On the Optimal Reasoning Length for RL-Trained Language Models
作者: Daisuke Nohara, Taishi Nakamura, Rio Yokota
分类: cs.CL, cs.AI, cs.LG
发布日期: 2026-02-10
备注: 15 pages, 10 figures. Submitted to the Workshop on Scaling Post-training for LLMs (SPOT) at ICLR 2026
💡 一句话要点
研究强化学习训练的语言模型中推理链长度对性能的影响,并提出优化方法。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 语言模型 推理链 长度控制 计算效率
📋 核心要点
- 现有方法在利用强化学习提升语言模型推理能力时,存在输出链过长导致计算成本增加的问题。
- 该研究通过比较不同长度控制方法,探索强化学习训练语言模型推理的最佳输出长度。
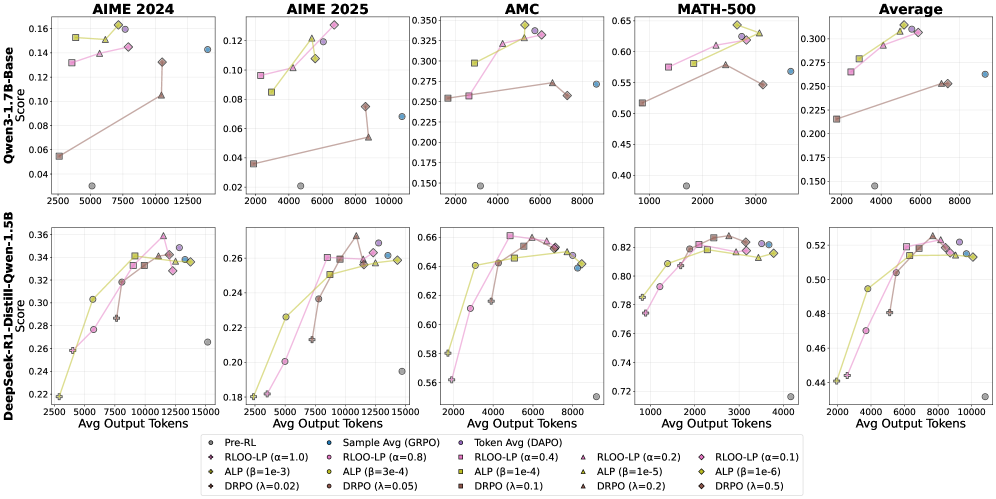
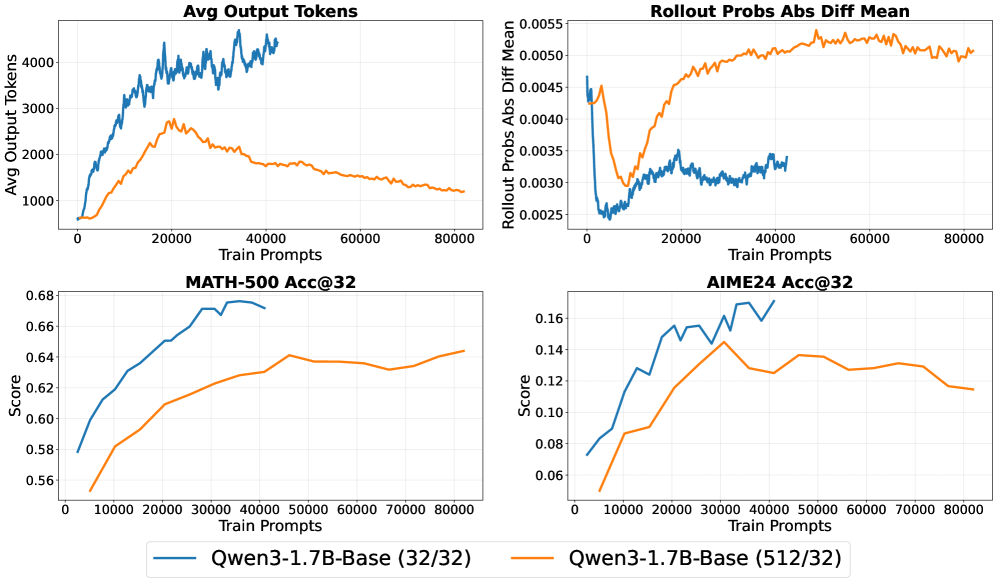
- 实验表明,长度惩罚可能阻碍推理能力学习,适当的长度控制能提升模型效率,并识别出长输出分散和短输出思考不足两种失效模式。
📝 摘要(中文)
强化学习能够显著提升大型语言模型的推理能力,但同时也倾向于延长思维链的输出长度,增加训练和推理过程中的计算成本。尽管已经有长度控制方法被提出,但为了平衡效率和性能,最佳输出长度仍然不明确。本文在Qwen3-1.7B Base和DeepSeek-R1-Distill-Qwen-1.5B两个模型上比较了几种长度控制方法。结果表明,长度惩罚可能会阻碍推理能力的获取,而适当调整的长度控制可以提高具有较强先验推理能力的模型的效率。通过将先前的工作扩展到强化学习训练的策略,我们识别出两种失效模式:1) 长输出会增加分散性;2) 短输出会导致思考不足。
🔬 方法详解
问题定义:论文旨在解决强化学习训练的语言模型在推理过程中,输出链长度对模型性能和效率的影响问题。现有方法虽然可以通过强化学习提升推理能力,但往往会生成过长的推理链,导致计算成本显著增加。同时,简单的长度惩罚可能反而会损害模型的推理能力,因此需要找到一个平衡点,确定最佳的推理链长度。
核心思路:论文的核心思路是通过实验比较不同的长度控制方法,分析它们对模型推理性能和效率的影响。通过对实验结果的分析,识别出长输出和短输出两种极端情况下的失效模式,从而为选择合适的长度控制策略提供指导。论文强调,对于具有较强先验推理能力的模型,适当的长度控制可以提高效率。
技术框架:论文的技术框架主要包括以下几个部分:首先,选择Qwen3-1.7B Base和DeepSeek-R1-Distill-Qwen-1.5B两个预训练语言模型作为实验对象。然后,使用强化学习方法对这些模型进行训练,使其具备推理能力。接着,应用不同的长度控制方法,例如长度惩罚等,来限制模型的输出长度。最后,通过在特定任务上评估模型的性能和效率,比较不同长度控制方法的效果。
关键创新:论文的关键创新在于将长度控制方法的研究扩展到了强化学习训练的语言模型领域。以往的研究主要关注于如何通过强化学习提升模型的推理能力,而忽略了输出长度对性能和效率的影响。论文通过实验揭示了长度惩罚可能阻碍推理能力学习,并识别出长输出分散和短输出思考不足两种失效模式,为未来的研究提供了新的视角。
关键设计:论文的关键设计包括:1) 选择合适的强化学习算法来训练模型,使其具备推理能力;2) 设计不同的长度控制策略,例如长度惩罚,并调整其参数;3) 选择合适的评估指标来衡量模型的性能和效率,例如准确率、计算成本等;4) 通过对比实验,分析不同长度控制策略对模型性能和效率的影响,并识别出最佳的输出长度范围。
🖼️ 关键图片

📊 实验亮点
实验结果表明,长度惩罚可能会阻碍推理能力的获取,而适当调整的长度控制可以提高具有较强先验推理能力的模型的效率。论文识别出两种失效模式:长输出会增加分散性,短输出会导致思考不足。这些发现为优化强化学习训练的语言模型的推理能力提供了重要的指导。
🎯 应用场景
该研究成果可应用于各种需要语言模型进行推理的场景,例如问答系统、对话生成、代码生成等。通过优化推理链的长度,可以提高模型的效率和性能,降低计算成本,并提升用户体验。未来的研究可以进一步探索更有效的长度控制方法,并将其应用于更大规模的语言模型。
📄 摘要(原文)
Reinforcement learning substantially improves reasoning in large language models, but it also tends to lengthen chain of thought outputs and increase computational cost during both training and inference. Though length control methods have been proposed, it remains unclear what the optimal output length is for balancing efficiency and performance. In this work, we compare several length control methods on two models, Qwen3-1.7B Base and DeepSeek-R1-Distill-Qwen-1.5B. Our results indicate that length penalties may hinder reasoning acquisition, while properly tuned length control can improve efficiency for models with strong prior reasoning. By extending prior work to RL trained policies, we identify two failure modes, 1) long outputs increase dispersion, and 2) short outputs lead to under-thinking.