TEAM: Temporal-Spatial Consistency Guided Expert Activation for MoE Diffusion Language Model Acceleration
作者: Linye Wei, Zixiang Luo, Pingzhi Tang, Meng Li
分类: cs.CL
发布日期: 2026-02-09
🔗 代码/项目: GITHUB
💡 一句话要点
TEAM:时序-空间一致性引导的专家激活加速MoE扩散语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散语言模型 混合专家模型 模型加速 时空一致性 专家路由 推理优化 并行解码
📋 核心要点
- MoE dLLM虽然性能强大,但在扩散解码过程中激活大量专家导致推理开销巨大,限制了其在延迟敏感场景的应用。
- TEAM框架利用专家路由决策在时序和空间上的一致性,通过更少的专家激活更多token,从而加速MoE dLLM。
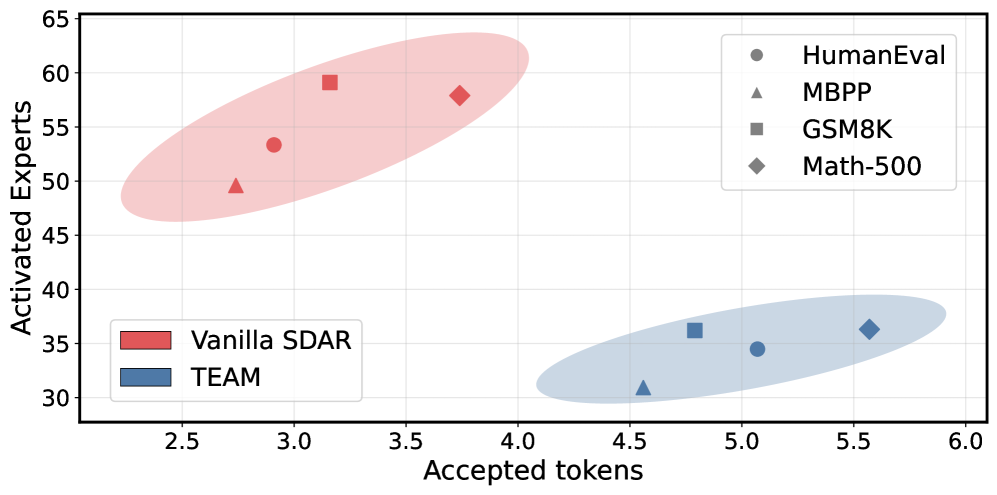
- 实验表明,TEAM在几乎不损失性能的前提下,实现了高达2.2倍的推理加速,显著提升了MoE dLLM的效率。
📝 摘要(中文)
扩散大型语言模型(dLLMs)因其固有的并行解码能力而备受关注。基于此,具有自回归(AR)初始化的混合专家(MoE) dLLMs进一步展示了与主流AR模型相媲美的强大性能。然而,我们发现MoE架构与基于扩散的解码之间存在根本不匹配。具体而言,在每个去噪步骤中都会激活大量专家,而最终只接受一小部分token,从而导致巨大的推理开销,并限制了它们在对延迟敏感的应用中的部署。在这项工作中,我们提出了TEAM,一个即插即用的框架,通过用更少的激活专家启用更多接受的token来加速MoE dLLMs。TEAM的动机是观察到专家路由决策在去噪级别上表现出很强的时间一致性,以及在token位置上表现出很强的空间一致性。利用这些特性,TEAM采用了三种互补的专家激活和解码策略,保守地选择解码和掩码token所需的专家,并同时对多个候选者进行积极的推测性探索。实验结果表明,TEAM在vanilla MoE dLLM上实现了高达2.2倍的加速,而性能下降可以忽略不计。代码已在https://github.com/PKU-SEC-Lab/TEAM-MoE-dLLM上发布。
🔬 方法详解
问题定义:论文旨在解决MoE扩散语言模型(MoE dLLM)在推理过程中效率低下的问题。现有方法在每个去噪步骤激活大量专家,但最终只有少量token被接受,造成了计算资源的浪费,限制了其在对延迟敏感的应用中的部署。
核心思路:论文的核心思路是利用专家路由决策在时间(不同去噪级别)和空间(不同token位置)上表现出的一致性。通过预测哪些专家更有可能被需要,从而减少激活的专家数量,提高推理效率。
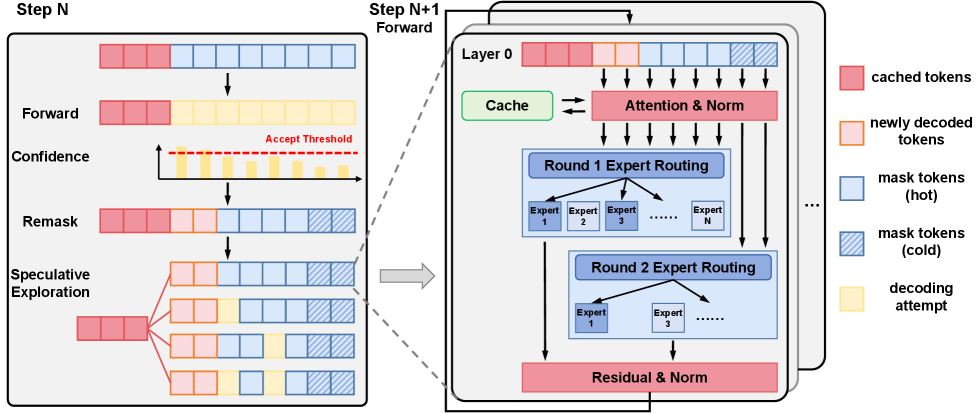
技术框架:TEAM框架是一个即插即用的模块,可以集成到现有的MoE dLLM中。它包含三个主要策略:1) 保守选择:为已解码和被mask的token选择必要的专家;2) 积极探索:对多个候选专家进行推测性探索;3) 时空一致性引导:利用历史信息和相邻token的信息来指导专家选择。整体流程是在每个去噪步骤中,首先利用时空一致性信息预测需要激活的专家集合,然后执行保守选择和积极探索策略,最终完成token的解码。
关键创新:该论文的关键创新在于发现了并利用了MoE dLLM中专家路由决策的时空一致性。这种一致性使得可以预测哪些专家更有可能被需要,从而避免了不必要的专家激活,显著提高了推理效率。与现有方法相比,TEAM不是盲目地激活所有专家,而是有选择性地激活,从而降低了计算复杂度。
关键设计:TEAM框架的关键设计包括:1) 时序一致性建模:利用先前去噪步骤的专家激活信息来预测当前步骤的专家选择;2) 空间一致性建模:利用相邻token的专家激活信息来预测当前token的专家选择;3) 专家选择策略:结合保守选择和积极探索,在保证性能的同时,尽可能减少激活的专家数量。具体的参数设置和网络结构细节在论文中应该有更详细的描述(未知)。
🖼️ 关键图片

📊 实验亮点
实验结果表明,TEAM框架在MoE dLLM上实现了高达2.2倍的推理加速,同时性能下降可以忽略不计。这意味着在几乎不损失模型精度的前提下,显著提高了模型的推理效率。该结果验证了时空一致性在专家选择中的有效性,并为加速MoE dLLM提供了一种有效的解决方案。
🎯 应用场景
该研究成果可应用于各种需要快速响应的自然语言处理任务,例如实时对话系统、机器翻译、文本摘要等。通过加速MoE dLLM的推理过程,可以降低延迟,提高用户体验,并降低部署成本。未来,该技术有望推动dLLM在更多实际场景中的应用。
📄 摘要(原文)
Diffusion large language models (dLLMs) have recently gained significant attention due to their inherent support for parallel decoding. Building on this paradigm, Mixture-of-Experts (MoE) dLLMs with autoregressive (AR) initialization have further demonstrated strong performance competitive with mainstream AR models. However, we identify a fundamental mismatch between MoE architectures and diffusion-based decoding. Specifically, a large number of experts are activated at each denoising step, while only a small subset of tokens is ultimately accepted, resulting in substantial inference overhead and limiting their deployment in latency-sensitive applications. In this work, we propose TEAM, a plug-and-play framework that accelerates MoE dLLMs by enabling more accepted tokens with fewer activated experts. TEAM is motivated by the observation that expert routing decisions exhibit strong temporal consistency across denoising levels as well as spatial consistency across token positions. Leveraging these properties, TEAM employs three complementary expert activation and decoding strategies, conservatively selecting necessary experts for decoded and masked tokens and simultaneously performing aggressive speculative exploration across multiple candidates. Experimental results demonstrate that TEAM achieves up to 2.2x speedup over vanilla MoE dLLM, with negligible performance degradation. Code is released at https://github.com/PKU-SEC-Lab/TEAM-MoE-dLLM.