Learning to Judge: LLMs Designing and Applying Evaluation Rubrics
作者: Clemencia Siro, Pourya Aliannejadi, Mohammad Aliannejadi
分类: cs.CL, cs.LG
发布日期: 2026-02-09
备注: Accepted at EACL 2026 Findings
💡 一句话要点
GER-Eval:探索LLM自主设计评估准则并应用于自然语言生成任务评估
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 自然语言生成 自动评估 评估准则 模型评估
📋 核心要点
- 现有NLG评估依赖人工定义的静态准则,与LLM内部的语言质量表征存在偏差,限制了评估的准确性和有效性。
- GER-Eval探索LLM自主设计评估准则的可能性,旨在使评估过程更贴合模型特性,提升评估的内在一致性。
- 实验表明,LLM能生成可解释的任务感知评估维度,但在知识密集型任务中评分可靠性下降,闭源模型表现更优。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地被用作自然语言生成(NLG)的评估器,应用人为定义的准则来评估系统输出。然而,人为准则通常是静态的,并且与模型内部表示语言质量的方式不一致。我们引入了GER-Eval(生成评估准则用于评估),以研究LLM是否可以设计和应用自己的评估准则。我们评估了LLM定义的标准的语义连贯性和评分可靠性,以及它们与人类标准的对齐程度。LLM能够可靠地生成可解释且任务感知的评估维度,并在模型内部一致地应用它们,但它们的评分可靠性在事实和知识密集型设置中会降低。像GPT-4o这样的闭源模型比像Llama这样的开源模型实现了更高的一致性和跨模型泛化。我们的研究结果将评估定位为LLM的一种学习到的语言能力,在模型内部是一致的,但在模型之间是分散的,并呼吁新的方法来共同建模人类和LLM的评估语言,以提高可靠性和可解释性。
🔬 方法详解
问题定义:论文旨在解决现有自然语言生成(NLG)评估方法中,人工定义的评估准则与大型语言模型(LLMs)内部的语言质量表征不一致的问题。现有方法的痛点在于,人工准则往往是静态的,难以捕捉LLMs对语言质量的细微理解,导致评估结果可能不准确或不全面。
核心思路:论文的核心思路是让LLMs自主设计和应用评估准则。通过赋予LLMs生成评估维度的能力,使其能够根据自身对语言的理解来评估NLG系统的输出,从而提高评估的内在一致性和准确性。这种方法旨在弥合人工准则与LLMs内部语言表征之间的差距。
技术框架:GER-Eval框架包含两个主要阶段:准则生成阶段和评估应用阶段。在准则生成阶段,LLM被提示生成一系列评估维度,这些维度应该能够反映NLG系统输出的质量。在评估应用阶段,LLM使用生成的评估维度来对NLG系统输出进行评分。整个流程旨在模拟人类评估的过程,但使用LLM自主生成的准则。
关键创新:该论文的关键创新在于提出了让LLM自主设计评估准则的概念。与传统的依赖人工准则的方法不同,GER-Eval允许LLM根据自身对语言的理解来定义评估标准,从而更贴合模型特性。这种方法有望提高评估的内在一致性和准确性。与现有方法的本质区别在于,评估准则的来源从人工变成了LLM自身。
关键设计:论文的关键设计包括:1) 使用特定的prompt工程来引导LLM生成有意义的评估维度;2) 设计实验来评估LLM生成的评估维度的语义连贯性、评分可靠性以及与人类标准的对齐程度;3) 比较不同LLM(包括闭源和开源模型)在GER-Eval框架下的表现,以分析模型特性对评估结果的影响。具体的参数设置、损失函数、网络结构等技术细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片

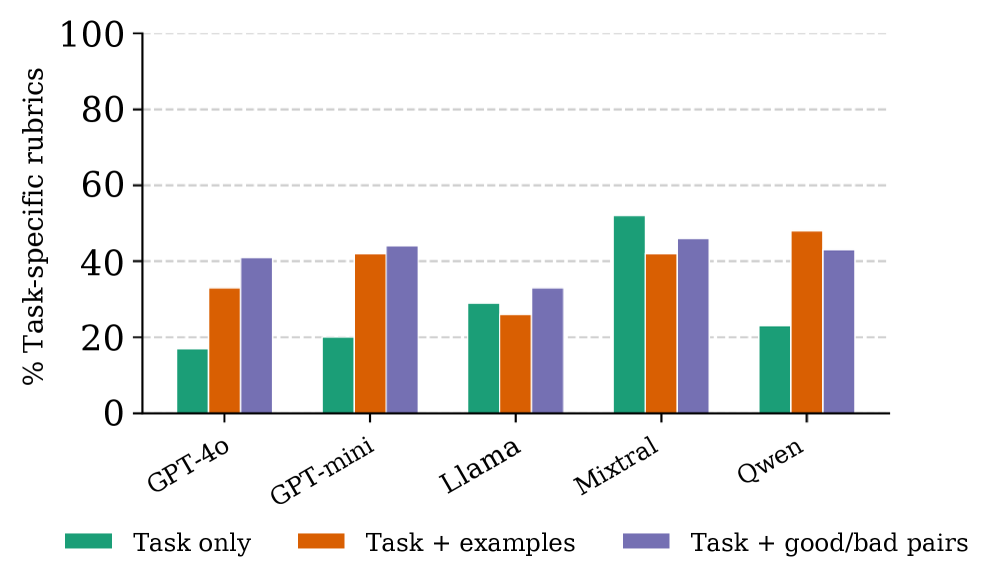

📊 实验亮点
实验结果表明,LLM能够可靠地生成可解释且任务感知的评估维度,并在模型内部一致地应用它们。然而,在事实和知识密集型设置中,LLM的评分可靠性会降低。闭源模型(如GPT-4o)比开源模型(如Llama)实现了更高的一致性和跨模型泛化能力。这些发现突出了LLM在评估任务中的潜力和局限性。
🎯 应用场景
该研究成果可应用于各种自然语言生成任务的自动评估,例如机器翻译、文本摘要、对话生成等。通过使用LLM自主设计的评估准则,可以更准确地评估NLG系统的性能,并为模型训练提供更有效的反馈。此外,该研究还有助于理解LLM的语言理解能力和评估偏好,为开发更可靠和可解释的AI系统提供 insights。
📄 摘要(原文)
Large language models (LLMs) are increasingly used as evaluators for natural language generation, applying human-defined rubrics to assess system outputs. However, human rubrics are often static and misaligned with how models internally represent language quality. We introduce GER-Eval (Generating Evaluation Rubrics for Evaluation) to investigate whether LLMs can design and apply their own evaluation rubrics. We evaluate the semantic coherence and scoring reliability of LLM-defined criteria and their alignment with human criteria. LLMs reliably generate interpretable and task-aware evaluation dimensions and apply them consistently within models, but their scoring reliability degrades in factual and knowledge-intensive settings. Closed-source models such as GPT-4o achieve higher agreement and cross-model generalization than open-weight models such as Llama. Our findings position evaluation as a learned linguistic capability of LLMs, consistent within models but fragmented across them, and call for new methods that jointly model human and LLM evaluative language to improve reliability and interpretability.