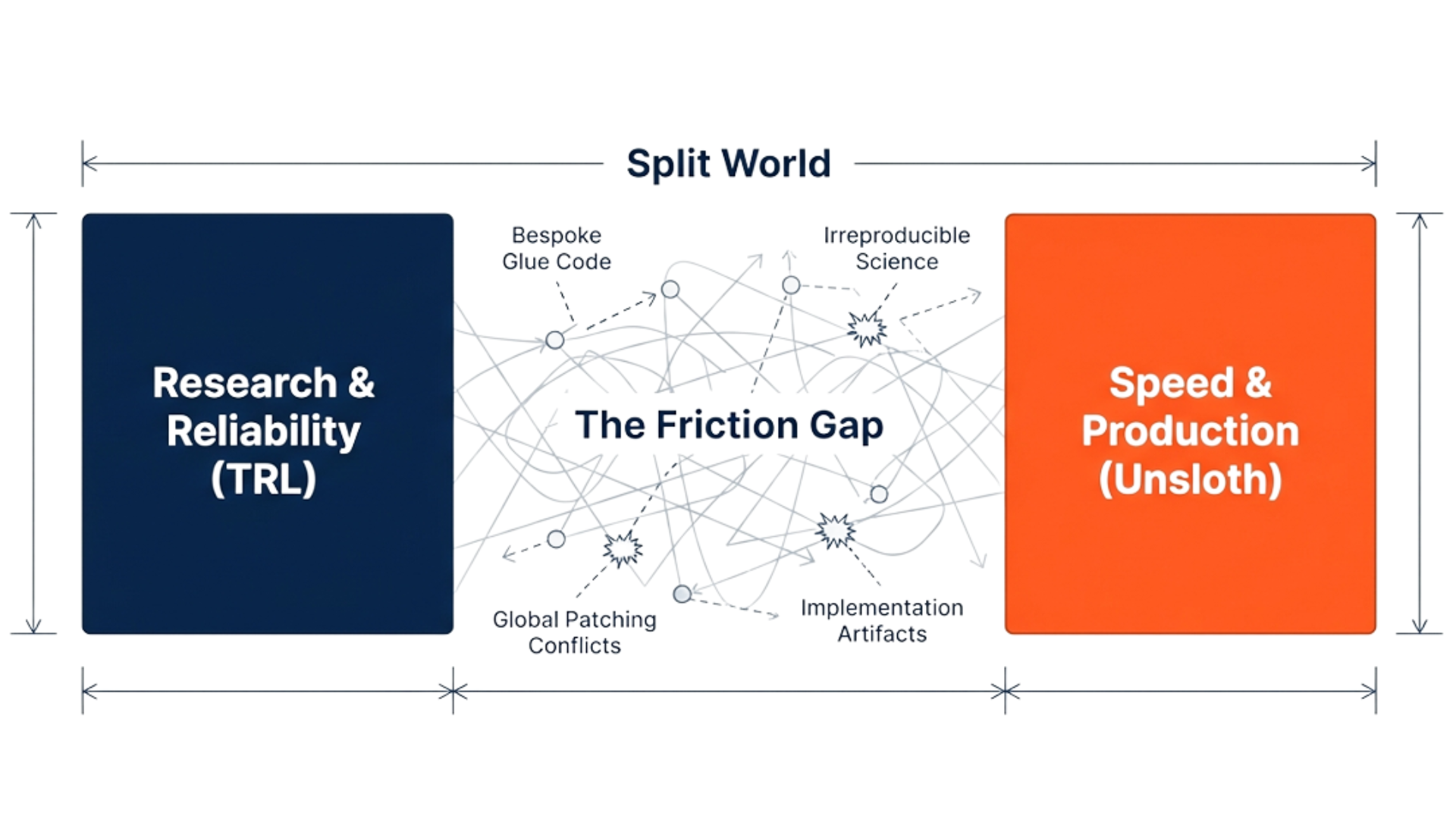
- 现有LLM对齐工具分散且依赖特定后端,导致实验难以复现和比较。
- AlignTune提供统一接口,支持SFT和RLHF,并标准化配置和奖励机制。
- AlignTune通过隔离后端逻辑,实现可控的LLM对齐实验,并提升可复现性。
📝 摘要(中文)
后训练对齐对于部署大型语言模型(LLM)至关重要,但实际工作流程仍然分散在特定于后端的工具和临时代码中,使得实验难以重现。我们发现后端干扰、奖励碎片化和不可重现的pipeline是对齐研究中的关键障碍。我们介绍了AlignTune,这是一个模块化工具包,它为监督微调(SFT)和RLHF风格的优化提供了一个统一的接口,具有可互换的TRL和Unsloth后端。AlignTune标准化了配置,提供了一个可扩展的奖励层(基于规则和学习),并集成了对标准基准和自定义任务的评估。通过将特定于后端的逻辑隔离在单个工厂边界之后,AlignTune实现了受控的比较和可重现的对齐实验。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)后训练对齐过程中存在的工具分散、后端干扰、奖励碎片化以及实验不可复现等问题。现有的对齐方法通常依赖于特定的后端工具,缺乏统一的接口和标准化的配置,导致实验难以重现和比较,阻碍了对齐技术的研究和发展。
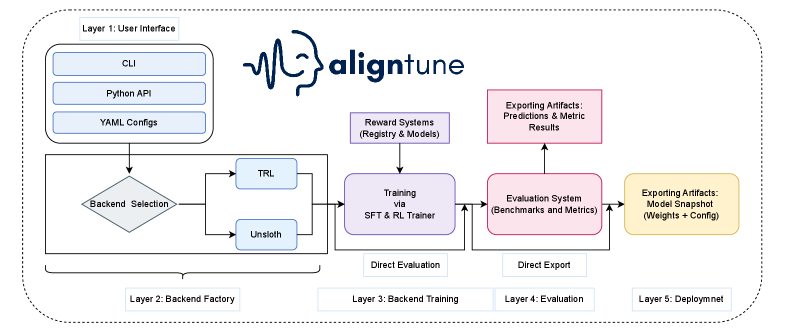
核心思路:AlignTune的核心思路是构建一个模块化的工具包,通过统一的接口封装不同的后端实现(如TRL和Unsloth),从而隔离后端干扰,并提供标准化的配置和可扩展的奖励机制。这种模块化设计使得研究人员可以更方便地进行受控的比较实验,并提高对齐实验的可复现性。
技术框架:AlignTune的整体框架包括以下几个主要模块:1) 统一的配置管理模块,用于标准化实验配置;2) 可互换的后端模块,支持TRL和Unsloth等不同的后端实现;3) 可扩展的奖励层模块,支持基于规则和学习的奖励函数;4) 评估模块,用于在标准基准和自定义任务上评估对齐效果。这些模块通过一个工厂模式进行集成,从而实现模块之间的解耦和可插拔性。
关键创新:AlignTune的关键创新在于其模块化的设计和统一的接口。通过将后端逻辑隔离在单个工厂边界之后,AlignTune实现了对齐实验的可控性和可复现性。此外,AlignTune还提供了一个可扩展的奖励层,支持用户自定义奖励函数,从而更好地适应不同的对齐任务。
关键设计:AlignTune的关键设计包括:1) 使用YAML文件进行配置管理,方便用户自定义实验参数;2) 使用工厂模式封装不同的后端实现,实现后端之间的切换;3) 提供基于规则和学习的奖励函数,并支持用户自定义奖励函数;4) 集成常用的评估指标和数据集,方便用户评估对齐效果。
🖼️ 关键图片

📊 实验亮点
AlignTune通过模块化设计和统一接口,显著提升了LLM对齐实验的可复现性和可控性。它支持多种后端和奖励机制,并集成了标准评估基准。实验结果表明,AlignTune能够有效地对齐LLM,并在多个任务上取得了与现有方法相当或更好的性能。
🎯 应用场景
AlignTune可应用于各种需要对齐的大型语言模型,例如对话系统、文本生成、代码生成等。它能够帮助研究人员和开发者更高效地进行模型对齐实验,提升模型的安全性、可靠性和实用性。该工具包的模块化设计和可扩展性使其能够适应不同的对齐任务和后端环境,具有广泛的应用前景。
📄 摘要(原文)
Post-training alignment is central to deploying large language models (LLMs), yet practical workflows remain split across backend-specific tools and ad-hoc glue code, making experiments hard to reproduce. We identify backend interference, reward fragmentation, and irreproducible pipelines as key obstacles in alignment research. We introduce AlignTune, a modular toolkit exposing a unified interface for supervised fine-tuning (SFT) and RLHF-style optimization with interchangeable TRL and Unsloth backends. AlignTune standardizes configuration, provides an extensible reward layer (rule-based and learned), and integrates evaluation over standard benchmarks and custom tasks. By isolating backend-specific logic behind a single factory boundary, AlignTune enables controlled comparisons and reproducible alignment experiments.