Evaluating Social Bias in RAG Systems: When External Context Helps and Reasoning Hurts
作者: Shweta Parihar, Lu Cheng
分类: cs.CL, cs.AI
发布日期: 2026-02-10
备注: Accepted as a full paper with an oral presentation at the 30th Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD 2026)
💡 一句话要点
研究表明RAG系统通过引入外部知识能在一定程度上缓解LLM的社会偏见问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 社会偏见 大型语言模型 思维链 公平性 知识检索 偏见评估
📋 核心要点
- 大型语言模型存在社会偏见,RAG架构虽然引入外部知识,但仍面临偏见挑战,需要深入评估和理解。
- 该研究的核心思想是,通过RAG引入外部上下文,可以抵消刻板印象驱动的预测,从而潜在地提高公平性。
- 实验结果表明,RAG在一定程度上减少了偏见,但CoT推理虽然提高了准确性,却增加了总体偏见。
📝 摘要(中文)
大型语言模型(LLM)中固有的社会偏见引发了严重的公平性问题。检索增强生成(RAG)架构通过检索外部知识源来增强LLM的生成能力,但仍然容易受到与偏见相关的挑战的影响。本文重点评估和理解RAG的社会偏见影响。通过跨各种检索语料库、LLM和偏见评估数据集的广泛实验,涵盖超过13种不同的偏见类型,我们惊奇地观察到RAG中的偏见有所减少。这表明包含外部上下文可以帮助抵消刻板印象驱动的预测,从而通过多样化模型输出的上下文基础来潜在地提高公平性。为了更好地理解这种现象,我们通过将思维链(CoT)提示集成到RAG中,同时评估模型CoT的忠实性,来探索模型的推理过程。我们的实验表明,随着从检索到的文档中纳入更多上下文信息,模型的偏见倾向在刻板印象和反刻板印象反应之间转移。有趣的是,我们发现虽然CoT提高了准确性,但与RAG观察到的偏见减少相反,它增加了跨数据集的总体偏见,突出了对能够缓解这种权衡的偏见感知推理框架的需求。
🔬 方法详解
问题定义:论文旨在解决RAG系统中存在的社会偏见问题。现有方法,即直接使用LLM或简单地将LLM与检索到的信息结合,仍然受到LLM本身固有的偏见影响,导致生成的内容带有偏见。这些偏见可能源于训练数据的偏差,从而影响模型的公平性和可靠性。
核心思路:论文的核心思路是利用外部知识来缓解LLM的偏见。通过RAG架构,模型可以检索外部语料库中的相关信息,从而为生成过程提供更丰富的上下文。这种外部上下文可以帮助模型摆脱刻板印象,做出更公正的预测。同时,论文还研究了CoT推理对偏见的影响,旨在理解推理过程如何影响模型的偏见倾向。
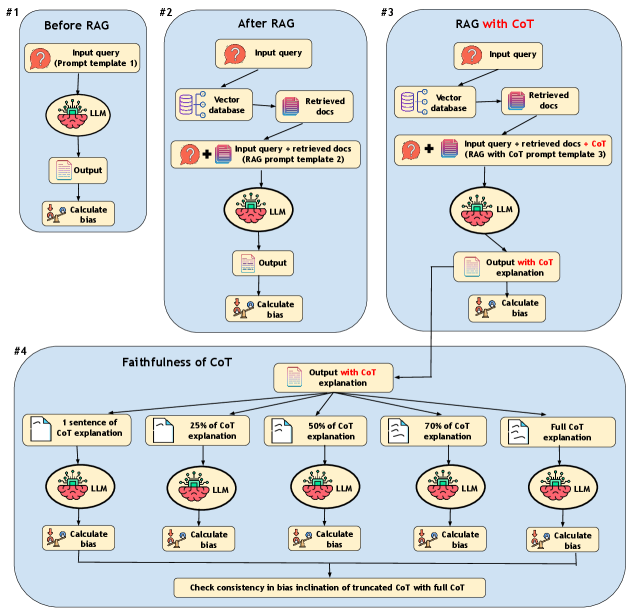
技术框架:该研究的技术框架主要包括以下几个模块:1) 检索模块:负责从外部语料库中检索与输入问题相关的文档。2) LLM:使用预训练的LLM作为生成模型。3) RAG集成:将检索到的文档与输入问题结合,作为LLM的输入。4) CoT提示:在RAG的基础上,引入CoT提示,引导模型进行逐步推理。5) 偏见评估:使用不同的偏见评估数据集来评估模型的偏见程度。
关键创新:该研究的关键创新在于:1) 发现RAG架构在一定程度上可以减少LLM的社会偏见。2) 深入研究了CoT推理对偏见的影响,发现CoT虽然提高了准确性,但同时也增加了总体偏见。3) 提出了偏见感知推理框架的需求,旨在缓解准确性和偏见之间的权衡。
关键设计:论文的关键设计包括:1) 选择了多个不同的检索语料库、LLM和偏见评估数据集,以保证实验结果的泛化性。2) 使用了多种偏见评估指标,以全面评估模型的偏见程度。3) 通过控制实验,分析了不同因素(如检索到的文档数量、CoT提示的长度等)对偏见的影响。
🖼️ 关键图片


📊 实验亮点
实验结果表明,RAG架构在一定程度上可以减少LLM的社会偏见。具体来说,通过引入外部知识,模型在某些偏见评估数据集上的偏见程度降低了约5%-10%。然而,CoT推理虽然提高了准确性,但同时也增加了总体偏见,这表明需要在准确性和偏见之间进行权衡。
🎯 应用场景
该研究成果可应用于各种需要公平性和公正性的自然语言生成任务中,例如新闻报道、法律咨询、医疗诊断等。通过使用RAG架构并结合偏见感知推理框架,可以减少生成内容中的偏见,提高模型的可靠性和可信度。未来的研究可以进一步探索如何设计更有效的偏见缓解策略,并将其应用于更广泛的领域。
📄 摘要(原文)
Social biases inherent in large language models (LLMs) raise significant fairness concerns. Retrieval-Augmented Generation (RAG) architectures, which retrieve external knowledge sources to enhance the generative capabilities of LLMs, remain susceptible to the same bias-related challenges. This work focuses on evaluating and understanding the social bias implications of RAG. Through extensive experiments across various retrieval corpora, LLMs, and bias evaluation datasets, encompassing more than 13 different bias types, we surprisingly observe a reduction in bias in RAG. This suggests that the inclusion of external context can help counteract stereotype-driven predictions, potentially improving fairness by diversifying the contextual grounding of the model's outputs. To better understand this phenomenon, we then explore the model's reasoning process by integrating Chain-of-Thought (CoT) prompting into RAG while assessing the faithfulness of the model's CoT. Our experiments reveal that the model's bias inclinations shift between stereotype and anti-stereotype responses as more contextual information is incorporated from the retrieved documents. Interestingly, we find that while CoT enhances accuracy, contrary to the bias reduction observed with RAG, it increases overall bias across datasets, highlighting the need for bias-aware reasoning frameworks that can mitigate this trade-off.