Large Language Models for Geolocation Extraction in Humanitarian Crisis Response
作者: G. Cafferata, T. Demarco, K. Kalimeri, Y. Mejova, M. G. Beiró
分类: cs.CL, cs.IR
发布日期: 2026-02-09
💡 一句话要点
提出基于大语言模型的地理定位提取框架,提升人道主义危机响应中文本地理信息提取的精度和公平性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 地理位置提取 人道主义危机响应 命名实体识别 地理编码 公平性 少量样本学习
📋 核心要点
- 现有地理位置提取系统存在地理和社会经济偏见,导致危机地区可见性不均,影响人道主义响应的公平性。
- 提出一个两步框架,结合少量样本学习的LLM命名实体识别和基于Agent的地理编码,利用上下文消除地名歧义。
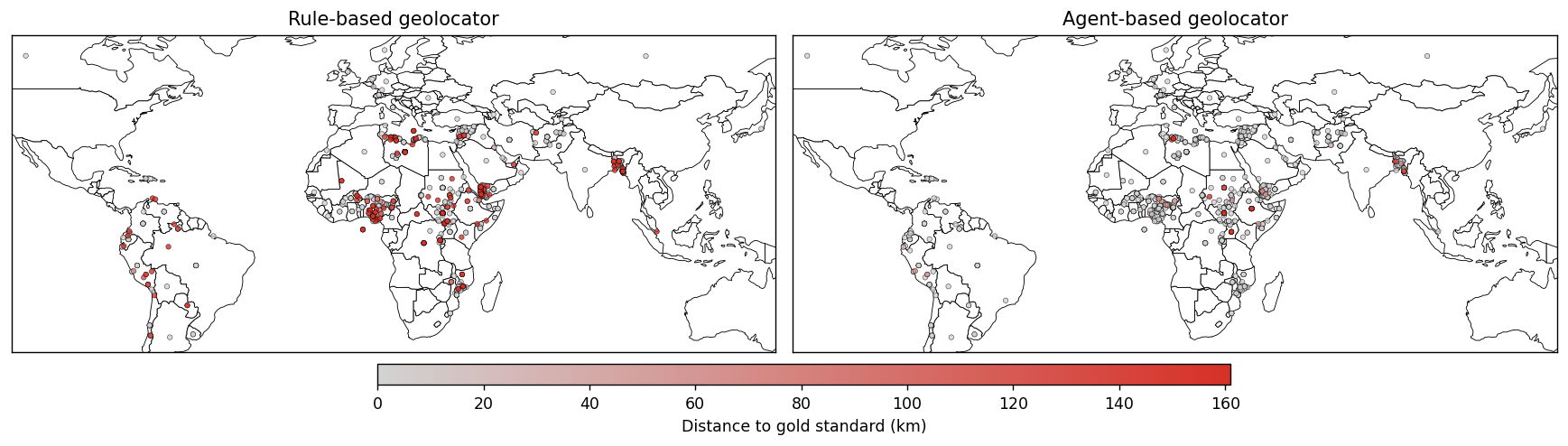
- 实验表明,该方法显著提高了人道主义文本中地理位置提取的精度和公平性,尤其是在代表性不足的地区。
📝 摘要(中文)
人道主义危机需要及时准确的地理信息来支持有效的响应工作。然而,现有的自动文本地理位置提取系统常常复制已有的地理和社会经济偏见,导致受危机影响地区的可见性不均。本文研究了大型语言模型(LLMs)是否能够解决在人道主义文件中提取位置信息时存在的这些地理差异。我们引入了一个两步框架,该框架结合了基于少量样本学习的LLM命名实体识别和一个基于Agent的地理编码模块,该模块利用上下文来解决歧义地名。我们使用准确性和跨地理和社会经济维度的公平性指标,将我们的方法与最先进的预训练和基于规则的系统进行基准测试。我们的评估使用了HumSet数据集的扩展版本,其中包含改进的字面地名注释。结果表明,基于LLM的方法显着提高了人道主义文本中地理位置提取的精度和公平性,尤其是在代表性不足的地区。通过将LLM推理的进步与负责任和包容性AI的原则相结合,这项工作有助于为应对人道主义危机建立更公平的地理空间数据系统,从而推进在危机分析中不遗漏任何地方的目标。
🔬 方法详解
问题定义:论文旨在解决人道主义危机响应中,从文本中提取地理位置信息时存在的地理和社会经济偏见问题。现有方法在提取地理位置时,容易受到训练数据分布的影响,导致对一些欠发达或关注度低的地区的信息提取效果较差,从而影响人道主义援助的公平分配。
核心思路:论文的核心思路是利用大型语言模型(LLMs)强大的上下文理解和推理能力,结合地理编码技术,来提高地理位置提取的精度和公平性。LLMs能够更好地理解文本中的上下文信息,从而更准确地识别和解析地名,尤其是在地名存在歧义的情况下。
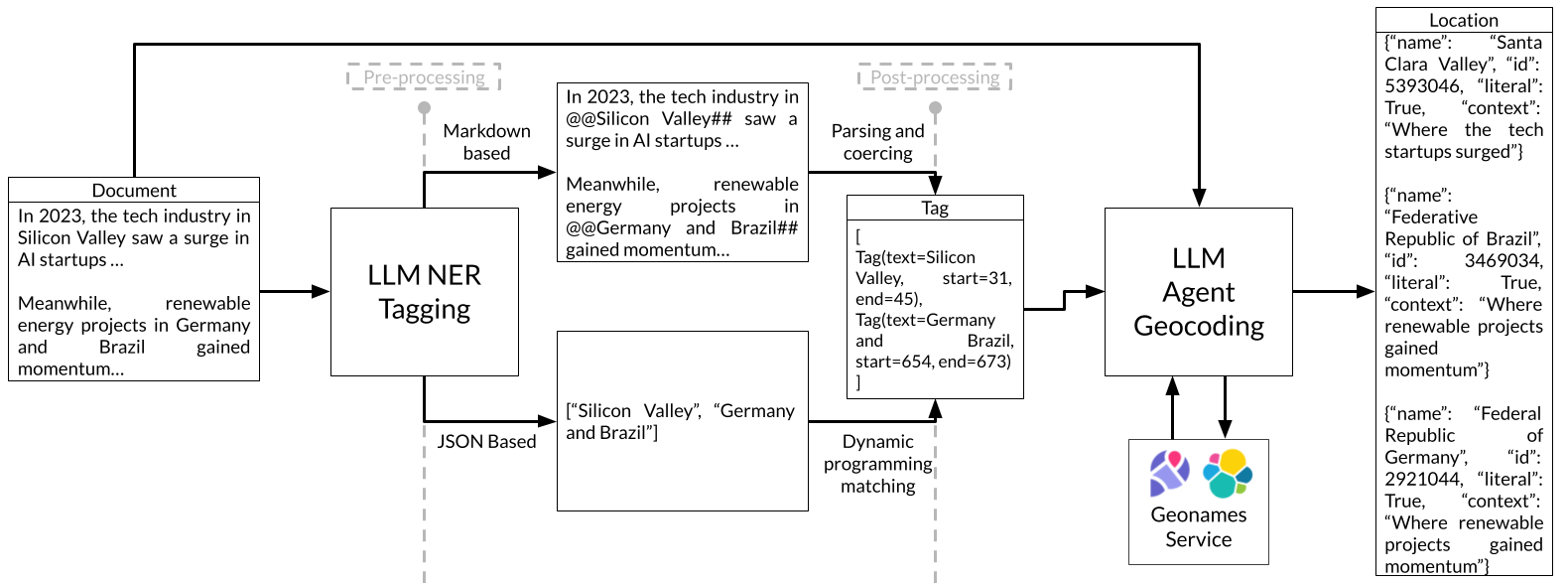
技术框架:该方法采用两步框架:第一步是基于少量样本学习的LLM命名实体识别(NER),用于从文本中识别出潜在的地理位置名称。第二步是基于Agent的地理编码模块,该模块利用上下文信息来消除地名歧义,并将识别出的地名映射到具体的地理坐标。该模块通过模拟智能Agent的行为,根据上下文线索推断最可能的地理位置。
关键创新:该方法的关键创新在于将LLMs的上下文理解能力与地理编码技术相结合,从而显著提高了地理位置提取的精度和公平性。与传统的基于规则或预训练模型的NER方法相比,LLMs能够更好地理解文本的语义信息,从而更准确地识别和解析地名。此外,基于Agent的地理编码模块能够有效地消除地名歧义,提高地理位置提取的准确性。
关键设计:在LLM命名实体识别阶段,采用了少量样本学习策略,即只使用少量的标注数据来训练LLM,从而降低了标注成本。在基于Agent的地理编码模块中,设计了多个Agent,每个Agent负责处理不同类型的上下文信息,例如,地理位置的层级关系、周边地名等。这些Agent通过协作来推断最可能的地理位置。
🖼️ 关键图片
📊 实验亮点
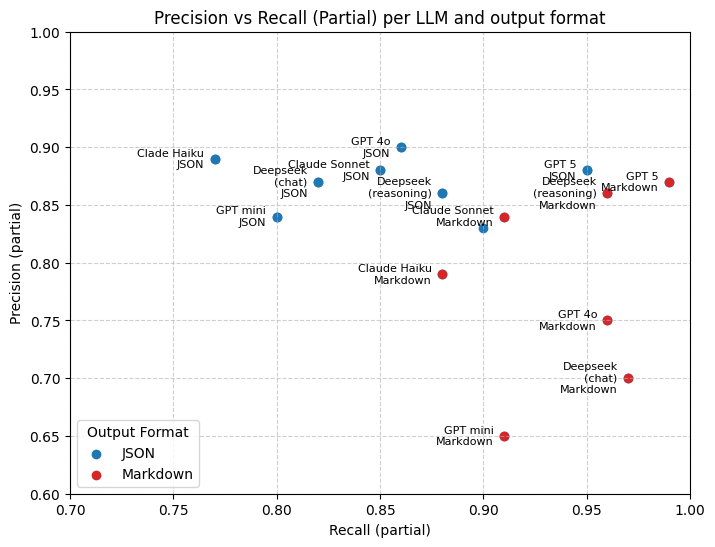
实验结果表明,基于LLM的方法在地理位置提取的精度和公平性方面均优于现有的方法。具体而言,该方法在HumSet数据集的扩展版本上取得了显著的性能提升,尤其是在代表性不足的地区,其精度和公平性指标均得到了大幅改善。与传统的预训练模型和基于规则的系统相比,该方法能够更准确地识别和解析地名,从而提高了地理位置提取的整体性能。
🎯 应用场景
该研究成果可应用于人道主义危机响应、灾害管理、公共卫生监测等领域。通过提高地理位置提取的精度和公平性,可以帮助人道主义组织更有效地分配资源,更好地服务于受危机影响的地区,最终实现“不遗漏任何地方”的目标。未来,该技术还可以扩展到其他语言和领域,例如,商业智能、市场分析等。
📄 摘要(原文)
Humanitarian crises demand timely and accurate geographic information to inform effective response efforts. Yet, automated systems that extract locations from text often reproduce existing geographic and socioeconomic biases, leading to uneven visibility of crisis-affected regions. This paper investigates whether Large Language Models (LLMs) can address these geographic disparities in extracting location information from humanitarian documents. We introduce a two-step framework that combines few-shot LLM-based named entity recognition with an agent-based geocoding module that leverages context to resolve ambiguous toponyms. We benchmark our approach against state-of-the-art pretrained and rule-based systems using both accuracy and fairness metrics across geographic and socioeconomic dimensions. Our evaluation uses an extended version of the HumSet dataset with refined literal toponym annotations. Results show that LLM-based methods substantially improve both the precision and fairness of geolocation extraction from humanitarian texts, particularly for underrepresented regions. By bridging advances in LLM reasoning with principles of responsible and inclusive AI, this work contributes to more equitable geospatial data systems for humanitarian response, advancing the goal of leaving no place behind in crisis analytics.