Latent Reasoning with Supervised Thinking States
作者: Ido Amos, Avi Caciularu, Mor Geva, Amir Globerson, Jonathan Herzig, Lior Shani, Idan Szpektor
分类: cs.CL, cs.AI
发布日期: 2026-02-09
💡 一句话要点
提出Thinking States,通过监督式思维状态实现高效的LLM潜在推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 潜在推理 思维链 大型语言模型 监督学习 状态跟踪
📋 核心要点
- 大型语言模型使用思维链(CoT)进行推理,但生成长篇推理过程导致计算成本高昂,推理延迟大。
- Thinking States方法在处理输入时生成思维token,并将这些token融入到后续输入中,模拟CoT的循环推理过程。
- 实验表明,Thinking States在推理任务上优于其他潜在推理方法,并在某些任务上与CoT性能相当,同时降低了延迟。
📝 摘要(中文)
本文提出了一种名为Thinking States的方法,旨在提升大型语言模型(LLM)的推理效率。该方法在输入处理过程中进行推理,每处理几个输入token就生成一系列思维token,并将这些思维token转换回嵌入空间,添加到后续的输入token中。这种方法具有两个关键优势:首先,它捕捉了思维链(CoT)的循环特性,但思维token是在输入处理时生成的;其次,由于思维以token形式表示,因此可以通过自然语言监督和teacher-forcing进行学习,并且可以并行化。实验结果表明,Thinking States在多个推理任务上优于其他潜在推理方法,缩小了与CoT在数学问题上的差距,并在2-Hop QA上达到了与其相当的性能,同时降低了延迟。在状态跟踪任务中,Thinking States表现出比CoT更强的推理能力,成功外推到比训练期间更长的序列。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)在进行复杂推理时,通常采用思维链(Chain-of-Thought, CoT)方法,即生成一系列中间推理步骤。然而,CoT方法需要生成较长的文本序列,导致显著的计算开销和推理延迟,限制了其在实际应用中的部署。因此,如何在保证推理性能的同时,降低推理成本,是本文要解决的核心问题。
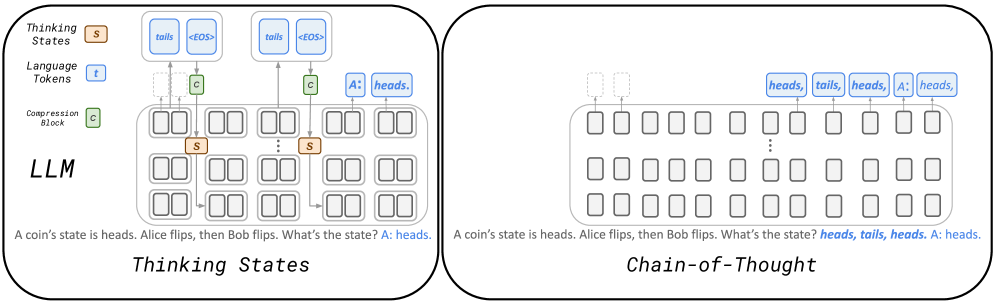
核心思路:本文提出的Thinking States方法的核心思路是在输入处理过程中,周期性地生成“思维token”,这些token代表了模型在处理当前输入后的“思考状态”。这些思维token被转换回嵌入空间,并添加到后续的输入token中,从而影响模型对后续输入的处理。这种方法模拟了CoT的循环推理过程,但避免了生成完整的推理链,从而降低了计算成本。
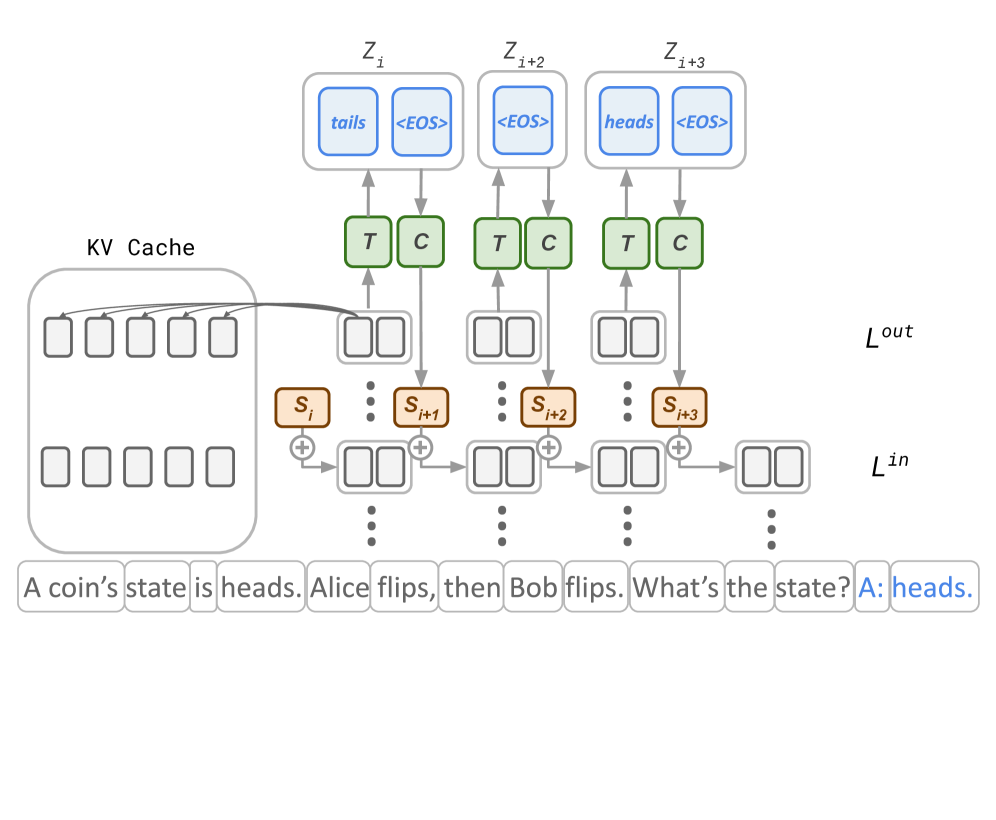
技术框架:Thinking States方法主要包含以下几个阶段:1) 输入编码:将输入文本编码为token序列。2) 思维状态生成:每处理一定数量的输入token,生成一系列思维token,这些token代表了模型当前的推理状态。3) 思维状态嵌入:将思维token转换回嵌入空间,得到思维状态的向量表示。4) 状态融合:将思维状态的向量表示添加到后续的输入token的嵌入中,从而影响模型对后续输入的处理。5) 输出解码:基于融合了思维状态的输入表示,生成最终的输出。
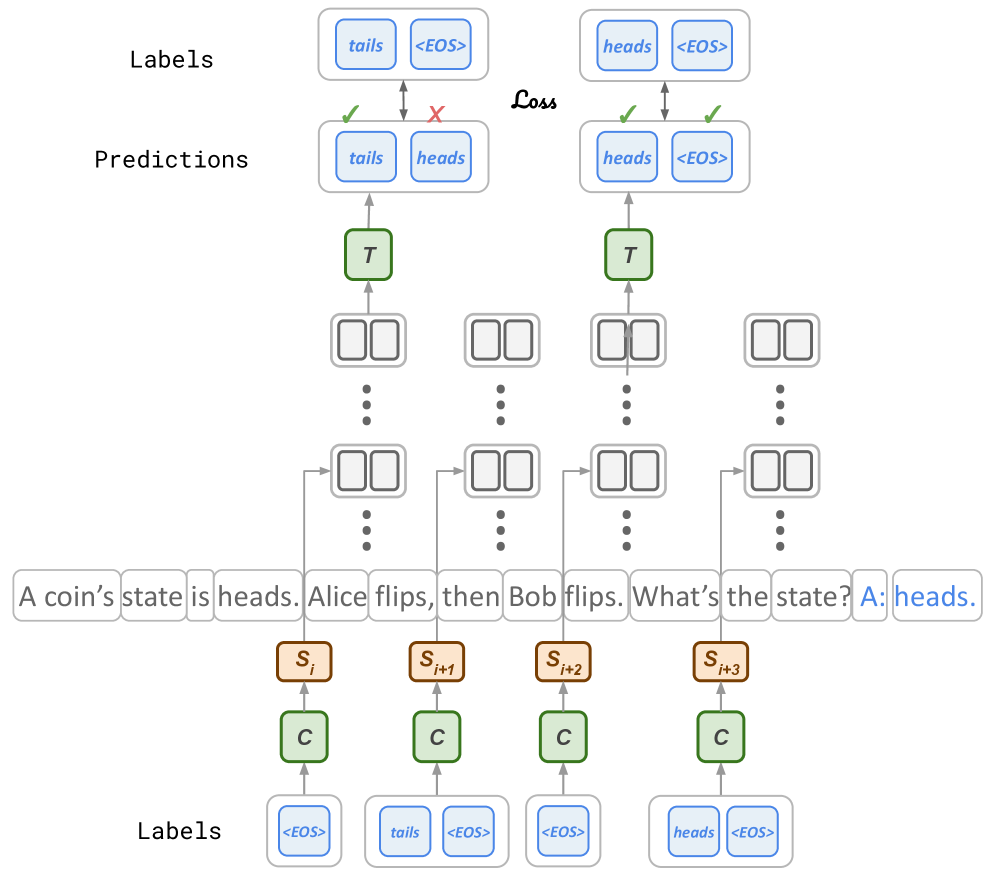
关键创新:Thinking States的关键创新在于将推理过程表示为一系列离散的“思维状态”,并通过监督学习的方式,直接从数据中学习这些思维状态的表示。与传统的CoT方法相比,Thinking States不需要生成完整的推理链,而是通过周期性地更新思维状态来实现推理,从而降低了计算成本。此外,由于思维状态以token形式表示,因此可以使用teacher-forcing进行并行训练,提高了训练效率。
关键设计:在Thinking States中,思维状态的生成频率是一个重要的参数。论文中可能探讨了不同生成频率对性能的影响。此外,思维状态的嵌入方式,以及如何将思维状态融入到输入表示中,也是关键的设计细节。损失函数的设计也至关重要,需要能够有效地监督思维状态的学习,使其能够准确地反映模型的推理过程。具体网络结构未知,但推测使用了Transformer架构。
🖼️ 关键图片
📊 实验亮点
Thinking States在多个推理任务上取得了显著的性能提升。在数学问题求解任务中,Thinking States缩小了与CoT方法的差距。在2-Hop QA任务中,Thinking States达到了与CoT方法相当的性能,同时降低了延迟。在状态跟踪任务中,Thinking States表现出比CoT方法更强的推理能力,成功外推到比训练期间更长的序列。具体性能提升数据未知,但整体效果表明Thinking States是一种有效的潜在推理方法。
🎯 应用场景
Thinking States方法具有广泛的应用前景,可以应用于需要复杂推理的各种任务,例如问答系统、对话系统、数学问题求解、知识图谱推理等。该方法可以显著降低LLM的推理成本,使其能够更高效地部署在资源受限的环境中,例如移动设备或边缘计算设备。此外,Thinking States方法还可以用于提高LLM的可解释性,通过分析思维状态的变化,可以更好地理解模型的推理过程。
📄 摘要(原文)
Reasoning with a chain-of-thought (CoT) enables Large Language Models (LLMs) to solve complex tasks but incurs significant inference costs due to the generation of long rationales. We propose Thinking States, a method that performs reasoning {\em while} the input is processing. Specifically, Thinking States generates sequences of thinking tokens every few input tokens, transforms the thoughts back into embedding space, and adds them to the following input tokens. This has two key advantages. First, it captures the recurrent nature of CoT, but where the thought tokens are generated as input is processing. Second, since the thoughts are represented as tokens, they can be learned from natural language supervision, and using teacher-forcing, which is parallelizable. Empirically, Thinking States outperforms other latent reasoning methods on multiple reasoning tasks, narrowing the gap to CoT on math problems, and matching its performance on 2-Hop QA with improved latency. On state-tracking tasks, we show Thinking States leads to stronger reasoning behavior than CoT, successfully extrapolating to longer sequences than seen during training.