Beyond Scalar Scores: Reinforcement Learning for Error-Aware Quality Estimation of Machine Translation
作者: Archchana Sindhujan, Girish A. Koushik, Shenbin Qian, Diptesh Kanojia, Constantin Orăsan
分类: cs.CL
发布日期: 2026-02-09
备注: Currently this article is under review for Natural Language Processing Journal
💡 一句话要点
提出ALOPE-RL框架,利用强化学习和错误感知奖励提升机器翻译质量估计
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器翻译质量估计 强化学习 低资源语言 错误感知奖励 翻译质量评语
📋 核心要点
- 现有机器翻译质量估计方法主要依赖标量分数,缺乏对翻译错误的明确信息,限制了其性能和可解释性。
- 提出ALOPE-RL框架,利用强化学习,结合直接评估分数和翻译质量评语,训练LLM进行更细粒度的质量估计。
- 实验表明,ALOPE-RL在低资源语言翻译质量估计上取得了SOTA性能,超越了更大的LLM和传统编码器模型。
📝 摘要(中文)
本文旨在解决机器翻译质量估计(QE)中仅依赖标量质量分数,缺乏翻译错误显式信息的问题,尤其是在低资源语言场景下。为此,我们构建了首个英语到马拉雅拉姆语的段落级QE数据集,包含人工标注的直接评估(DA)分数和翻译质量评语(TQR),即描述翻译错误的简短自由文本。此外,我们提出了ALOPE-RL,一个基于策略的强化学习框架,利用DA分数和TQR推导的策略奖励训练高效适配器。通过整合错误感知的奖励,ALOPE-RL使LLM能够超越数值分数进行翻译质量推理。即使在小规模QE数据集上训练,ALOPE-RL在使用LoRA和4-bit量化微调的紧凑型LLM(<=4B参数)下,也能在英语到马拉雅拉姆语QE上实现最先进的性能,优于更大的基于LLM的基线和领先的基于编码器的QE模型。结果表明,在有限的数据和计算预算下,错误感知的基于策略的学习可以提供强大的QE性能。我们发布了数据集、代码和训练模型,以支持未来的研究。
🔬 方法详解
问题定义:现有的机器翻译质量估计(QE)方法主要依赖于标量质量得分,忽略了翻译中存在的具体错误信息。这种方法的痛点在于,它无法提供关于翻译质量的细粒度理解,限制了模型在低资源语言环境下的泛化能力,并且难以指导翻译系统的改进。
核心思路:本文的核心思路是利用强化学习,结合人工标注的翻译质量评语(TQR)和直接评估(DA)分数,训练LLM学习翻译质量的细粒度特征。通过将TQR作为奖励信号,引导模型关注翻译中的错误,从而提升质量估计的准确性和可解释性。
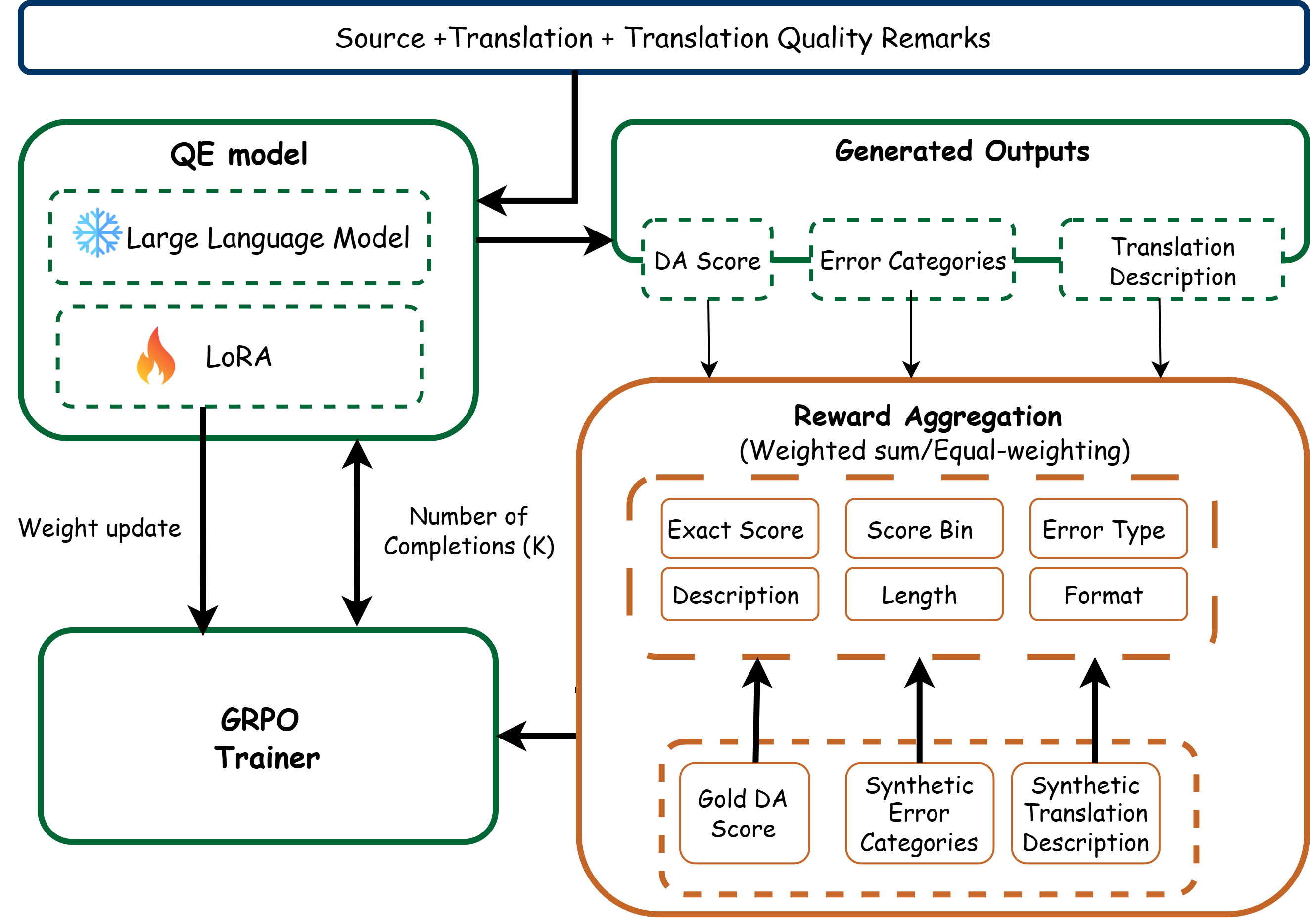
技术框架:ALOPE-RL框架包含以下主要模块:1) 数据集构建:构建包含DA分数和TQR的英语到马拉雅拉姆语QE数据集。2) 奖励函数设计:基于DA分数和TQR设计奖励函数,鼓励模型生成高质量的翻译。3) 策略学习:使用强化学习算法(例如,策略梯度)训练LLM,使其能够根据输入文本生成翻译,并根据奖励函数调整策略。4) 模型微调:使用LoRA和4-bit量化技术微调LLM,以降低计算成本。
关键创新:最重要的技术创新点在于将翻译质量评语(TQR)融入到强化学习的奖励函数中。与传统的仅依赖标量分数的奖励函数相比,TQR提供了关于翻译错误的更丰富信息,使模型能够更准确地评估翻译质量。此外,该方法在低资源语言环境下表现出色,证明了其在数据稀缺场景下的有效性。
关键设计:奖励函数的设计是关键。论文中,奖励函数综合考虑了DA分数和TQR。DA分数提供整体质量评估,而TQR则用于识别和惩罚翻译错误。具体来说,可以设计一个函数,当模型生成的翻译与TQR中描述的错误一致时,给予负向奖励。此外,使用LoRA进行参数高效微调,并采用4-bit量化来降低模型大小和计算成本。
🖼️ 关键图片

📊 实验亮点
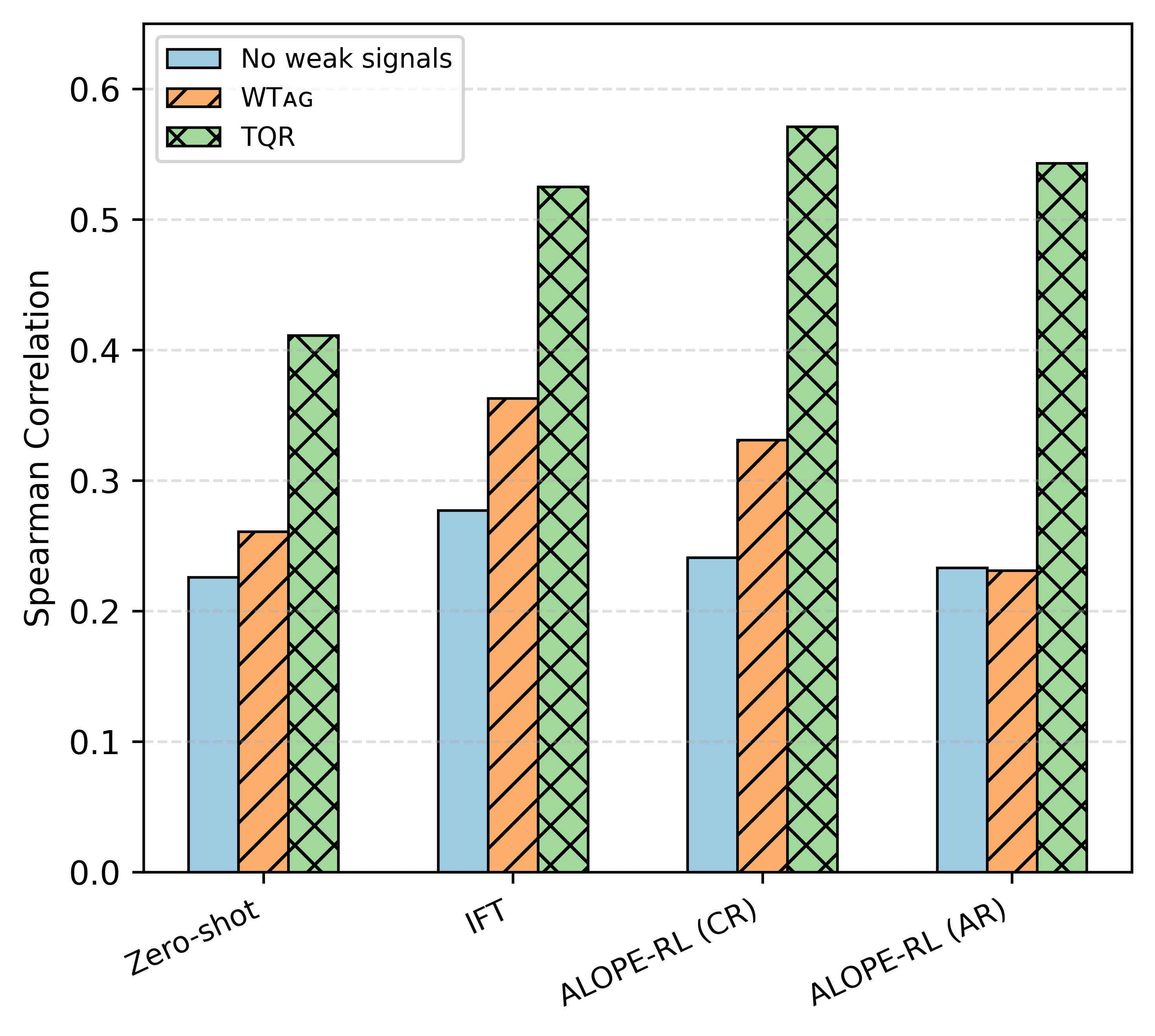
ALOPE-RL在英语到马拉雅拉姆语的翻译质量估计任务上取得了state-of-the-art的性能,即使使用参数量小于等于4B的紧凑型LLM,也超越了更大的LLM基线和领先的基于编码器的QE模型。这表明错误感知的策略学习在有限的数据和计算资源下,能够显著提升翻译质量估计的准确性。
🎯 应用场景
该研究成果可应用于机器翻译系统的自动评估和改进,尤其是在低资源语言场景下。通过提供细粒度的质量估计和错误分析,可以帮助开发者更好地理解翻译系统的不足,并针对性地进行优化。此外,该方法还可以用于构建更智能的翻译辅助工具,为用户提供更准确、更可靠的翻译结果。
📄 摘要(原文)
Quality Estimation (QE) aims to assess the quality of machine translation (MT) outputs without relying on reference translations, making it essential for real-world, large-scale MT evaluation. Large Language Models (LLMs) have shown significant promise in advancing the field of quality estimation of machine translation. However, most of the QE approaches solely rely on scalar quality scores, offering no explicit information about the translation errors that should drive these judgments. Moreover, for low-resource languages where annotated QE data is limited, existing approaches struggle to achieve reliable performance. To address these challenges, we introduce the first segment-level QE dataset for English to Malayalam, a severely resource-scarce language pair in the QE domain, comprising human-annotated Direct Assessment (DA) scores and Translation Quality Remarks (TQR), which are short, contextual, free-form annotator comments that describe translation errors. We further introduce ALOPE-RL, a policy-based reinforcement learning framework that trains efficient adapters based on policy rewards derived from DA score and TQR. Integrating error-aware rewards with ALOPE-RL, enables LLMs to reason about translation quality beyond numeric scores. Despite being trained on a small-scale QE dataset, ALOPE-RL achieves state-of-the-art performance on English to Malayalam QE using compact LLMs (<=4B parameters}) fine-tuned with LoRA and 4-bit quantization, outperforming both larger LLM-based baselines and leading encoder-based QE models. Our results demonstrate that error-aware, policy-based learning can deliver strong QE performance under limited data and compute budgets. We release our dataset, code, and trained models to support future research.