Beyond Transcripts: A Renewed Perspective on Audio Chaptering
作者: Fabian Retkowski, Maike Züfle, Thai Binh Nguyen, Jan Niehues, Alexander Waibel
分类: cs.SD, cs.CL
发布日期: 2026-02-09
💡 一句话要点
提出AudioSeg,一种基于音频表示的章节分割方法,显著优于文本方法。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音频章节分割 音频表示学习 无文本分割 自监督学习 长音频理解
📋 核心要点
- 现有音频章节分割研究主要依赖文本转录,忽略了音频本身的信息,且易受ASR错误影响。
- 提出AudioSeg,一种直接在学习到的音频表示上操作的音频章节分割架构,无需文本转录。
- 实验表明,AudioSeg在YTSeg数据集上显著优于基于文本的方法,尤其是在利用停顿等声学特征时。
📝 摘要(中文)
音频章节分割,即将长音频自动分割成连贯的片段,对于浏览播客、讲座和视频至关重要。尽管其重要性日益增加,但相关研究仍然有限且主要集中于文本,关于如何利用音频信息、处理ASR错误以及进行无文本评估的关键问题仍未解决。本文通过三个方面的贡献来弥补这些差距:(1)系统地比较了基于文本的模型与声学特征、一种新颖的仅音频架构(AudioSeg,基于学习到的音频表示)以及多模态LLM;(2)实证分析了影响性能的因素,包括转录质量、声学特征、持续时间和说话人构成;(3)形式化了评估协议,对比了依赖于转录的文本空间协议与转录不变的时间空间协议。在YTSeg上的实验表明,AudioSeg显著优于基于文本的方法,停顿提供了最大的声学增益,MLLM受到上下文长度和弱指令遵循的限制,但在较短的音频上表现出潜力。
🔬 方法详解
问题定义:音频章节分割旨在将长音频分割成语义连贯的片段。现有方法主要依赖自动语音识别(ASR)生成的文本转录,这使得它们容易受到ASR错误的影响,并且无法充分利用音频本身的信息。此外,缺乏无需文本转录的评估协议,限制了对纯音频方法的探索。
核心思路:本文的核心思路是直接利用音频信息进行章节分割,避免依赖文本转录。通过学习音频的表示,并在此基础上进行分割,可以更有效地利用音频的声学特征,并减少对ASR质量的依赖。AudioSeg架构旨在捕捉音频中的语义变化,从而实现准确的章节分割。
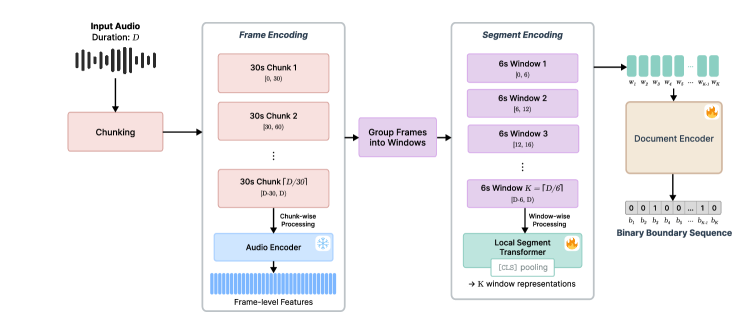
技术框架:AudioSeg架构包含以下主要模块:1) 音频特征提取:使用预训练的音频模型(如HuBERT或Wav2Vec 2.0)提取音频的表示。2) 特征聚合:将提取的音频特征进行聚合,以获得每个时间步的上下文信息。3) 分割预测:使用一个分类器(如MLP或Transformer)预测每个时间步是否为章节边界。4) 后处理:对预测结果进行平滑处理,以获得最终的章节分割结果。
关键创新:最重要的技术创新点是AudioSeg架构本身,它是一种端到端的音频章节分割模型,可以直接在学习到的音频表示上操作,无需文本转录。与现有方法相比,AudioSeg能够更有效地利用音频的声学特征,并减少对ASR质量的依赖。此外,本文还提出了转录不变的时间空间评估协议,为评估纯音频方法提供了新的标准。
关键设计:AudioSeg的关键设计包括:1) 使用预训练的音频模型提取音频特征,以利用大规模无监督数据进行预训练的优势。2) 使用Transformer进行特征聚合,以捕捉音频中的长程依赖关系。3) 使用交叉熵损失函数训练分割预测器。4) 通过调整后处理中的平滑窗口大小来控制分割的粒度。
🖼️ 关键图片

📊 实验亮点
实验结果表明,AudioSeg在YTSeg数据集上显著优于基于文本的方法。具体而言,AudioSeg在F1-score上取得了明显的提升,尤其是在利用停顿等声学特征时。此外,实验还表明,多模态LLM在短音频上表现出潜力,但在长音频上受到上下文长度的限制。
🎯 应用场景
该研究成果可广泛应用于播客、讲座、会议录音等长音频内容的自动章节分割,提升用户浏览和检索效率。无需依赖高质量的文本转录,降低了应用成本,尤其适用于低资源语言或语音识别效果不佳的场景。未来可进一步应用于智能语音助手、音频内容推荐等领域。
📄 摘要(原文)
Audio chaptering, the task of automatically segmenting long-form audio into coherent sections, is increasingly important for navigating podcasts, lectures, and videos. Despite its relevance, research remains limited and text-based, leaving key questions unresolved about leveraging audio information, handling ASR errors, and transcript-free evaluation. We address these gaps through three contributions: (1) a systematic comparison between text-based models with acoustic features, a novel audio-only architecture (AudioSeg) operating on learned audio representations, and multimodal LLMs; (2) empirical analysis of factors affecting performance, including transcript quality, acoustic features, duration, and speaker composition; and (3) formalized evaluation protocols contrasting transcript-dependent text-space protocols with transcript-invariant time-space protocols. Our experiments on YTSeg reveal that AudioSeg substantially outperforms text-based approaches, pauses provide the largest acoustic gains, and MLLMs remain limited by context length and weak instruction following, yet MLLMs are promising on shorter audio.