Knowledge Integration Decay in Search-Augmented Reasoning of Large Language Models
作者: Sangwon Yu, Ik-hwan Kim, Donghun Kang, Bongkyu Hwang, Junhwa Choi, Suk-hoon Jung, Seungki Hong, Taehee Lee, Sungroh Yoon
分类: cs.CL
发布日期: 2026-02-10
💡 一句话要点
提出SAKE策略,解决LLM搜索增强推理中知识整合衰减问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 知识整合 搜索增强推理 知识衰减 自锚定知识编码
📋 核心要点
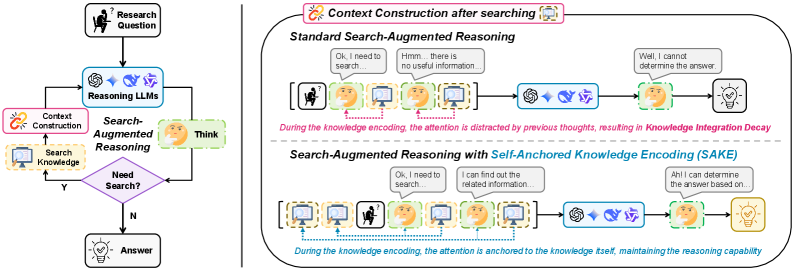
- 现有LLM在搜索增强推理中存在知识整合衰减(KID)问题,即推理链越长,检索知识越难被有效利用。
- 论文提出自锚定知识编码(SAKE)策略,通过在推理过程首尾锚定检索知识,防止其被上下文掩盖。
- 实验表明,SAKE能显著缓解KID,并在多跳问答和复杂推理任务中提升LLM的性能表现。
📝 摘要(中文)
大型语言模型(LLM)通过搜索增强推理,将外部知识融入长链思维,在复杂任务中展现了卓越能力。然而,我们发现这种范式中存在一个关键但未被充分探索的瓶颈,即知识整合衰减(KID)。具体而言,我们观察到,随着搜索前生成的推理长度增加,模型越来越难以将检索到的证据整合到后续的推理步骤中,即使在有相关信息的情况下也会限制性能。为了解决这个问题,我们提出了一种无需训练的推理时策略,称为自锚定知识编码(SAKE),旨在稳定知识利用。通过将检索到的知识锚定在推理过程的开始和结束位置,SAKE可以防止知识被先前的上下文所掩盖,从而保持其语义完整性。在多跳问答和复杂推理基准上的大量实验表明,SAKE显著减轻了KID并提高了性能,为agentic LLM中的知识整合提供了一种轻量级但有效的解决方案。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在搜索增强推理过程中出现的知识整合衰减(KID)问题。现有方法在长推理链中,模型难以有效利用检索到的外部知识,导致性能下降。痛点在于,随着推理步骤的增加,早期检索到的知识容易被后续的上下文信息所稀释或覆盖,从而影响最终的推理结果。
核心思路:论文的核心思路是通过在推理过程的开始和结束位置“锚定”检索到的知识,来增强模型对这些知识的关注和利用。这种方法类似于在阅读长篇文章时,读者会反复回顾关键信息以确保理解和记忆。通过在推理的起始和结束阶段都显式地包含检索到的知识,可以有效地防止知识被遗忘或忽略。
技术框架:SAKE (Self-Anchored Knowledge Encoding) 是一种推理时策略,不需要额外的训练。其主要流程如下:1. 正常进行LLM的推理,直到需要检索外部知识。2. 使用检索模块获取相关知识。3. 将检索到的知识分别插入到当前推理上下文的开头和结尾,形成新的输入上下文。4. 使用修改后的上下文继续进行推理。通过这种方式,检索到的知识在推理过程中被“锚定”在两个关键位置,从而增强其影响力。
关键创新:SAKE的关键创新在于其简单而有效的知识锚定机制。与需要重新训练模型或修改模型结构的复杂方法不同,SAKE是一种无需训练的推理时策略,易于实现和部署。它通过在推理过程中显式地强调检索到的知识,有效地解决了知识整合衰减问题。
关键设计:SAKE的关键设计在于如何将检索到的知识有效地融入到推理上下文中。具体来说,论文中将检索到的知识以自然语言的形式添加到推理上下文的开头和结尾。这种设计避免了对模型结构的修改,并且可以很容易地与其他知识检索和推理方法相结合。没有提及具体的参数设置或损失函数,因为 SAKE 是一种推理时策略,不涉及模型训练。
🖼️ 关键图片


📊 实验亮点
实验结果表明,SAKE策略在多跳问答和复杂推理基准测试中显著提高了LLM的性能。例如,在某些任务上,SAKE能够将准确率提升超过5%,证明了其在缓解知识整合衰减方面的有效性。SAKE作为一种无需训练的推理时策略,其轻量级和易于部署的特点使其更具吸引力。
🎯 应用场景
该研究成果可广泛应用于需要利用外部知识进行复杂推理的场景,例如智能问答系统、对话机器人、知识图谱推理、以及需要长期记忆和推理能力的agentic LLM。通过缓解知识整合衰减问题,可以提升这些应用在处理复杂任务时的准确性和可靠性,具有重要的实际应用价值。
📄 摘要(原文)
Modern Large Language Models (LLMs) have demonstrated remarkable capabilities in complex tasks by employing search-augmented reasoning to incorporate external knowledge into long chains of thought. However, we identify a critical yet underexplored bottleneck in this paradigm, termed Knowledge Integration Decay (KID). Specifically, we observe that as the length of reasoning generated before search grows, models increasingly fail to integrate retrieved evidence into subsequent reasoning steps, limiting performance even when relevant information is available. To address this, we propose Self-Anchored Knowledge Encoding (SAKE), a training-free inference-time strategy designed to stabilize knowledge utilization. By anchoring retrieved knowledge at both the beginning and end of the reasoning process, SAKE prevents it from being overshadowed by prior context, thereby preserving its semantic integrity. Extensive experiments on multi-hop QA and complex reasoning benchmarks demonstrate that SAKE significantly mitigates KID and improves performance, offering a lightweight yet effective solution for knowledge integration in agentic LLMs.