VocalNet-MDM: Accelerating Streaming Speech LLM via Self-Distilled Masked Diffusion Modeling
作者: Ziyang Cheng, Yuhao Wang, Heyang Liu, Ronghua Wu, Qunshan Gu, Yanfeng Wang, Yu Wang
分类: cs.CL, cs.SD
发布日期: 2026-02-09
💡 一句话要点
VocalNet-MDM:通过自蒸馏掩码扩散模型加速流式语音LLM
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音大语言模型 掩码扩散模型 流式语音交互 自蒸馏 低延迟 非自回归生成 语音合成 分层掩码
📋 核心要点
- 现有的语音LLM采用自回归范式,存在生成效率低和暴露偏差的问题,限制了其在流式语音交互中的应用。
- VocalNet-MDM利用掩码扩散模型,通过分层块状掩码和迭代自蒸馏,解决了训练-推理不匹配和迭代开销的问题。
- 实验结果表明,VocalNet-MDM在解码速度、首块延迟、文本质量和语音自然度方面均优于自回归基线。
📝 摘要(中文)
本文研究了掩码扩散模型(MDM)作为语音大语言模型(LLM)的一种非自回归范式,并提出了VocalNet-MDM。为了使MDM适应流式语音交互,我们解决了两个关键挑战:训练-推理不匹配和迭代开销。我们提出了分层块状掩码,使训练目标与块扩散解码期间遇到的渐进式掩码状态对齐;以及迭代自蒸馏,将多步细化压缩为更少的步骤,以实现低延迟推理。VocalNet-MDM仅在6K小时的语音数据上训练,与自回归基线相比,实现了3.7倍-10倍的解码速度提升,并将首块延迟降低了34%。它在保持具有竞争力的识别精度的同时,实现了最先进的文本质量和语音自然度,表明MDM是一种有前景且可扩展的替代方案,适用于低延迟、高效的语音LLM。
🔬 方法详解
问题定义:现有语音大语言模型(LLM)主要采用自回归(AR)范式,这种范式存在固有的串行依赖性,导致生成效率低下,难以满足流式语音交互的低延迟需求。此外,自回归模型在训练和推理过程中存在暴露偏差,影响模型的泛化能力。
核心思路:本文的核心思路是利用掩码扩散模型(MDM)的非自回归特性,打破串行依赖,实现并行生成,从而提高生成效率。同时,通过特殊的设计来解决MDM在流式语音交互中遇到的训练-推理不匹配和迭代开销问题。
技术框架:VocalNet-MDM的整体框架包含训练和推理两个阶段。在训练阶段,使用分层块状掩码策略,使模型学习在不同粒度的掩码状态下进行语音生成。在推理阶段,采用迭代自蒸馏技术,将多步扩散过程压缩为更少的步骤,以降低延迟。整体流程包括语音编码、掩码扩散建模、解码和语音合成等模块。
关键创新:本文的关键创新在于将掩码扩散模型应用于流式语音LLM,并提出了分层块状掩码和迭代自蒸馏两种技术。分层块状掩码解决了训练和推理之间的不一致性,而迭代自蒸馏则显著降低了推理延迟。与传统的自回归模型相比,VocalNet-MDM实现了并行生成,提高了效率。
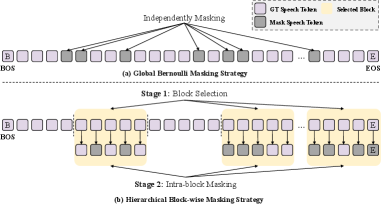
关键设计:分层块状掩码策略将语音特征划分为多个块,并根据不同的比例随机掩码这些块,从而模拟推理过程中逐步解码的状态。迭代自蒸馏通过训练一个快速的单步模型来逼近多步扩散过程,从而减少推理所需的迭代次数。损失函数包括重建损失、掩码预测损失和蒸馏损失等,用于优化模型的生成质量和效率。
🖼️ 关键图片


📊 实验亮点
VocalNet-MDM在仅使用6K小时语音数据训练的情况下,与自回归基线相比,实现了3.7倍-10倍的解码速度提升,并将首块延迟降低了34%。同时,在保持具有竞争力的识别精度的前提下,实现了最先进的文本质量和语音自然度。这些结果表明,MDM是一种有前景的语音LLM替代方案。
🎯 应用场景
VocalNet-MDM在智能助手、实时语音翻译、语音聊天机器人等领域具有广泛的应用前景。其低延迟和高效率的特性使其能够更好地支持实时语音交互,提升用户体验。未来,该技术有望应用于更多需要快速响应和自然语音生成的场景,例如车载语音控制、智能家居等。
📄 摘要(原文)
Recent Speech Large Language Models~(LLMs) have achieved impressive capabilities in end-to-end speech interaction. However, the prevailing autoregressive paradigm imposes strict serial constraints, limiting generation efficiency and introducing exposure bias. In this paper, we investigate Masked Diffusion Modeling~(MDM) as a non-autoregressive paradigm for speech LLMs and introduce VocalNet-MDM. To adapt MDM for streaming speech interaction, we address two critical challenges: training-inference mismatch and iterative overhead. We propose Hierarchical Block-wise Masking to align training objectives with the progressive masked states encountered during block diffusion decoding, and Iterative Self-Distillation to compress multi-step refinement into fewer steps for low-latency inference. Trained on a limited scale of only 6K hours of speech data, VocalNet-MDM achieves a 3.7$\times$--10$\times$ decoding speedup and reduces first-chunk latency by 34\% compared to AR baselines. It maintains competitive recognition accuracy while achieving state-of-the-art text quality and speech naturalness, demonstrating that MDM is a promising and scalable alternative for low-latency, efficient speech LLMs.