LEMUR: A Corpus for Robust Fine-Tuning of Multilingual Law Embedding Models for Retrieval
作者: Narges Baba Ahmadi, Jan Strich, Martin Semmann, Chris Biemann
分类: cs.CL, cs.AI, cs.IR
发布日期: 2026-02-10
备注: Accepted at EACL SRW 26
🔗 代码/项目: GITHUB | HUGGINGFACE
💡 一句话要点
LEMUR:用于稳健微调多语言法律嵌入模型的检索语料库
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言法律信息检索 法律嵌入模型 对比学习 低资源语言 跨语言检索
📋 核心要点
- 现有法律领域的多语言语料库缺乏语义检索能力,且PDF文本提取质量不高,影响法律信息检索。
- 构建大规模多语言法律语料库LEMUR,并利用对比学习目标微调多语言嵌入模型,提升检索性能。
- 实验表明,微调后的模型在低资源语言上检索准确率提升显著,且跨语言检索性能良好。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地被用于访问法律信息。然而,由于不可靠的检索和缺乏领域自适应的开放嵌入模型,它们在多语言法律环境中的部署受到限制。特别地,现有的多语言法律语料库并非为语义检索而设计,并且基于PDF的立法来源由于不完善的文本提取而引入了大量的噪声。为了解决这些挑战,我们引入了LEMUR,这是一个大规模的多语言欧盟环境立法语料库,由来自25种语言的24,953份官方EUR-Lex PDF文档构建而成。我们通过使用词汇内容得分(LCS)衡量相对于权威HTML版本的词汇一致性来量化PDF到文本转换的保真度。在LEMUR的基础上,我们使用单语和双语环境中的对比目标微调了三个最先进的多语言嵌入模型,反映了真实的法律检索场景。跨低资源和高资源语言的实验表明,相对于强大的基线,法律领域微调始终提高Top-k检索准确率,对于低资源语言的提升尤为显著。跨语言评估表明,这些改进可以转移到未见过的语言,表明微调主要增强了语言独立的内容级别法律表示,而不是特定于语言的线索。我们发布了代码和数据。
🔬 方法详解
问题定义:论文旨在解决多语言法律领域信息检索中,现有方法依赖的语料库质量不高,且缺乏领域自适应的嵌入模型的问题。现有方法主要面临两个痛点:一是现有的多语言法律语料库并非专门为语义检索设计,二是PDF文档转换成文本时会引入噪声,影响检索效果。
核心思路:论文的核心思路是构建一个高质量的多语言法律语料库LEMUR,并在此基础上微调现有的多语言嵌入模型,使其更好地适应法律领域的语义表示。通过对比学习,模型能够学习到更鲁棒的、语言无关的法律概念表示,从而提升跨语言检索的性能。
技术框架:整体框架包括数据构建和模型微调两个主要阶段。数据构建阶段,从EUR-Lex收集PDF文档,并转换为文本,同时使用HTML版本进行质量评估。模型微调阶段,选择三种先进的多语言嵌入模型,使用LEMUR语料库进行对比学习微调,分别在单语和双语环境下进行。
关键创新:论文的关键创新在于构建了大规模、高质量的多语言法律语料库LEMUR,并证明了在法律领域进行微调可以显著提升多语言嵌入模型的检索性能,尤其是在低资源语言上。此外,论文还发现微调后的模型能够学习到语言无关的法律概念表示,从而提升跨语言检索能力。
关键设计:论文使用了Lexical Content Score (LCS) 来评估PDF到文本转换的质量。在模型微调方面,采用了对比学习的目标函数,鼓励模型学习到相似法律文本的相近表示。具体而言,使用了InfoNCE损失函数,将正样本对的相似度最大化,负样本对的相似度最小化。实验中,选择了三种多语言嵌入模型,并针对不同的语言组合进行了微调。
🖼️ 关键图片
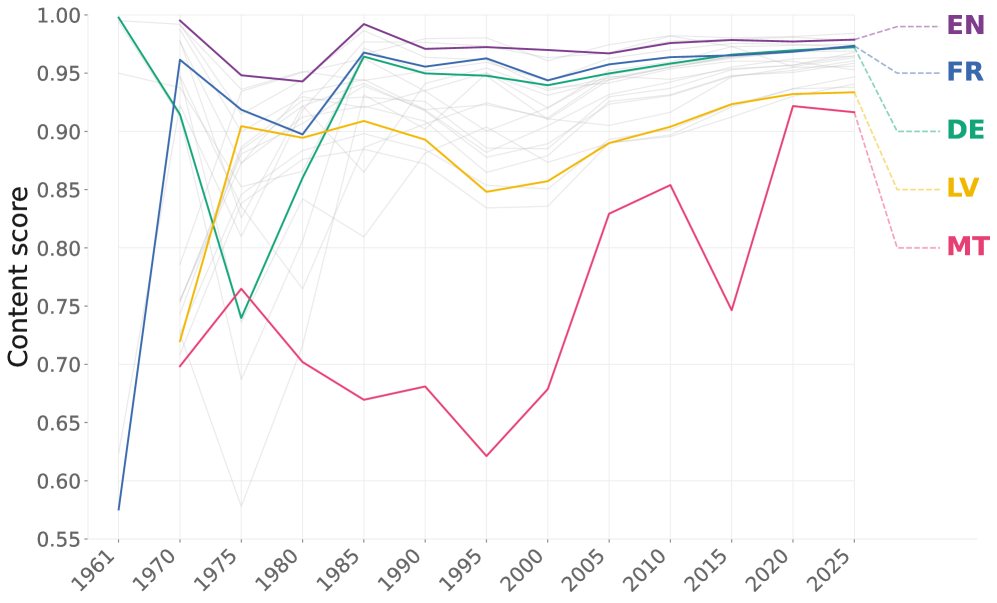


📊 实验亮点
实验结果表明,在LEMUR语料库上微调的多语言嵌入模型,在Top-k检索准确率上显著优于基线模型,尤其是在低资源语言上提升更为明显。跨语言评估也显示,微调后的模型能够有效提升跨语言检索性能,表明其学习到了语言无关的法律概念表示。
🎯 应用场景
该研究成果可应用于多语言法律信息检索系统,帮助法律从业者和研究人员更高效地查找和理解不同语言的法律法规。此外,该方法也可推广到其他专业领域的多语言信息检索,例如医学、金融等,具有重要的实际应用价值和未来发展潜力。
📄 摘要(原文)
Large language models (LLMs) are increasingly used to access legal information. Yet, their deployment in multilingual legal settings is constrained by unreliable retrieval and the lack of domain-adapted, open-embedding models. In particular, existing multilingual legal corpora are not designed for semantic retrieval, and PDF-based legislative sources introduce substantial noise due to imperfect text extraction. To address these challenges, we introduce LEMUR, a large-scale multilingual corpus of EU environmental legislation constructed from 24,953 official EUR-Lex PDF documents covering 25 languages. We quantify the fidelity of PDF-to-text conversion by measuring lexical consistency against authoritative HTML versions using the Lexical Content Score (LCS). Building on LEMUR, we fine-tune three state-of-the-art multilingual embedding models using contrastive objectives in both monolingual and bilingual settings, reflecting realistic legal-retrieval scenarios. Experiments across low- and high-resource languages demonstrate that legal-domain fine-tuning consistently improves Top-k retrieval accuracy relative to strong baselines, with particularly pronounced gains for low-resource languages. Cross-lingual evaluations show that these improvements transfer to unseen languages, indicating that fine-tuning primarily enhances language-independent, content-level legal representations rather than language-specific cues. We publish code\footnote{\href{https://github.com/nargesbh/eur_lex}{GitHub Repository}} and data\footnote{\href{https://huggingface.co/datasets/G4KMU/LEMUR}{Hugging Face Dataset}}.