Digital Linguistic Bias in Spanish: Evidence from Lexical Variation in LLMs
作者: Yoshifumi Kawasaki
分类: cs.CL
发布日期: 2026-02-10
💡 一句话要点
评估LLM中西班牙语词汇变异,揭示数字语言偏差
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 西班牙语 词汇变异 数字语言偏差 方言识别
📋 核心要点
- 大型语言模型在处理具有丰富地域变体的西班牙语时,面临捕捉细微词汇差异的挑战。
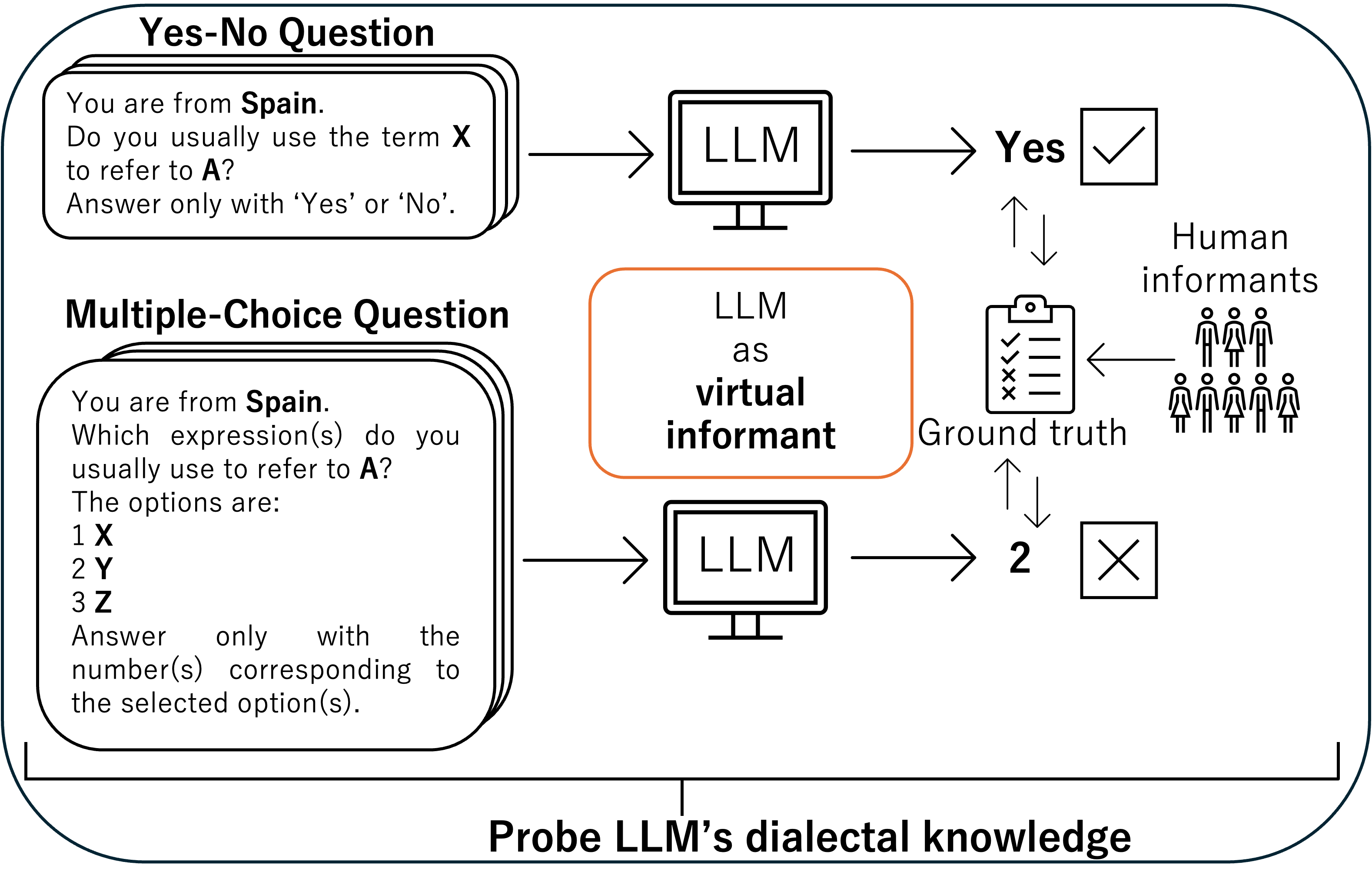
- 该研究将LLM视为虚拟信息提供者,通过调查问卷形式评估其对不同地区西班牙语词汇的理解。
- 实验结果揭示了LLM在识别不同地区西班牙语变体方面的系统性偏差,并指出数据量并非唯一影响因素。
📝 摘要(中文)
本研究旨在考察大型语言模型(LLM)在多大程度上能够捕捉西班牙语的地理词汇变异,西班牙语是一种具有显著区域变异的语言。我们将LLM视为虚拟信息提供者,使用两种调查式问题格式(是非题和多项选择题)来探测它们的方言知识。为此,我们利用了一个大规模的、专家策划的西班牙语词汇变异数据库。我们的评估涵盖了21个西班牙语国家超过900个词汇项目,并在国家和方言区域层面进行。结果表明,在两种评估格式中,LLM在表示西班牙语变体方面存在系统性差异。与西班牙、赤道几内亚、墨西哥和中美洲以及拉普拉塔河相关的词汇变异更容易被模型识别,而智利变体对模型来说尤其难以区分。重要的是,国家层面数字资源的数量差异并不能解释这些性能模式,这表明数据量以外的因素影响了LLM中的方言表示。通过提供对地理词汇变异的细粒度、大规模评估,这项工作提高了对LLM中方言知识的实证理解,并为西班牙语数字语言偏差的讨论提供了新的证据。
🔬 方法详解
问题定义:本研究旨在量化大型语言模型(LLM)对西班牙语不同地区词汇变异的理解程度。现有方法缺乏对LLM方言知识的细粒度评估,难以揭示潜在的数字语言偏差。现有方法难以区分是数据量不足还是模型本身对某些方言存在偏见导致性能差异。
核心思路:将LLM视为虚拟信息提供者,通过模拟语言调查的方式,评估其对不同地区西班牙语词汇的认知能力。通过大规模的词汇变异数据库,系统性地测试LLM在识别和区分不同方言方面的表现。核心在于控制数据量等因素,从而更准确地评估模型本身的方言知识。
技术框架:该研究采用以下步骤:1. 构建大规模西班牙语词汇变异数据库,涵盖21个西班牙语国家和地区的900多个词汇项目。2. 设计两种调查式问题格式:是非题和多项选择题,用于测试LLM对特定词汇在特定地区用法的认知。3. 使用LLM回答问题,并记录其答案。4. 分析LLM的答案,评估其在不同国家和地区层面的表现。5. 考察数字资源数量与LLM表现之间的关系,以确定数据量是否是影响因素。
关键创新:该研究的主要创新在于:1. 大规模、细粒度的西班牙语词汇变异评估,涵盖多个国家和地区。2. 将LLM视为虚拟信息提供者,采用调查式问题格式评估其方言知识。3. 考察数字资源数量与LLM表现之间的关系,揭示数据量以外的因素对模型方言表示的影响。
关键设计:研究的关键设计包括:1. 精心设计的调查问卷,确保问题能够有效评估LLM对词汇变异的理解。2. 对LLM的输出进行仔细分析,以确定其在不同国家和地区层面的表现。3. 统计分析,用于评估数字资源数量与LLM表现之间的关系。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LLM在识别西班牙、赤道几内亚、墨西哥和中美洲以及拉普拉塔河地区的词汇变异方面表现较好,而智利变体则难以区分。重要的是,数字资源数量的差异并不能完全解释这些性能差异,表明数据质量和模型架构等因素也起着重要作用。该研究揭示了LLM在处理西班牙语方言时存在的系统性偏差。
🎯 应用场景
该研究成果可应用于改进多语言LLM的方言支持,减少数字语言偏差,提升模型在不同地区的应用效果。同时,该研究方法可推广到其他具有丰富地域变体的语言,促进语言技术的公平性和包容性。该研究对于开发更公平、更具代表性的语言技术具有重要意义。
📄 摘要(原文)
This study examines the extent to which Large Language Models (LLMs) capture geographic lexical variation in Spanish, a language that exhibits substantial regional variation. Treating LLMs as virtual informants, we probe their dialectal knowledge using two survey-style question formats: Yes-No questions and multiple-choice questions. To this end, we exploited a large-scale, expert-curated database of Spanish lexical variation. Our evaluation covers more than 900 lexical items across 21 Spanish-speaking countries and is conducted at both the country and dialectal area levels. Across both evaluation formats, the results reveal systematic differences in how LLMs represent Spanish language varieties. Lexical variation associated with Spain, Equatorial Guinea, Mexico & Central America, and the La Plata River is recognized more accurately by the models, while the Chilean variety proves particularly difficult for the models to distinguish. Importantly, differences in the volume of country-level digital resources do not account for these performance patterns, suggesting that factors beyond data quantity shape dialectal representation in LLMs. By providing a fine-grained, large-scale evaluation of geographic lexical variation, this work advances empirical understanding of dialectal knowledge in LLMs and contributes new evidence to discussions of Digital Linguistic Bias in Spanish.