AgentSkiller: Scaling Generalist Agent Intelligence through Semantically Integrated Cross-Domain Data Synthesis
作者: Zexu Sun, Bokai Ji, Hengyi Cai, Shuaiqiang Wang, Lei Wang, Guangxia Li, Xu Chen
分类: cs.CL
发布日期: 2026-02-10
备注: 33 pages, 9 figures
💡 一句话要点
AgentSkiller:通过语义集成跨领域数据合成扩展通用智能体能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 通用智能体 数据合成 跨领域学习 函数调用 自动化框架
📋 核心要点
- 现有方法在收集高质量、长程智能体交互数据方面存在不足,API日志受隐私限制,脚本交互缺乏多样性。
- AgentSkiller通过全自动框架,合成跨多个语义链接领域的交互数据,利用DAG架构保证确定性和可恢复性。
- 实验表明,使用AgentSkiller合成的数据训练的模型,在函数调用任务上显著优于基线模型,尤其是在大参数规模下。
📝 摘要(中文)
大型语言模型智能体在通过工具解决现实世界问题方面展现出潜力,但通用智能受到高质量、长程数据稀缺的限制。现有方法收集受隐私约束的API日志或生成缺乏多样性的脚本交互,难以产生扩展能力所需的数据。我们提出了AgentSkiller,一个全自动框架,用于合成跨现实、语义链接领域的多轮交互数据。它采用基于DAG的架构,具有显式状态转换,以确保确定性和可恢复性。该流程构建领域本体和以人为中心的实体图,通过模型上下文协议服务器的服务蓝图定义工具接口,并使用一致的数据库和严格的领域策略填充环境。跨领域融合机制链接服务以模拟复杂任务。最后,该流程通过验证解决方案路径、通过基于执行的验证进行过滤以及使用基于角色的模拟器生成查询来创建用户任务,以实现自动部署。这产生了具有清晰状态变化的可靠环境。为了证明有效性,我们合成了约11K个交互样本;实验结果表明,在此数据集上训练的模型在函数调用方面比基线有了显着改进,尤其是在更大的参数范围内。
🔬 方法详解
问题定义:论文旨在解决通用智能体训练数据稀缺的问题,特别是高质量、长程交互数据的不足。现有方法,如收集API日志或生成脚本交互,存在隐私限制和多样性不足的缺陷,难以有效提升智能体的通用能力。
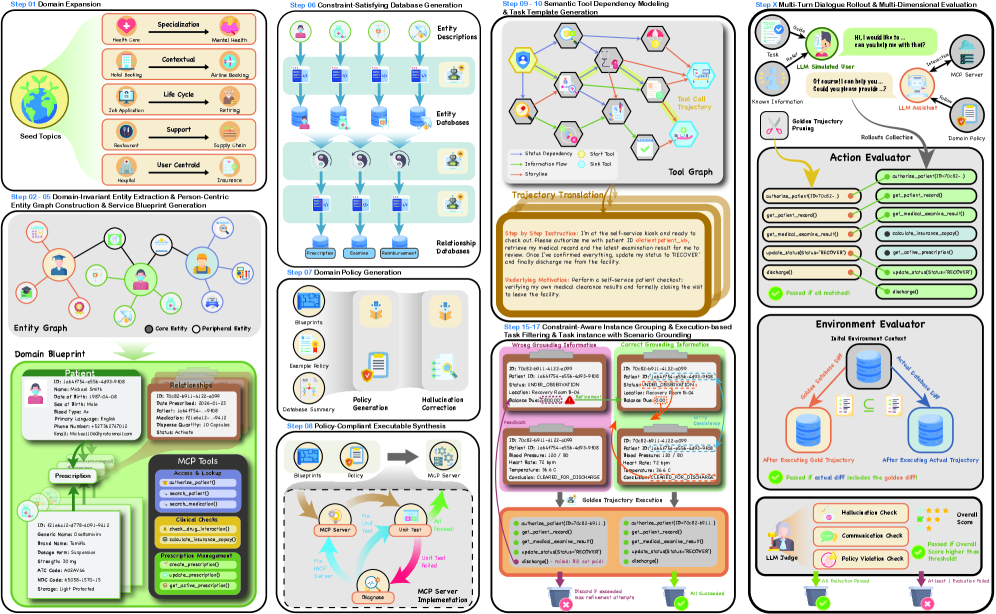
核心思路:AgentSkiller的核心思路是利用全自动化的数据合成框架,模拟真实世界中跨多个领域的复杂交互场景。通过构建领域本体、实体图和服务蓝图,AgentSkiller能够生成具有语义一致性、状态可追踪和可恢复性的多轮对话数据,从而为智能体提供更丰富的训练样本。
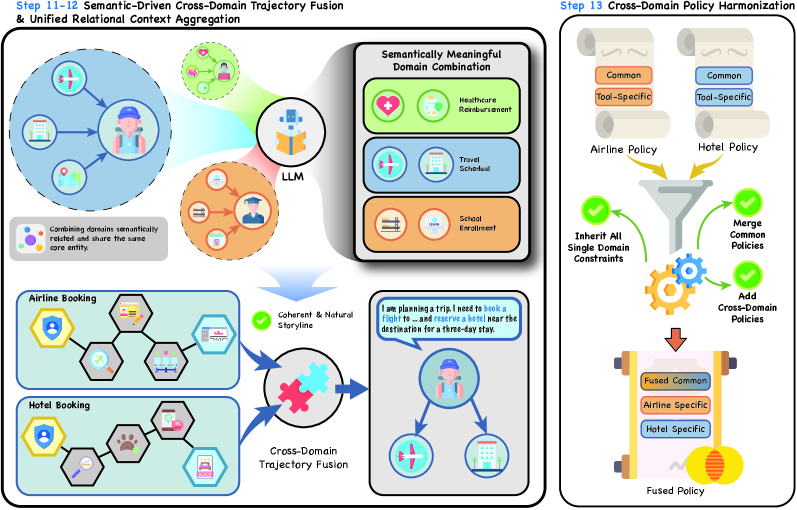
技术框架:AgentSkiller的整体架构是一个基于DAG(有向无环图)的流程,包含以下主要模块:1) 领域本体构建:构建领域知识图谱,定义实体、关系和属性。2) 实体图构建:构建以人为中心的实体图,模拟用户行为和偏好。3) 服务蓝图定义:定义工具接口,描述工具的功能和使用方式。4) 环境填充:使用一致的数据库和领域策略填充模拟环境。5) 跨领域融合:链接不同领域的服务,模拟复杂任务。6) 任务生成:验证解决方案路径,过滤无效任务,并使用基于角色的模拟器生成用户查询。
关键创新:AgentSkiller的关键创新在于其全自动化的数据合成流程和跨领域融合机制。与现有方法相比,AgentSkiller无需人工干预,能够高效地生成大规模、高质量的交互数据。跨领域融合机制使得智能体能够学习处理更复杂的任务,提升其通用能力。
关键设计:AgentSkiller的关键设计包括:1) 基于DAG的架构,保证状态转换的确定性和可恢复性。2) 领域本体和实体图的构建,确保数据的语义一致性。3) 服务蓝图的定义,规范工具的使用方式。4) 基于执行的验证,过滤无效任务。5) 基于角色的模拟器,生成更真实的用户查询。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用AgentSkiller合成的约11K个交互样本训练的模型,在函数调用任务上取得了显著的性能提升。与基线模型相比,AgentSkiller训练的模型在不同参数规模下均表现出更强的函数调用能力,尤其是在大参数规模下,提升更为明显。这验证了AgentSkiller在提升通用智能体能力方面的有效性。
🎯 应用场景
AgentSkiller可应用于各种需要通用智能体的场景,例如智能助手、自动化客服、任务型对话系统等。通过提供高质量的训练数据,AgentSkiller能够提升智能体的任务完成能力、泛化能力和鲁棒性,从而在实际应用中发挥更大的价值。未来,AgentSkiller可以扩展到更多领域,支持更复杂的任务,并与其他技术(如强化学习、迁移学习)相结合,进一步提升智能体的性能。
📄 摘要(原文)
Large Language Model agents demonstrate potential in solving real-world problems via tools, yet generalist intelligence is bottlenecked by scarce high-quality, long-horizon data. Existing methods collect privacy-constrained API logs or generate scripted interactions lacking diversity, which struggle to produce data requisite for scaling capabilities. We propose AgentSkiller, a fully automated framework synthesizing multi-turn interaction data across realistic, semantically linked domains. It employs a DAG-based architecture with explicit state transitions to ensure determinism and recoverability. The pipeline builds a domain ontology and Person-Centric Entity Graph, defines tool interfaces via Service Blueprints for Model Context Protocol servers, and populates environments with consistent databases and strict Domain Policies. A cross-domain fusion mechanism links services to simulate complex tasks. Finally, the pipeline creates user tasks by verifying solution paths, filtering via execution-based validation, and generating queries using a Persona-based Simulator for automated rollout. This produces reliable environments with clear state changes. To demonstrate effectiveness, we synthesized $\approx$ 11K interaction samples; experimental results indicate that models trained on this dataset achieve significant improvements on function calling over baselines, particularly in larger parameter regimes.