Large Language Models and Impossible Language Acquisition: "False Promise" or an Overturn of our Current Perspective towards AI
作者: Ziyan wang, Longlong Ma
分类: cs.CL
发布日期: 2026-02-09
💡 一句话要点
通过对比LLM与LSTM学习“不可能语言”的能力,反思AI发展范式
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 不可能语言 乔姆斯基 Transformer架构 LSTM模型 语言理解 人工智能
📋 核心要点
- 乔姆斯基批评LLM仅为模式预测器,无法区分“不可能语言”,挑战了AI的理论基础。
- 论文通过实验对比LLM和LSTM学习“可能语言”和“不可能语言”的能力,验证乔姆斯基的观点。
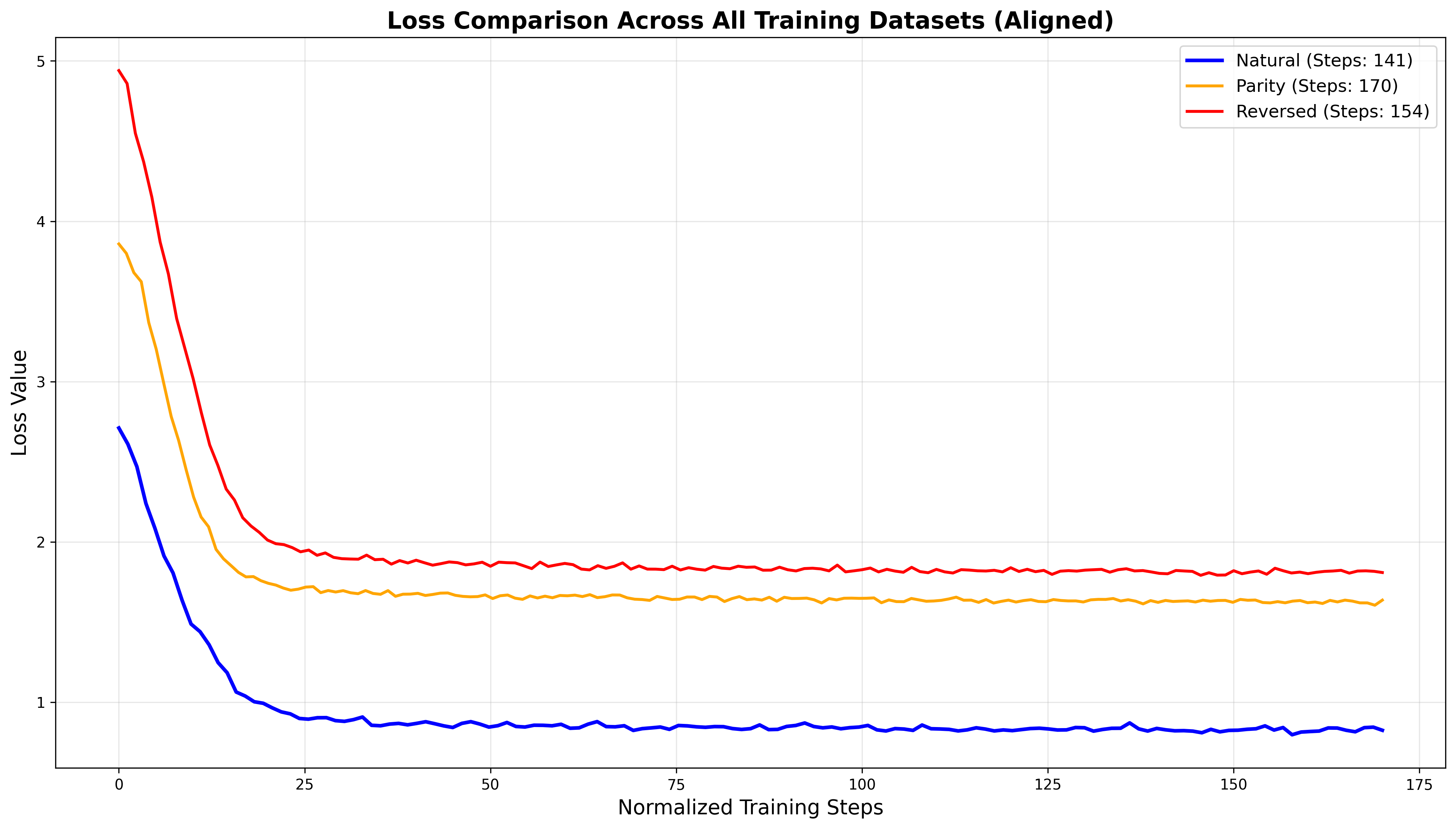
- 实验结果表明GPT-2 small模型在学习“不可能语言”时表现较差,而LSTM模型与乔姆斯基的观点一致。
📝 摘要(中文)
本文旨在探讨大型语言模型(LLMs)是否如乔姆斯基所批评的那样,仅仅是模式预测器,无法像人类一样通过内在的因果和自我纠正结构来学习语言,从而无法区分“不可能语言”。该批评代表了对人工智能理论基础的根本挑战。我们从语言学和心理学的现有文献以及一项基于实验的研究出发,检验了这一著名的批评,该实验探究了LLMs学习可能和不可能语言的能力。我们通过对英语应用某些转换来构建一组句法上不可能的语言,包括反转整个句子和基于字数奇偶性添加否定。在GPT-2 small模型和长短期记忆(LSTM)模型上分别进行了两轮对照实验。统计分析(Welch's t-test)表明,GPT2 small模型在学习所有不可能语言方面的表现不如其在学习可能语言方面的表现(p<.001)。另一方面,LSTM模型的表现与乔姆斯基的论点相符,表明了Transformer架构演变的不可替代的作用。基于理论分析和实证研究结果,我们提出了乔姆斯基理论中关于LLMs的新视角,以及从他的“理性主义-浪漫主义”范式到LLMs研究中的功能主义和经验主义的理论范式转变。
🔬 方法详解
问题定义:论文旨在探讨大型语言模型(LLMs)是否能够真正理解语言,或者仅仅是学习了语言的表面模式。现有方法,特别是基于Transformer的LLMs,虽然在各种NLP任务中表现出色,但缺乏对语言深层结构的理解,可能无法区分符合语法规则的“可能语言”和违反语法规则的“不可能语言”。乔姆斯基的批评指出,LLMs无法像人类一样通过内在的因果和自我纠正结构来学习语言,因此无法区分“不可能语言”。
核心思路:论文的核心思路是通过设计实验,让LLMs和LSTM模型学习“可能语言”和“不可能语言”,然后比较它们的学习效果。如果LLMs能够很好地学习“不可能语言”,则表明它们可能不仅仅是学习了语言的表面模式,而是具有一定的语言理解能力。反之,如果LLMs在学习“不可能语言”时表现较差,则支持乔姆斯基的观点。LSTM模型作为一种传统的序列模型,被用作对比基线,以评估Transformer架构对学习“不可能语言”的影响。
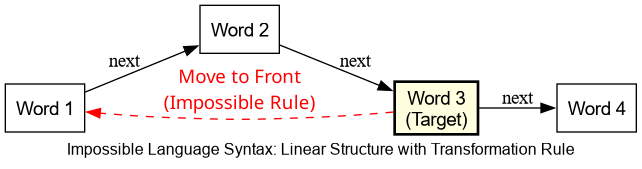
技术框架:实验框架主要包括以下几个步骤:1) 构建“可能语言”和“不可能语言”的数据集。其中,“可能语言”为标准的英语,“不可能语言”通过对英语句子进行特定的转换得到,例如反转整个句子和基于字数奇偶性添加否定。2) 使用GPT-2 small模型和LSTM模型分别在“可能语言”和“不可能语言”的数据集上进行训练。3) 评估模型在学习“可能语言”和“不可能语言”方面的表现。评估指标包括模型的困惑度(perplexity)等。4) 使用Welch's t-test进行统计分析,比较不同模型在不同语言上的表现差异。
关键创新:论文的关键创新在于:1) 将乔姆斯基对LLMs的批评转化为可验证的实验问题。2) 通过构建“不可能语言”的数据集,为评估LLMs的语言理解能力提供了一种新的方法。3) 通过对比LLMs和LSTM模型在学习“不可能语言”方面的表现,揭示了Transformer架构对学习语言深层结构的影响。
关键设计:在数据集构建方面,论文设计了多种“不可能语言”,例如反转整个句子和基于字数奇偶性添加否定,以考察模型对不同类型的语法错误的敏感性。在模型训练方面,论文使用了GPT-2 small模型和LSTM模型,并对模型的超参数进行了调整,以获得最佳的学习效果。在评估指标方面,论文使用了困惑度(perplexity)等指标来衡量模型的语言建模能力。在统计分析方面,论文使用了Welch's t-test来比较不同模型在不同语言上的表现差异,并计算了p值,以评估结果的显著性。
🖼️ 关键图片
📊 实验亮点
实验结果显示,GPT-2 small模型在学习“不可能语言”方面的表现明显不如其在学习“可能语言”方面的表现(p<.001),这表明GPT-2 small模型能够区分“可能语言”和“不可能语言”,并具有一定的语言理解能力。另一方面,LSTM模型的表现与乔姆斯基的论点相符,表明了Transformer架构在学习语言深层结构方面的优势。
🎯 应用场景
该研究有助于我们更深入地理解LLMs的语言学习机制,并为未来的AI研究提供新的方向。例如,可以基于该研究设计更有效的LLMs训练方法,使其能够更好地理解语言的深层结构,从而提高其在各种NLP任务中的表现。此外,该研究还可以应用于评估LLMs的安全性,例如,可以利用“不可能语言”来检测LLMs是否存在潜在的偏见或漏洞。
📄 摘要(原文)
In Chomsky's provocative critique "The False Promise of CHATGPT," Large Language Models (LLMs) are characterized as mere pattern predictors that do not acquire languages via intrinsic causal and self-correction structures like humans, therefore are not able to distinguish impossible languages. It stands as a representative in a fundamental challenge to the intellectual foundations of AI, for it integrally synthesizes major issues in methodologies within LLMs and possesses an iconic a priori rationalist perspective. We examine this famous critic from both the perspective in pre-existing literature of linguistics and psychology as well as a research based on an experiment inquiring the capacity of learning both possible and impossible languages among LLMs. We constructed a set of syntactically impossible languages by applying certain transformations to English. These include reversing whole sentences, and adding negation based on word-count parity. Two rounds of controlled experiments were each conducted on GPT-2 small models and long short-term memory (LSTM) models. Statistical analysis (Welch's t-test) shows GPT2 small models underperform in learning all of the impossible languages compared to their performance on the possible language (p<.001). On the other hand, LSTM models' performance tallies with Chomsky's argument, suggesting the irreplaceable role of the evolution of transformer architecture. Based on theoretical analysis and empirical findings, we propose a new vision within Chomsky's theory towards LLMs, and a shift of theoretical paradigm outside Chomsky, from his "rationalist-romantics" paradigm to functionalism and empiricism in LLMs research.