Aligning Tree-Search Policies with Fixed Token Budgets in Test-Time Scaling of LLMs
作者: Sora Miyamoto, Daisuke Oba, Naoaki Okazaki
分类: cs.CL, cs.AI, cs.LG
发布日期: 2026-02-10
💡 一句话要点
提出预算引导的蒙特卡洛树搜索(BG-MCTS),解决LLM测试时定额token预算下的策略对齐问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 树搜索解码 蒙特卡洛树搜索 预算约束 测试时扩展
📋 核心要点
- 现有树搜索解码方法在LLM测试时扩展中,未能有效利用固定token预算,导致搜索效率低下。
- BG-MCTS通过动态调整搜索策略,在预算充足时进行广泛探索,预算紧张时侧重答案细化,实现预算感知的搜索。
- 实验表明,BG-MCTS在数学问题求解任务上,显著优于传统树搜索方法,验证了其在不同预算下的有效性。
📝 摘要(中文)
树搜索解码是一种有效的大型语言模型(LLM)测试时扩展方法,但实际部署对每个查询施加固定的token预算,且预算因设置而异。现有的树搜索策略在很大程度上与预算无关,将预算视为终止条件,这可能导致后期过度分支或过早终止。我们提出了预算引导的蒙特卡洛树搜索(BG-MCTS),这是一种树搜索解码算法,使其搜索策略与剩余token预算对齐:它首先进行广泛探索,然后随着预算的减少,优先考虑细化和答案完成,同时减少来自浅层节点的后期分支。在使用开放权重LLM的MATH500和AIME24/25上,BG-MCTS始终优于与预算无关的树搜索基线。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在测试时扩展中,如何在固定token预算下优化树搜索解码策略的问题。现有的树搜索方法通常忽略预算约束,要么在预算耗尽前过度探索,要么过早终止搜索,导致性能下降。这种预算无关性是现有方法的痛点。
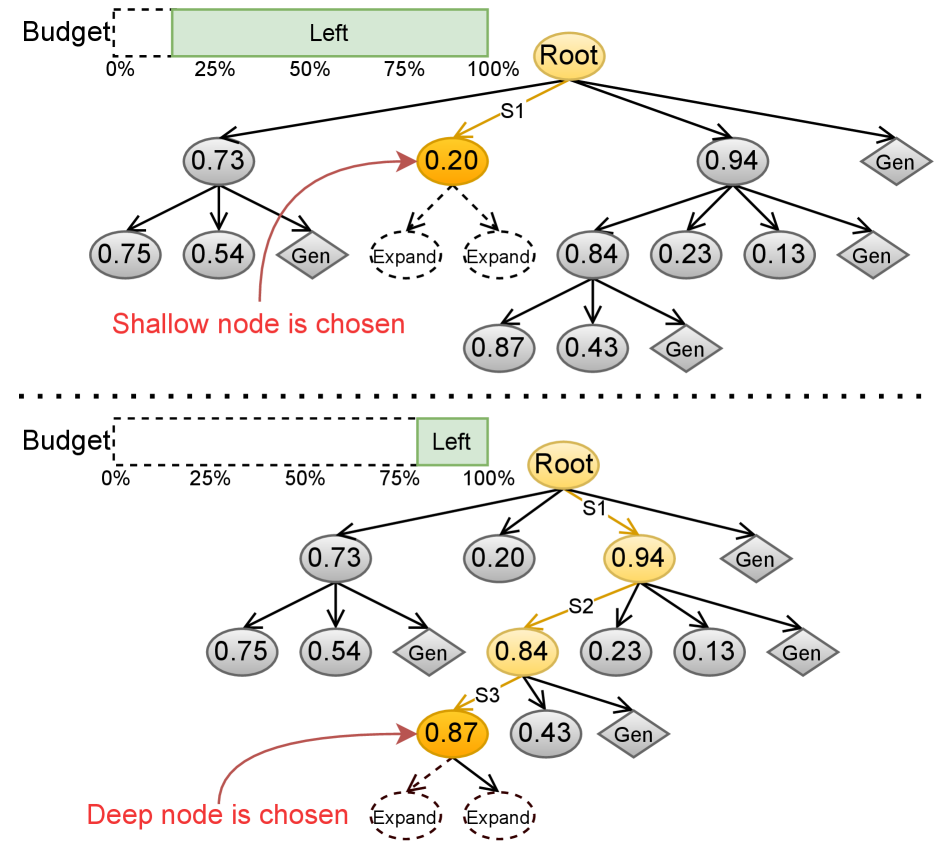
核心思路:论文的核心思路是设计一种预算感知的树搜索策略,即Budget-Guided MCTS (BG-MCTS)。BG-MCTS根据剩余的token预算动态调整搜索策略,在预算充足时进行更广泛的探索,而在预算接近耗尽时,则侧重于对已有结果的细化和答案的完成。这种动态调整旨在最大化预算的利用率,提高解码质量。
技术框架:BG-MCTS的整体框架仍然基于蒙特卡洛树搜索(MCTS),但引入了预算引导机制。主要流程包括:选择(Selection)、扩展(Expansion)、模拟(Simulation)和反向传播(Backpropagation)。在选择阶段,BG-MCTS会考虑节点的访问次数、奖励值以及剩余的token预算,从而选择更有希望且符合预算约束的节点进行扩展。在模拟阶段,根据当前策略生成候选token序列。在反向传播阶段,更新节点的奖励值,并根据预算消耗情况调整搜索策略。
关键创新:BG-MCTS的关键创新在于其预算引导的搜索策略。与传统的MCTS不同,BG-MCTS引入了一个预算感知的探索-利用平衡机制。具体来说,BG-MCTS使用一个动态调整的探索系数,该系数随着剩余预算的减少而减小。这意味着在预算充足时,BG-MCTS会更加倾向于探索新的分支,而在预算紧张时,则更加倾向于利用已有的信息。这种动态调整使得BG-MCTS能够更好地适应不同的预算约束。
关键设计:BG-MCTS的关键设计包括:1) 预算感知的选择策略:在选择节点时,引入一个与剩余预算相关的权重,用于调整探索和利用的平衡。2) 动态调整的探索系数:根据剩余预算动态调整探索系数,使得搜索策略能够自适应地调整探索和利用的比例。3) 奖励函数的设计:奖励函数需要能够反映生成序列的质量,同时也要考虑预算消耗情况,避免过度消耗预算。
🖼️ 关键图片


📊 实验亮点
实验结果表明,BG-MCTS在MATH500和AIME24/25数据集上,显著优于传统的树搜索基线。例如,在MATH500上,BG-MCTS在不同预算下均取得了更高的准确率,并且在低预算情况下,提升幅度更为明显。这表明BG-MCTS能够更有效地利用有限的token预算,提高LLM的推理能力。
🎯 应用场景
BG-MCTS可应用于各种需要使用LLM进行推理或生成的场景,尤其是在资源受限的环境中,例如移动设备或边缘计算平台。该方法可以提高LLM在有限计算资源下的性能,使其能够更好地服务于实际应用,例如智能助手、机器翻译和文本摘要等。
📄 摘要(原文)
Tree-search decoding is an effective form of test-time scaling for large language models (LLMs), but real-world deployment imposes a fixed per-query token budget that varies across settings. Existing tree-search policies are largely budget-agnostic, treating the budget as a termination condition, which can lead to late-stage over-branching or premature termination. We propose {Budget-Guided MCTS} (BG-MCTS), a tree-search decoding algorithm that aligns its search policy with the remaining token budget: it starts with broad exploration, then prioritizes refinement and answer completion as the budget depletes while reducing late-stage branching from shallow nodes. BG-MCTS consistently outperforms budget-agnostic tree-search baselines across different budgets on MATH500 and AIME24/25 with open-weight LLMs.