WildReward: Learning Reward Models from In-the-Wild Human Interactions
作者: Hao Peng, Yunjia Qi, Xiaozhi Wang, Zijun Yao, Lei Hou, Juanzi Li
分类: cs.CL, cs.AI
发布日期: 2026-02-09
🔗 代码/项目: GITHUB
💡 一句话要点
WildReward:从真实用户交互中学习奖励模型,提升LLM性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 奖励模型 大型语言模型 用户交互 序数回归 在线DPO 用户反馈 WildChat
📋 核心要点
- 现有奖励模型依赖人工标注偏好对,成本高昂且难以捕捉真实用户反馈。
- 提出WildReward,直接从真实用户交互中学习奖励模型,无需人工标注偏好对。
- 实验表明,WildReward性能与传统奖励模型相当甚至更优,并能有效提升在线DPO训练效果。
📝 摘要(中文)
奖励模型(RMs)对于训练大型语言模型(LLMs)至关重要,但通常依赖于大规模的人工标注偏好对。随着LLMs的广泛部署,真实场景中的用户交互成为隐式奖励信号的丰富来源。本文探讨了直接从真实交互中开发奖励模型的可能性。通过采用WildChat作为交互来源,并提出一个提取可靠用户反馈的流程,生成了18.6万个高质量实例,用于通过序数回归直接在用户反馈上训练WildReward,无需偏好对。大量实验表明,WildReward与传统奖励模型相比,实现了相当甚至更优越的性能,并具有改进的校准和跨样本一致性。我们还观察到,WildReward直接受益于用户多样性,更多用户产生更强大的奖励模型。最后,我们将WildReward应用于在线DPO训练,并在各种任务中观察到显著改进。代码和数据已发布在https://github.com/THU-KEG/WildReward。
🔬 方法详解
问题定义:现有奖励模型的训练依赖于大量人工标注的偏好对数据,这不仅成本高昂,而且难以捕捉到真实世界用户交互中的细微偏好。此外,人工标注可能引入偏差,限制了奖励模型的泛化能力。因此,如何利用真实世界用户交互数据,构建更有效、更鲁棒的奖励模型是一个重要的挑战。
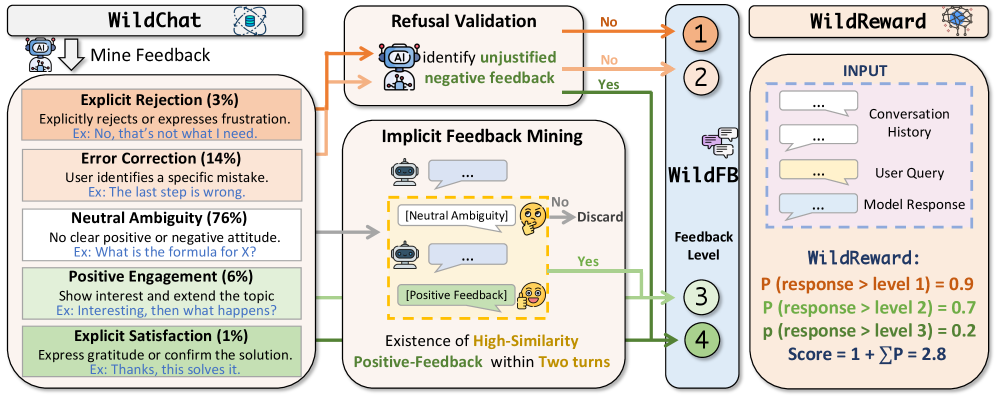
核心思路:WildReward的核心思路是直接从真实的用户交互数据中提取奖励信号,避免人工标注的偏好对。通过分析用户对LLM回复的反馈(例如点赞、评论等),将其转化为序数回归问题,从而训练奖励模型。这种方法能够更真实地反映用户的偏好,并降低标注成本。
技术框架:WildReward的整体框架包括以下几个主要步骤:1) 数据收集:从WildChat等真实用户交互平台收集用户反馈数据。2) 数据清洗与预处理:对收集到的数据进行清洗,去除噪声和无效信息。3) 奖励信号提取:将用户反馈转化为序数回归的标签。例如,点赞可以视为更高的奖励,而差评则视为更低的奖励。4) 模型训练:使用序数回归方法训练奖励模型,目标是预测给定LLM回复的奖励值。5) 模型评估:使用各种指标评估奖励模型的性能,例如校准度、跨样本一致性等。
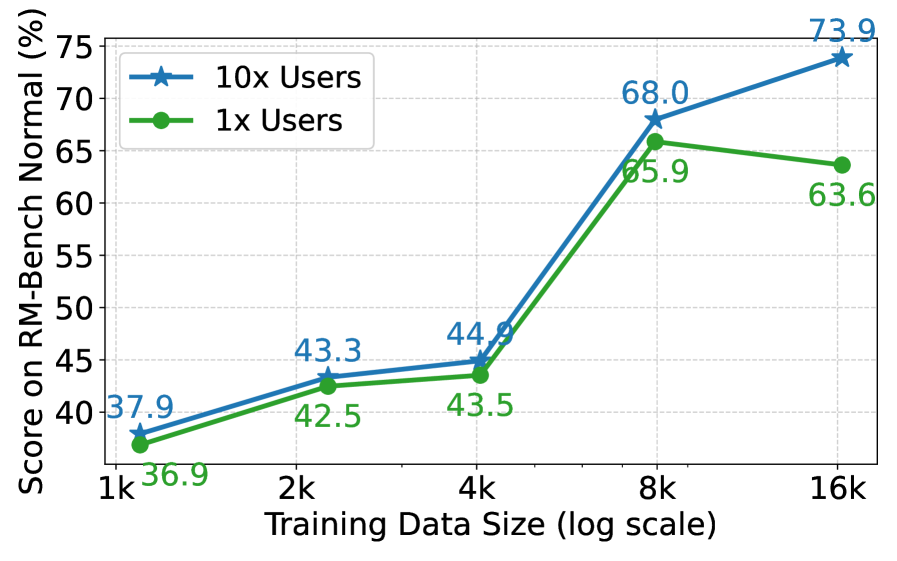
关键创新:WildReward最重要的创新点在于它直接从真实用户交互中学习奖励模型,无需人工标注的偏好对。这与传统的奖励模型训练方法有本质区别。此外,WildReward还利用了用户多样性,通过更多用户的反馈来提升奖励模型的性能。
关键设计:WildReward的关键设计包括:1) 序数回归损失函数:使用序数回归损失函数来训练奖励模型,以更好地处理用户反馈的序数关系。2) 用户多样性利用:通过对不同用户的反馈进行加权,来利用用户多样性,提升奖励模型的泛化能力。3) 在线DPO训练:将WildReward应用于在线DPO训练,以进一步提升LLM的性能。
🖼️ 关键图片

📊 实验亮点
WildReward在实验中表现出与传统奖励模型相当甚至更优越的性能。例如,在校准度和跨样本一致性方面,WildReward均优于传统模型。此外,实验还表明,WildReward能够有效利用用户多样性,更多用户的反馈能够显著提升奖励模型的性能。将WildReward应用于在线DPO训练后,在各种任务中观察到显著的性能提升。
🎯 应用场景
WildReward可广泛应用于各种需要奖励模型的大型语言模型训练场景,例如对话系统、文本生成、代码生成等。通过利用真实用户交互数据,可以构建更符合用户需求的LLM,提升用户体验。此外,该方法还可以降低奖励模型的训练成本,加速LLM的开发和部署。
📄 摘要(原文)
Reward models (RMs) are crucial for the training of large language models (LLMs), yet they typically rely on large-scale human-annotated preference pairs. With the widespread deployment of LLMs, in-the-wild interactions have emerged as a rich source of implicit reward signals. This raises the question: Can we develop reward models directly from in-the-wild interactions? In this work, we explore this possibility by adopting WildChat as an interaction source and proposing a pipeline to extract reliable human feedback, yielding 186k high-quality instances for training WildReward via ordinal regression directly on user feedback without preference pairs. Extensive experiments demonstrate that WildReward achieves comparable or even superior performance compared to conventional reward models, with improved calibration and cross-sample consistency. We also observe that WildReward benefits directly from user diversity, where more users yield stronger reward models. Finally, we apply WildReward to online DPO training and observe significant improvements across various tasks. Code and data are released at https://github.com/THU-KEG/WildReward.