GISA: A Benchmark for General Information-Seeking Assistant
作者: Yutao Zhu, Xingshuo Zhang, Maosen Zhang, Jiajie Jin, Liancheng Zhang, Xiaoshuai Song, Kangzhi Zhao, Wencong Zeng, Ruiming Tang, Han Li, Ji-Rong Wen, Zhicheng Dou
分类: cs.CL, cs.AI, cs.IR
发布日期: 2026-02-09
💡 一句话要点
GISA:通用信息搜索助手基准测试,解决现有基准测试不自然和数据污染问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 信息搜索助手 基准测试 大型语言模型 信息聚合 深度推理 数据污染 过程监督
📋 核心要点
- 现有信息搜索助手基准测试存在查询构建不自然、答案集静态易污染等问题,无法真实反映实际信息搜索场景。
- GISA基准测试通过人工构建查询、设计结构化答案格式和引入实时更新答案集,更贴近真实信息搜索需求。
- 实验表明,即使是最好的模型在GISA上的性能也远未达到理想水平,尤其是在复杂规划和信息聚合任务上,仍有很大提升空间。
📝 摘要(中文)
大型语言模型(LLMs)的进步显著加速了搜索代理的发展,这些代理能够通过多轮网络交互自主收集信息。目前已提出了各种基准来评估此类代理。然而,现有的基准通常从答案向后构建查询,产生与真实世界需求不符的非自然任务。此外,这些基准往往侧重于定位特定信息或聚合来自多个来源的信息,同时依赖于容易出现数据污染的静态答案集。为了弥合这些差距,我们引入了GISA,这是一个通用信息搜索助手基准,包含373个人工设计的查询,反映了真实的信息搜索场景。GISA具有四种结构化的答案格式(项目、集合、列表和表格),从而实现确定性评估。它在统一的任务中集成了深度推理和广泛的信息聚合,并包含一个具有定期更新答案的实时子集,以抵抗记忆。值得注意的是,GISA为每个查询提供完整的人工搜索轨迹,为过程级别的监督和模仿学习提供黄金标准参考。在主流LLM和商业搜索产品上的实验表明,即使是性能最佳的模型也仅达到19.30%的精确匹配得分,并且在需要复杂规划和全面信息收集的任务中,性能明显下降。这些发现突出了未来改进的巨大空间。
🔬 方法详解
问题定义:现有信息搜索助手的评测基准存在以下痛点:1) 查询构建方式不自然,通常是根据答案反向生成查询,与用户真实的信息需求不符;2) 侧重于特定信息定位或简单信息聚合,缺乏对复杂推理和规划能力的考察;3) 答案集静态,容易被模型记忆,导致评估结果失真。
核心思路:GISA的核心思路是构建一个更贴近真实用户场景的、更具挑战性的信息搜索助手评测基准。通过人工构建查询、设计结构化答案格式、引入实时更新答案集等方式,提高基准测试的真实性和可靠性。同时,提供人工搜索轨迹作为黄金标准参考,支持过程级别的监督和模仿学习。
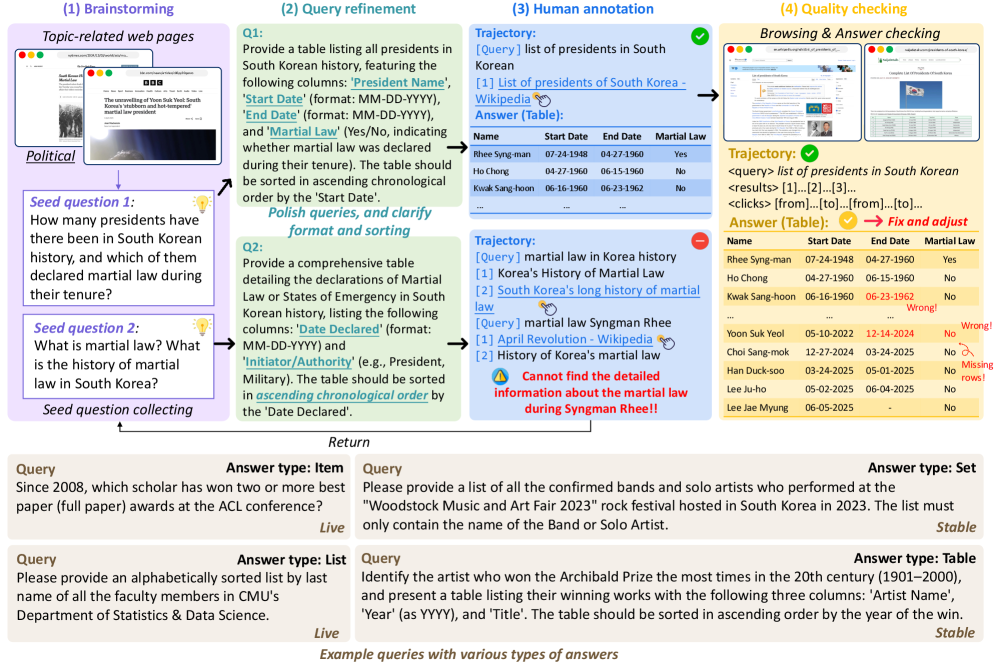
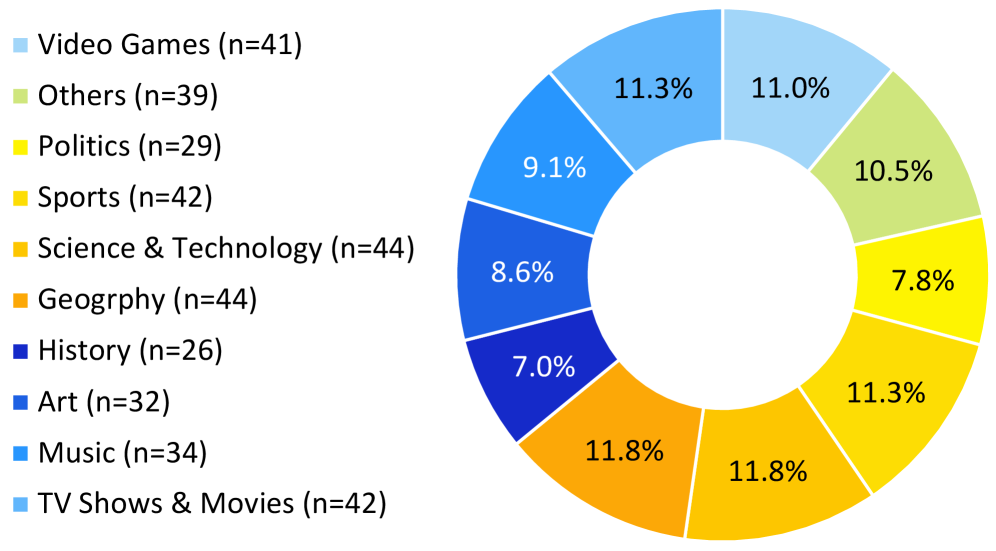
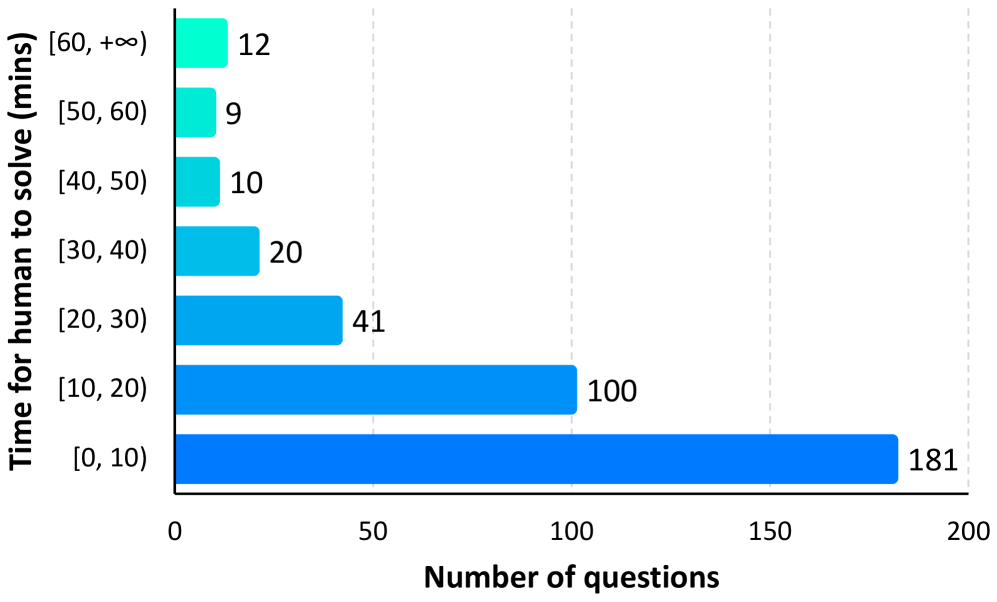
技术框架:GISA基准测试包含以下几个关键组成部分:1) 人工构建的查询集:包含373个查询,覆盖各种信息需求场景;2) 结构化答案格式:支持项目、集合、列表和表格四种答案格式,方便确定性评估;3) 实时更新答案集:包含一个实时子集,答案会定期更新,防止模型记忆;4) 人工搜索轨迹:为每个查询提供完整的人工搜索轨迹,作为过程级别的监督信号。
关键创新:GISA的关键创新在于其更真实、更全面的评测方式。与现有基准相比,GISA的查询更贴近用户真实需求,答案格式更丰富,实时更新机制有效防止了数据污染,人工搜索轨迹为过程监督提供了可能。这些创新使得GISA能够更准确地评估信息搜索助手的真实能力。
关键设计:GISA的关键设计包括:1) 查询的设计:由人工根据真实信息需求构建,避免了反向生成查询带来的不自然性;2) 答案格式的设计:根据信息的组织方式,设计了四种结构化答案格式,方便模型生成和评估;3) 实时更新机制的设计:定期更新答案集,防止模型通过记忆来提高性能;4) 评估指标的设计:采用精确匹配(Exact Match)作为主要评估指标,同时可以利用人工搜索轨迹进行过程级别的评估。
🖼️ 关键图片
📊 实验亮点
实验结果表明,即使是性能最佳的LLM模型在GISA基准测试上也仅达到19.30%的精确匹配得分。在需要复杂规划和全面信息收集的任务中,模型性能显著下降。这些结果表明,现有模型在通用信息搜索能力方面仍有很大的提升空间,GISA可以作为未来研究的重要参考。
🎯 应用场景
GISA基准测试可用于评估和提升通用信息搜索助手的性能,推动相关技术的发展。其潜在应用领域包括智能客服、搜索引擎优化、个性化推荐等。通过GISA的评测,可以更好地了解现有模型的优缺点,指导模型的设计和训练,最终提升信息搜索助手的用户体验。
📄 摘要(原文)
The advancement of large language models (LLMs) has significantly accelerated the development of search agents capable of autonomously gathering information through multi-turn web interactions. Various benchmarks have been proposed to evaluate such agents. However, existing benchmarks often construct queries backward from answers, producing unnatural tasks misaligned with real-world needs. Moreover, these benchmarks tend to focus on either locating specific information or aggregating information from multiple sources, while relying on static answer sets prone to data contamination. To bridge these gaps, we introduce GISA, a benchmark for General Information-Seeking Assistants comprising 373 human-crafted queries that reflect authentic information-seeking scenarios. GISA features four structured answer formats (item, set, list, and table), enabling deterministic evaluation. It integrates both deep reasoning and broad information aggregation within unified tasks, and includes a live subset with periodically updated answers to resist memorization. Notably, GISA provides complete human search trajectories for every query, offering gold-standard references for process-level supervision and imitation learning. Experiments on mainstream LLMs and commercial search products reveal that even the best-performing model achieves only 19.30\% exact match score, with performance notably degrading on tasks requiring complex planning and comprehensive information gathering. These findings highlight substantial room for future improvement.