WorldTravel: A Realistic Multimodal Travel-Planning Benchmark with Tightly Coupled Constraints
作者: Zexuan Wang, Chenghao Yang, Yingqi Que, Zhenzhu Yang, Huaqing Yuan, Yiwen Wang, Zhengxuan Jiang, Shengjie Fang, Zhenhe Wu, Zhaohui Wang, Zhixin Yao, Jiashuo Liu, Jincheng Ren, Yuzhen Li, Yang Yang, Jiaheng Liu, Jian Yang, Zaiyuan Wang, Ge Zhang, Zhoufutu Wen, Wenhao Huang
分类: cs.CL
发布日期: 2026-02-09
💡 一句话要点
WorldTravel:一个具有紧耦合约束的真实多模态旅行规划基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 旅行规划 多模态学习 长程推理 约束优化 基准测试
📋 核心要点
- 现有基准测试主要关注松散耦合约束,依赖理想化数据,无法捕捉从动态网络环境中提取参数的复杂性。
- WorldTravel通过构建包含真实世界旅行场景的多模态环境,要求智能体从视觉信息中提取约束参数,进行长程规划。
- 实验表明,现有模型在多模态环境下的性能显著下降,揭示了感知-行动差距和规划范围的限制。
📝 摘要(中文)
本文提出了WorldTravel,一个包含5个城市共150个真实旅行场景的基准,旨在评估智能体在处理复杂、紧耦合约束下的规划能力。这些场景平均包含15个以上的相互依赖的时间和逻辑约束。为了模拟真实部署环境,作者开发了WorldTravel-Webscape,这是一个多模态环境,包含超过2000个渲染的网页,智能体必须从中提取视觉布局中的约束参数以进行规划。对10个前沿模型的评估表明,性能显著下降:即使是最先进的GPT-5.2在纯文本设置中也仅达到32.67%的可行性,在多模态环境中则降至19.33%。研究揭示了感知-行动差距以及大约10个约束的规划范围阈值,超过此阈值模型推理会持续失败,表明感知和推理仍然是独立的瓶颈。这些发现强调了对下一代智能体的需求,这些智能体将高保真视觉感知与长程推理相结合,以处理脆弱的现实世界物流。
🔬 方法详解
问题定义:现有旅行规划基准通常采用松散耦合的约束,可以通过局部贪心决策解决,并且依赖于理想化的数据。这使得它们无法真实反映现实世界中旅行规划的复杂性,尤其是在需要从动态网络环境中提取参数时面临的挑战。现有方法难以处理多个相互依赖的时间和逻辑约束,并且缺乏从视觉信息中提取约束参数的能力。
核心思路:WorldTravel的核心思路是构建一个更贴近真实世界的旅行规划环境,其中包含紧耦合的约束和多模态信息。通过要求智能体从网页的视觉布局中提取约束参数,并进行长程规划,来评估智能体在复杂环境下的推理和决策能力。这种设计旨在弥合现有基准与真实世界应用之间的差距。
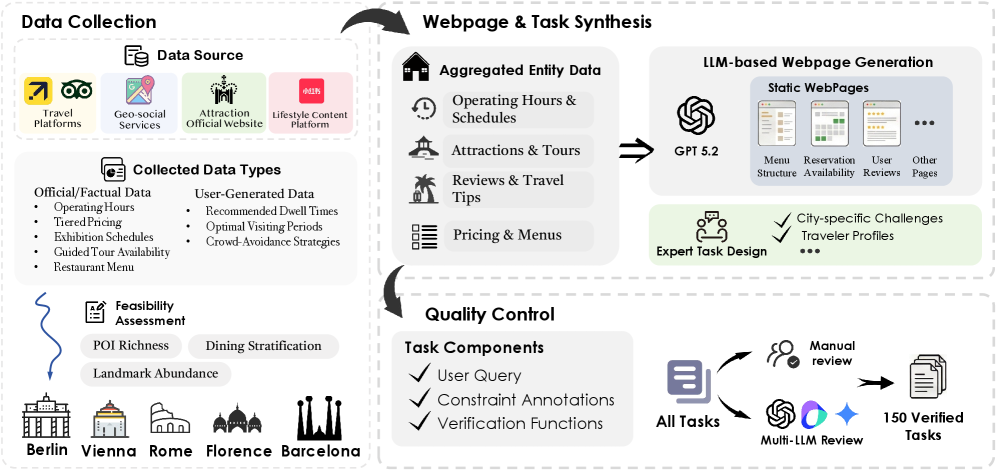
技术框架:WorldTravel包含两个主要组成部分:一是包含150个真实旅行场景的基准数据集,这些场景涉及5个城市,平均包含15个以上的相互依赖的时间和逻辑约束;二是WorldTravel-Webscape,一个多模态环境,包含超过2000个渲染的网页,智能体需要从中提取约束参数。智能体需要首先进行视觉感知,从网页中提取信息,然后进行规划,生成满足所有约束的旅行方案。
关键创新:WorldTravel的关键创新在于其真实性和复杂性。它不仅包含了真实世界的旅行场景,还引入了紧耦合的约束和多模态信息,要求智能体具备更强的感知和推理能力。此外,WorldTravel-Webscape通过渲染真实的网页,模拟了智能体在真实世界中获取信息的场景,使其更具挑战性。
关键设计:WorldTravel-Webscape的关键设计在于其网页渲染引擎和约束提取机制。网页渲染引擎需要能够准确地模拟真实网页的视觉布局,以便智能体能够从中提取信息。约束提取机制需要能够有效地从网页中提取各种约束参数,例如时间、地点、价格等,并将其转换为智能体可以理解的形式。此外,基准测试还定义了可行性的评估指标,用于衡量智能体生成的旅行方案是否满足所有约束。
🖼️ 关键图片


📊 实验亮点
实验结果表明,即使是最先进的GPT-5.2模型在纯文本设置中也仅达到32.67%的可行性,而在多模态环境中则降至19.33%。这表明现有模型在处理复杂约束和多模态信息方面存在显著不足。研究还发现,当规划范围超过10个约束时,模型推理会持续失败,揭示了规划范围的限制。
🎯 应用场景
该研究成果可应用于开发更智能、更实用的旅行规划助手,帮助用户自动规划行程,预订机票、酒店等。此外,该基准测试也可用于评估和改进各种智能体的感知和推理能力,推动人工智能技术在现实世界中的应用,例如物流调度、资源管理等。
📄 摘要(原文)
Real-world autonomous planning requires coordinating tightly coupled constraints where a single decision dictates the feasibility of all subsequent actions. However, existing benchmarks predominantly feature loosely coupled constraints solvable through local greedy decisions and rely on idealized data, failing to capture the complexity of extracting parameters from dynamic web environments. We introduce \textbf{WorldTravel}, a benchmark comprising 150 real-world travel scenarios across 5 cities that demand navigating an average of 15+ interdependent temporal and logical constraints. To evaluate agents in realistic deployments, we develop \textbf{WorldTravel-Webscape}, a multi-modal environment featuring over 2,000 rendered webpages where agents must perceive constraint parameters directly from visual layouts to inform their planning. Our evaluation of 10 frontier models reveals a significant performance collapse: even the state-of-the-art GPT-5.2 achieves only 32.67\% feasibility in text-only settings, which plummets to 19.33\% in multi-modal environments. We identify a critical Perception-Action Gap and a Planning Horizon threshold at approximately 10 constraints where model reasoning consistently fails, suggesting that perception and reasoning remain independent bottlenecks. These findings underscore the need for next-generation agents that unify high-fidelity visual perception with long-horizon reasoning to handle brittle real-world logistics.