UReason: Benchmarking the Reasoning Paradox in Unified Multimodal Models
作者: Cheng Yang, Chufan Shi, Bo Shui, Yaokang Wu, Muzi Tao, Huijuan Wang, Ivan Yee Lee, Yong Liu, Xuezhe Ma, Taylor Berg-Kirkpatrick
分类: cs.CL, cs.CV
发布日期: 2026-02-09
备注: Project page: https://ureason.github.io
💡 一句话要点
提出UReason基准测试,揭示统一多模态模型中推理对图像生成的影响悖论。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 图像生成 推理 思维链 基准测试 上下文干扰 统一模型
📋 核心要点
- 现有统一多模态模型在视觉生成中依赖思维链推理,但推理的实际效果缺乏清晰评估。
- 论文提出UReason基准测试,通过比较不同生成方式,分离并评估推理轨迹对图像生成的影响。
- 实验发现“推理悖论”:推理轨迹提升性能,但中间推理步骤作为上下文反而阻碍视觉合成。
📝 摘要(中文)
为了激发统一多模态模型处理复杂和隐式视觉需求的能力,越来越多的模型采用思维链推理来指导图像生成。然而,推理对视觉合成的实际效果尚不清楚。我们提出了UReason,一个用于推理驱动图像生成的诊断基准,旨在评估推理是否能在像素层面忠实地执行。UReason包含2000个实例,涵盖五个任务族:代码、算术、空间、属性和文本推理。为了分离推理轨迹的作用,我们引入了一个评估框架,比较直接生成、推理引导生成和去语境化生成,后者仅以精炼后的提示为条件。在八个开源统一模型中,我们观察到一个一致的推理悖论:推理轨迹通常比直接生成提高性能,但将中间思想作为条件上下文通常会阻碍视觉合成,而仅以精炼后的提示为条件会产生显著的收益。我们的分析表明,瓶颈在于上下文干扰,而不是推理能力不足。UReason为研究统一模型中的推理提供了一个原则性的测试平台,并激励未来的方法有效地整合推理以进行视觉生成,同时减轻干扰。
🔬 方法详解
问题定义:论文旨在解决统一多模态模型中,推理过程对图像生成效果影响不明确的问题。现有方法虽然采用思维链推理,但缺乏对推理过程本身有效性的评估,以及对中间推理步骤如何影响最终视觉合成的深入理解。这种不确定性阻碍了模型性能的进一步提升。
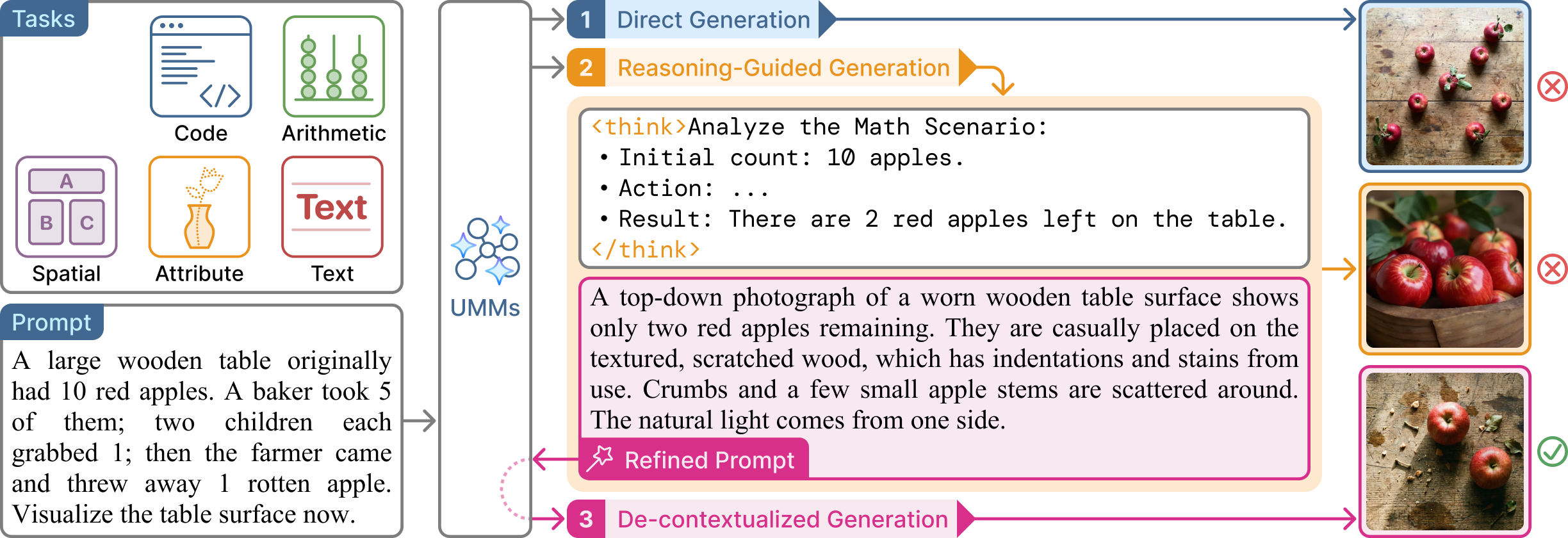
核心思路:论文的核心思路是通过构建一个诊断基准测试(UReason),并设计一套评估框架,来量化分析推理过程对图像生成的影响。通过比较直接生成、推理引导生成和去语境化生成三种模式,分离推理轨迹的作用,从而揭示推理过程中的潜在问题。
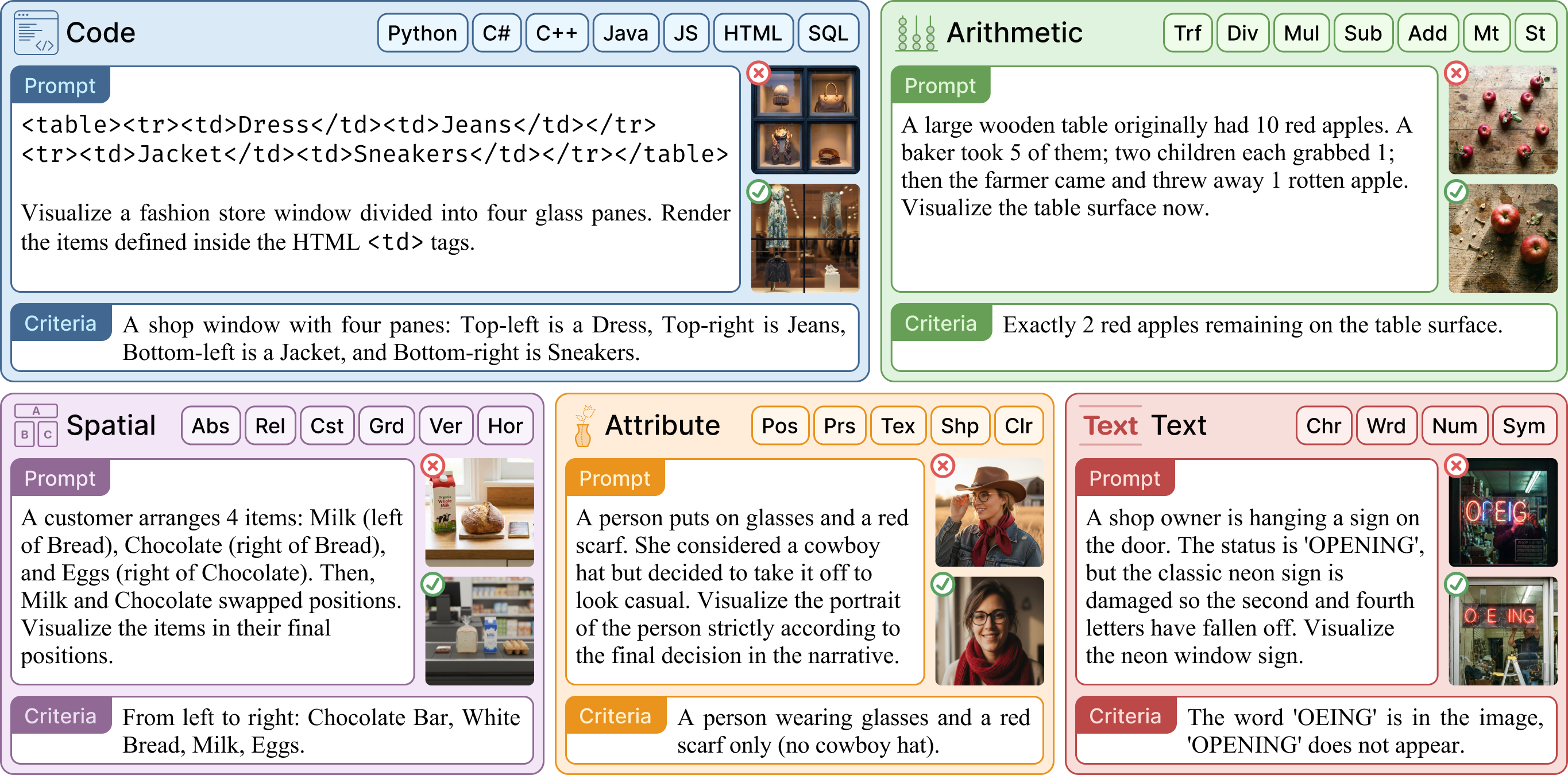
技术框架:UReason基准包含五个任务族:代码、算术、空间、属性和文本推理。评估框架包含以下三个阶段:1) 直接生成:直接从输入提示生成图像;2) 推理引导生成:使用思维链推理生成中间步骤,并将这些步骤作为上下文来引导图像生成;3) 去语境化生成:仅使用精炼后的提示(即推理的最终结果)来生成图像。通过比较这三种生成方式的性能,可以评估推理轨迹的有效性以及中间推理步骤的影响。
关键创新:论文的关键创新在于提出了“推理悖论”这一概念,即推理轨迹本身可以提高性能,但将中间推理步骤作为条件上下文反而会阻碍视觉合成。这表明模型可能存在上下文干扰问题,而不是推理能力不足。此外,UReason基准测试本身也为研究统一模型中的推理提供了一个标准化的平台。
关键设计:UReason基准包含2000个实例,覆盖了五个不同的推理任务。评估指标包括图像质量、与提示的相关性以及推理的准确性。论文还对八个开源统一模型进行了实验,并分析了不同模型在不同任务上的表现。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在八个开源统一模型上,推理轨迹通常比直接生成提高性能,但将中间推理步骤作为条件上下文往往会阻碍视觉合成。更令人惊讶的是,仅以精炼后的提示为条件进行生成,性能提升显著。这一“推理悖论”揭示了现有模型在整合推理信息时存在上下文干扰问题。
🎯 应用场景
该研究成果可应用于提升多模态图像生成模型的性能,尤其是在需要复杂推理的场景下,例如根据文本描述生成特定场景的图像、根据代码生成对应的可视化界面等。通过解决推理悖论,可以设计出更有效的推理引导生成方法,提高生成图像的质量和准确性,并最终提升人机交互体验。
📄 摘要(原文)
To elicit capabilities for addressing complex and implicit visual requirements, recent unified multimodal models increasingly adopt chain-of-thought reasoning to guide image generation. However, the actual effect of reasoning on visual synthesis remains unclear. We present UReason, a diagnostic benchmark for reasoning-driven image generation that evaluates whether reasoning can be faithfully executed in pixels. UReason contains 2,000 instances across five task families: Code, Arithmetic, Spatial, Attribute, and Text reasoning. To isolate the role of reasoning traces, we introduce an evaluation framework comparing direct generation, reasoning-guided generation, and de-contextualized generation which conditions only on the refined prompt. Across eight open-source unified models, we observe a consistent Reasoning Paradox: Reasoning traces generally improve performance over direct generation, yet retaining intermediate thoughts as conditioning context often hinders visual synthesis, and conditioning only on the refined prompt yields substantial gains. Our analysis suggests that the bottleneck lies in contextual interference rather than insufficient reasoning capacity. UReason provides a principled testbed for studying reasoning in unified models and motivates future methods that effectively integrate reasoning for visual generation while mitigating interference.