ViGoEmotions: A Benchmark Dataset For Fine-grained Emotion Detection on Vietnamese Texts
作者: Hung Quang Tran, Nam Tien Pham, Son T. Luu, Kiet Van Nguyen
分类: cs.CL
发布日期: 2026-02-09
备注: Accepted as main paper at EACL 2026
💡 一句话要点
提出ViGoEmotions越南语细粒度情感检测数据集,并评估多种预训练模型。
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 情感分类 越南语 细粒度情感 社交媒体 预训练模型
📋 核心要点
- 情感分类在情感预测和有害内容检测中至关重要,但越南语细粒度情感数据集相对匮乏。
- 本文构建了包含27种细粒度情感的ViGoEmotions数据集,并探索了不同的表情符号预处理策略。
- 实验表明,ViSoBERT模型在ViGoEmotions数据集上取得了最佳性能,Macro F1-score达到61.50%。
📝 摘要(中文)
本文介绍了一个越南语情感语料库ViGoEmotions,它包含20664条社交媒体评论,每条评论被分类为27种细粒度的不同情感。为了评估数据集的质量及其对情感分类的影响,本文评估了八个基于Transformer的预训练模型,并采用了三种预处理策略:保留原始表情符号并进行基于规则的归一化、将表情符号转换为文本描述以及应用ViSoLex(一种基于模型的词汇归一化系统)。结果表明,将表情符号转换为文本通常可以提高几个基于BERT的基线的性能,而保留表情符号则为ViSoBERT和CafeBERT带来最佳结果。相反,删除表情符号通常会导致性能下降。ViSoBERT实现了最高的Macro F1-score 61.50%和Weighted F1-score 63.26%。CafeBERT和PhoBERT也表现出强大的性能。这些发现表明,虽然所提出的语料库可以有效地支持各种架构,但预处理策略和标注质量仍然是影响下游性能的关键因素。
🔬 方法详解
问题定义:现有情感分类方法在越南语细粒度情感识别方面面临数据集不足的挑战。社交媒体文本包含大量表情符号,如何有效处理这些表情符号以提升模型性能也是一个待解决的问题。
核心思路:本文的核心思路是构建一个高质量的越南语细粒度情感数据集,并研究不同的表情符号预处理策略对情感分类性能的影响。通过比较不同的预训练模型在不同预处理策略下的表现,找到最适合该数据集的模型和预处理方法。
技术框架:该研究主要包含两个部分:数据集构建和模型评估。数据集构建涉及数据收集、情感标注和质量控制。模型评估部分则选取了八个基于Transformer的预训练模型,并在三种不同的表情符号预处理策略下进行训练和测试。这三种预处理策略分别是:保留原始表情符号并进行基于规则的归一化、将表情符号转换为文本描述以及删除表情符号。
关键创新:该研究的关键创新在于构建了一个大规模的越南语细粒度情感数据集ViGoEmotions,该数据集包含27种不同的情感类别,为越南语情感分析研究提供了宝贵的资源。此外,该研究还系统地比较了不同的表情符号预处理策略对情感分类性能的影响,为实际应用中如何处理表情符号提供了指导。
关键设计:在数据集构建方面,采用了人工标注的方式,并进行了严格的质量控制,以保证数据集的准确性和一致性。在模型评估方面,选取了多个具有代表性的预训练模型,并采用了常用的评估指标(如Macro F1-score和Weighted F1-score)来评估模型的性能。三种预处理策略的具体实现细节(例如,基于规则的归一化规则、表情符号到文本的映射规则)未在论文中详细描述。
🖼️ 关键图片

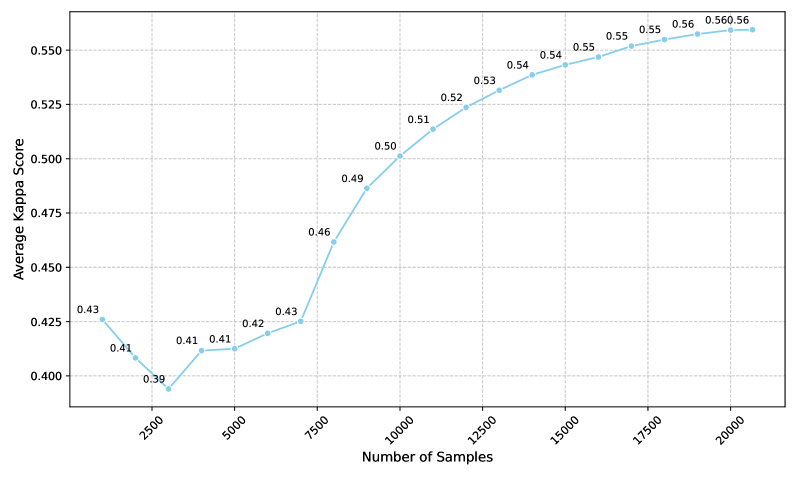
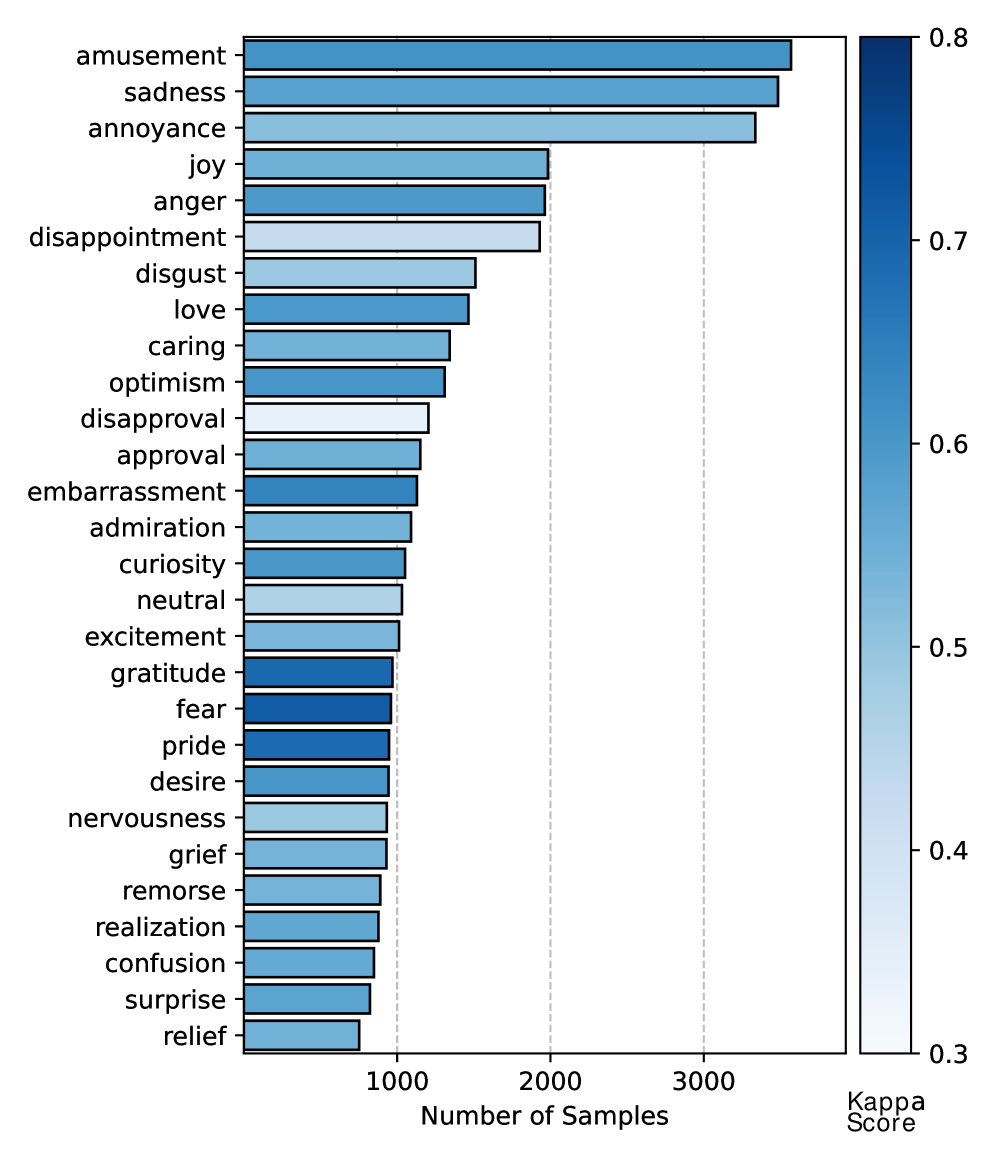
📊 实验亮点
ViSoBERT模型在ViGoEmotions数据集上取得了最佳性能,Macro F1-score达到61.50%,Weighted F1-score达到63.26%。将表情符号转换为文本描述的预处理策略通常可以提高基于BERT的基线的性能。删除表情符号通常会导致性能下降。CafeBERT和PhoBERT也表现出强大的性能。
🎯 应用场景
该研究成果可应用于社交媒体情感分析、舆情监控、智能客服、个性化推荐等领域。通过准确识别用户的情感,可以更好地理解用户需求,提供更优质的服务,并及时发现和处理有害信息,维护网络安全。
📄 摘要(原文)
Emotion classification plays a significant role in emotion prediction and harmful content detection. Recent advancements in NLP, particularly through large language models (LLMs), have greatly improved outcomes in this field. This study introduces ViGoEmotions -- a Vietnamese emotion corpus comprising 20,664 social media comments in which each comment is classified into 27 fine-grained distinct emotions. To evaluate the quality of the dataset and its impact on emotion classification, eight pre-trained Transformer-based models were evaluated under three preprocessing strategies: preserving original emojis with rule-based normalization, converting emojis into textual descriptions, and applying ViSoLex, a model-based lexical normalization system. Results show that converting emojis into text often improves the performance of several BERT-based baselines, while preserving emojis yields the best results for ViSoBERT and CafeBERT. In contrast, removing emojis generally leads to lower performance. ViSoBERT achieved the highest Macro F1-score of 61.50% and Weighted F1-score of 63.26%. Strong performance was also observed from CafeBERT and PhoBERT. These findings highlight that while the proposed corpus can support diverse architectures effectively, preprocessing strategies and annotation quality remain key factors influencing downstream performance.