Improving Data and Reward Design for Scientific Reasoning in Large Language Models
作者: Zijie Chen, Zhenghao Lin, Xiao Liu, Zhenzhong Lan, Yeyun Gong, Peng Cheng
分类: cs.CL
发布日期: 2026-02-09
💡 一句话要点
提出Dr. SCI框架,提升大语言模型在开放式科学推理任务上的性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 科学推理 后训练 强化学习 数据集构建
📋 核心要点
- 现有大语言模型在开放式科学问题上表现不佳,主要原因是缺乏可靠的监督和评估机制。
- Dr. SCI框架通过构建大规模数据集、设计动态难度课程和评分标准引导的强化学习,提升模型科学推理能力。
- 实验表明,使用Dr. SCI训练的Qwen3-4B模型在GPQA数据集上显著优于现有模型,尤其在开放式问题上。
📝 摘要(中文)
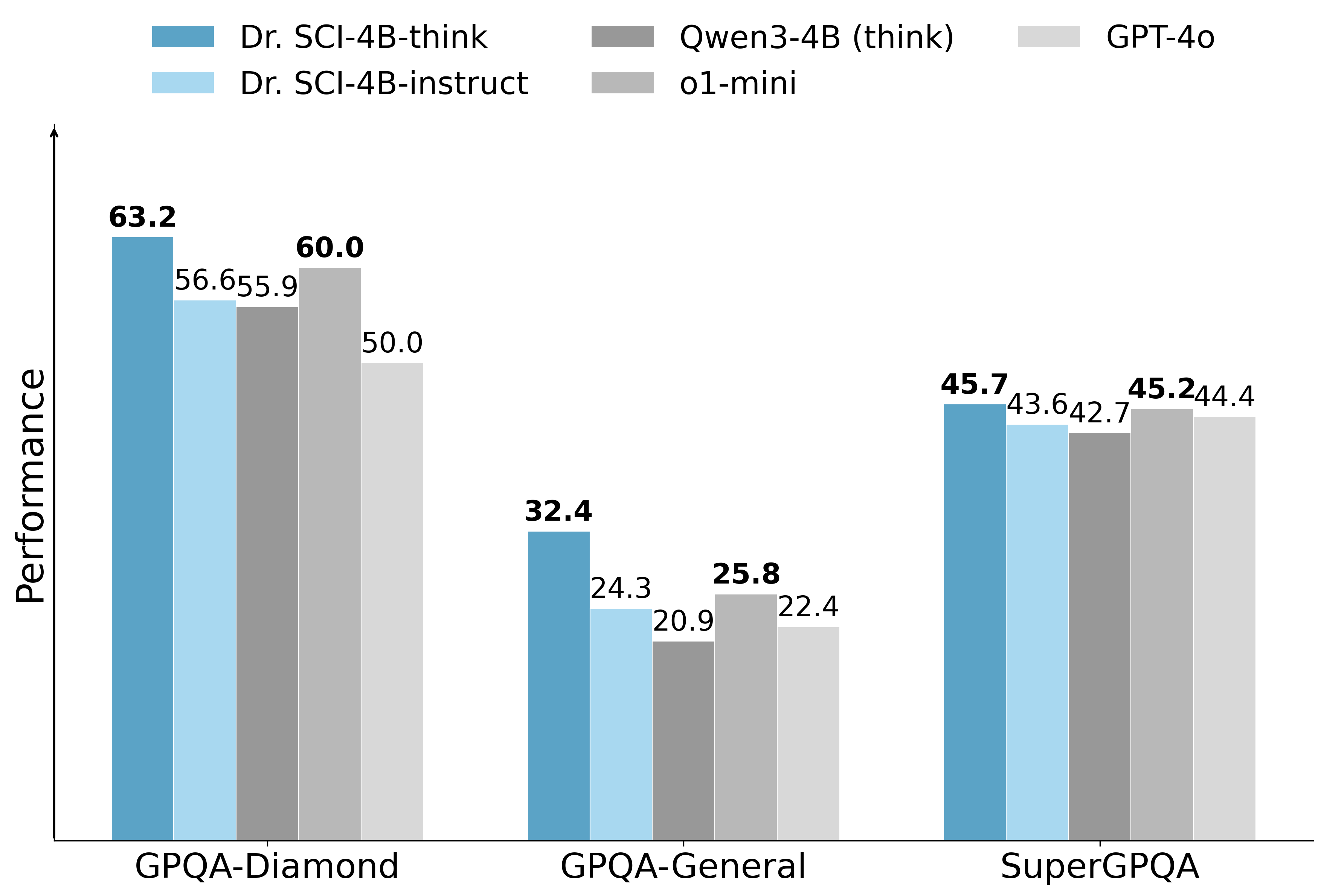
大型语言模型在解决开放式科学问题方面仍然面临挑战,这主要是由于监督和评估的固有不可靠性。瓶颈在于科学后训练的数据构建和奖励设计。我们开发了一个大规模、系统的数据处理流程,将异构的开源科学数据转换为Dr. SCI数据集,该数据集包含八个STEM学科的100万个问题,具有明确的可验证/开放式分割、可扩展的难度标注以及细粒度的评分标准,这些标准可用于开放式答案的评估。在此数据集的基础上,我们提出了Dr. SCI后训练流程,该流程通过三个组件重新设计了标准的SFT -> RL工作流程:(i)探索扩展SFT,在RL之前拓宽模型的推理模式覆盖范围;(ii)动态难度课程,使训练数据适应模型不断发展的科学能力;(iii)SciRubric引导的RL,通过基于评分标准的评估和明确的答案正确性,在开放式科学问题上实现稳定的强化学习。使用Dr.SCI流程训练的Qwen3-4B-Base在GPQA-diamond上达到63.2,在GPQA-general上达到32.4,始终优于强大的后训练基线(如o1-mini和GPT-4o),表明在科学推理方面取得了显著的进步,尤其是在开放式环境中。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在开放式科学推理任务中表现不佳的问题。现有方法面临的痛点在于:1)缺乏高质量、大规模的科学数据集;2)难以对开放式答案进行可靠的评估和奖励;3)模型训练过程难以适应科学知识的复杂性和难度。
核心思路:论文的核心思路是通过系统性的数据构建和奖励设计,改进大语言模型的科学后训练流程。具体而言,构建大规模的Dr. SCI数据集,并设计探索扩展的SFT、动态难度课程和基于评分标准的强化学习,从而提升模型在开放式科学问题上的推理能力。
技术框架:Dr. SCI后训练流程包含三个主要阶段:1)探索扩展SFT:在强化学习之前,使用多样化的科学数据对模型进行微调,扩大模型的推理模式覆盖范围。2)动态难度课程:根据模型当前的科学能力,动态调整训练数据的难度,使模型能够逐步掌握更复杂的科学知识。3)SciRubric引导的RL:使用基于评分标准的奖励函数,对模型的开放式答案进行评估,并利用强化学习算法优化模型的推理策略。
关键创新:论文的关键创新在于:1)构建了大规模、高质量的Dr. SCI数据集,该数据集包含多种STEM学科的开放式科学问题,并具有细粒度的难度标注和评分标准。2)提出了探索扩展的SFT,动态难度课程和基于评分标准的强化学习相结合的后训练流程,能够有效提升模型在开放式科学问题上的推理能力。3)设计了基于评分标准的奖励函数,能够对开放式答案进行更准确和稳定的评估。
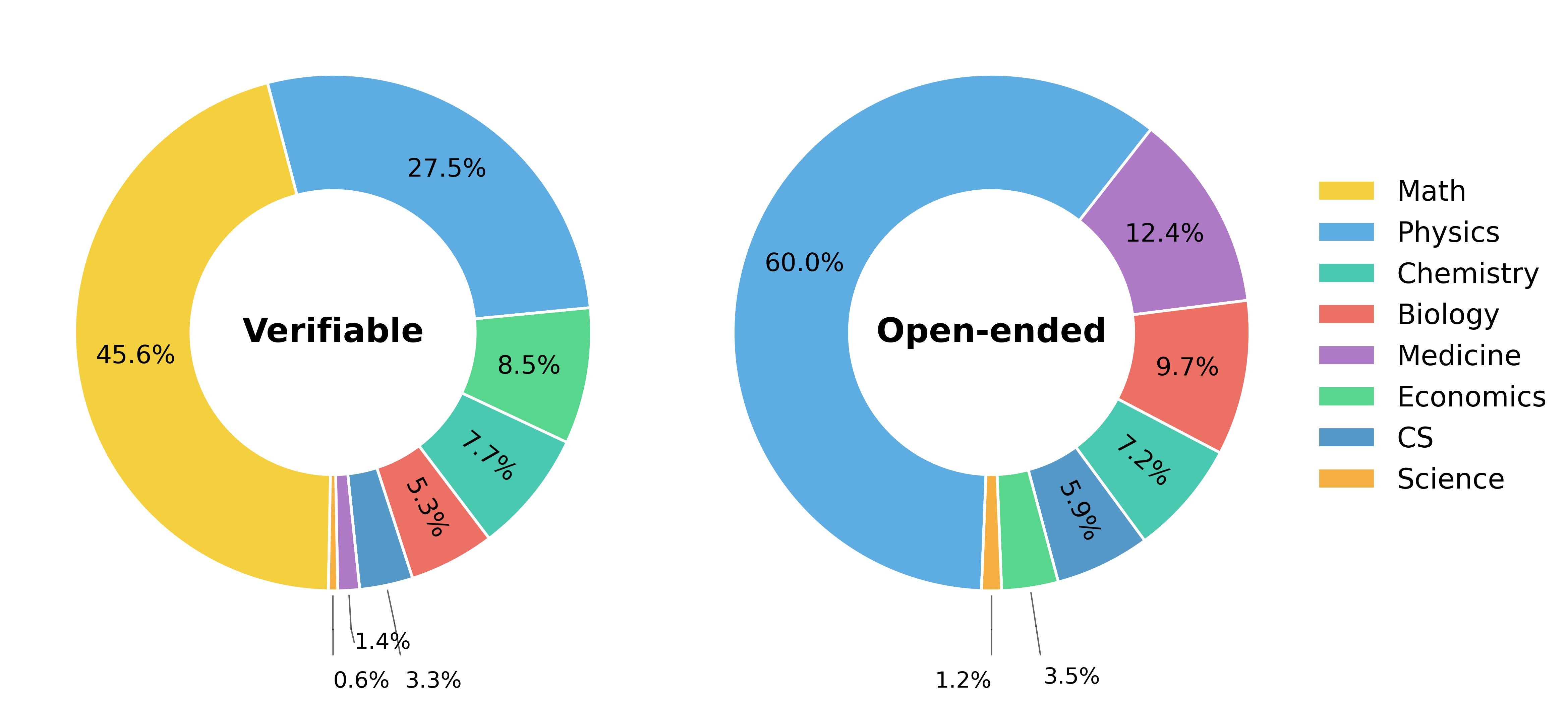
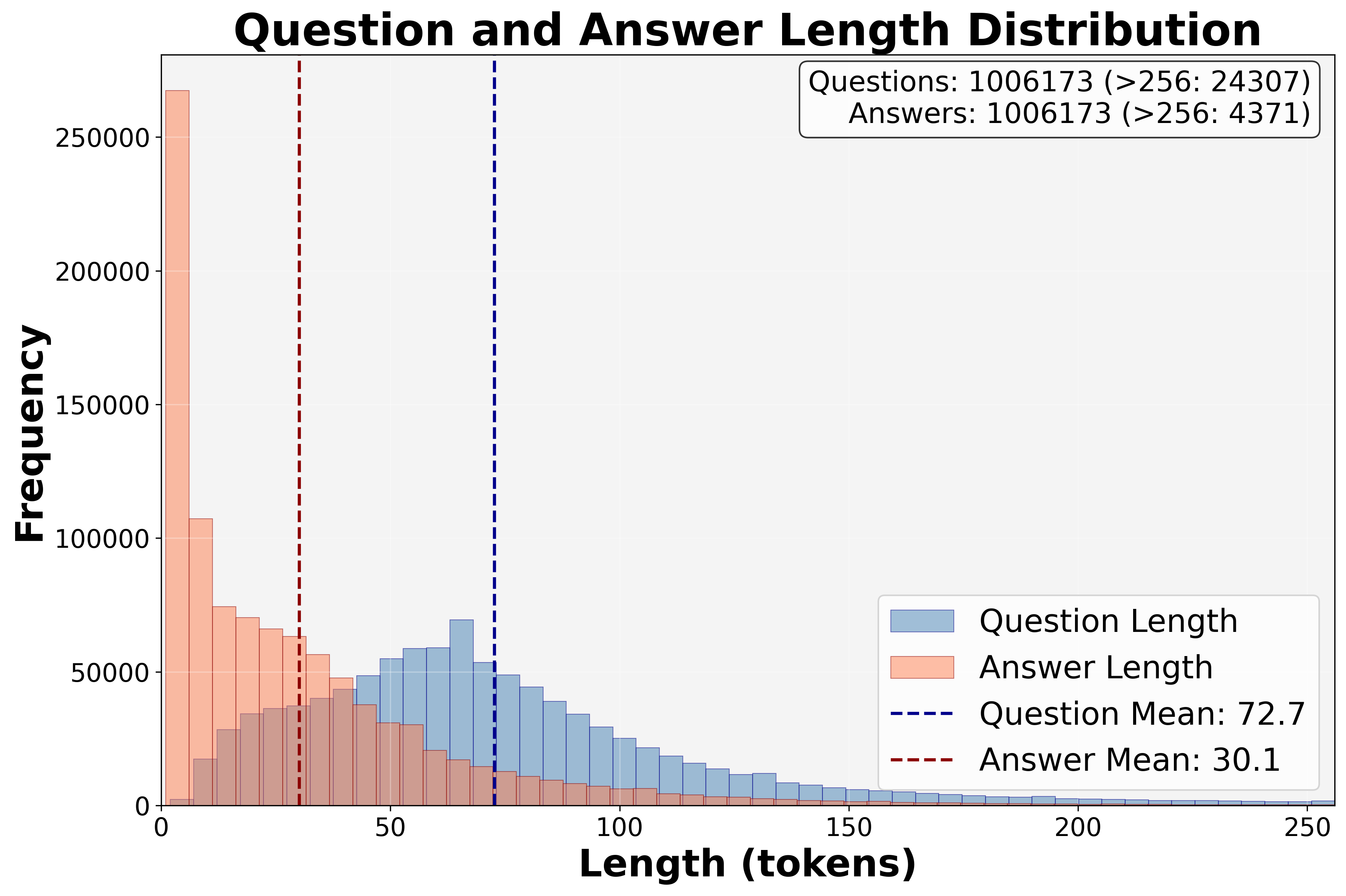
关键设计:Dr. SCI数据集包含1M个问题,涵盖八个STEM学科。动态难度课程根据模型的表现动态调整训练数据的难度。SciRubric引导的RL使用基于评分标准的奖励函数,该函数根据答案的正确性、完整性和相关性等因素进行评分。具体参数设置和损失函数细节在论文中未明确给出,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用Dr. SCI流程训练的Qwen3-4B-Base模型在GPQA-diamond数据集上达到了63.2,在GPQA-general数据集上达到了32.4,显著优于现有的后训练基线模型,例如o1-mini和GPT-4o。这表明Dr. SCI框架能够有效提升大语言模型在开放式科学推理任务上的性能。
🎯 应用场景
该研究成果可应用于智能教育、科学研究和智能问答等领域。例如,可以构建更智能的科学辅导系统,帮助学生理解和解决复杂的科学问题。此外,还可以用于辅助科学家进行科学研究,例如自动生成科学假设和评估实验结果。未来,该技术有望推动人工智能在科学领域的更广泛应用。
📄 摘要(原文)
Solving open-ended science questions remains challenging for large language models, particularly due to inherently unreliable supervision and evaluation. The bottleneck lies in the data construction and reward design for scientific post-training. We develop a large-scale, systematic data processing pipeline that transforms heterogeneous open-source science data into Dr. SCI dataset, which comprises of 1M questions across eight STEM subjects, with explicit verifiable/open-ended splits, scalable difficulty annotation, and fine-grained rubrics that operationalize evaluation for open-ended answers. Building on this dataset, we propose the Dr. SCI post-training pipeline, which redesigns the standard SFT -> RL workflow through three components: (i) Exploration-Expanding SFT, which broadens the model's reasoning pattern coverage prior to RL; (ii) Dynamic Difficulty Curriculum, which adapts training data to the model's evolving scientific capability; and (iii) SciRubric-Guided RL, which enables stable reinforcement learning on open-ended scientific questions via rubric-based evaluation with explicit answer correctness. Qwen3-4B-Base trained using Dr.SCI pipeline achieves 63.2 on GPQA-diamond and 32.4 on GPQA-general, consistently improves over strong post-trained baselines such as o1-mini and GPT-4o, demonstrating substantial gains in scientific reasoning, especially in open-ended settings.