When Does Context Help? Error Dynamics of Contextual Information in Large Language Models
作者: Dingzirui Wang, Xuanliang Zhang, Keyan Xu, Qingfu Zhu, Wanxiang Che, Yang Deng
分类: cs.CL
发布日期: 2026-02-09
💡 一句话要点
提出Transformer大语言模型上下文信息影响的统一理论框架,分析误差动态。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 上下文学习 误差动态 Transformer 检索增强生成
📋 核心要点
- 大语言模型依赖上下文信息提升性能,但缺乏对上下文作用的理论理解,尤其是在上下文学习之外的场景。
- 论文提出了一个统一的理论框架,通过分析输出误差动态来刻画上下文信息在Transformer模型中的影响。
- 实验验证了理论的有效性,并基于此提出了上下文选择策略,在多个任务上实现了性能提升。
📝 摘要(中文)
本文提出了一个统一的理论框架,用于分析基于Transformer的大语言模型中任意上下文信息的影响。该框架通过输出误差动态来描述上下文的影响。在单层Transformer中,证明了上下文条件下的误差向量可以分解为基线误差向量和上下文校正向量的加和。这产生了误差减少的必要几何条件:上下文校正必须与负基线误差对齐,并满足范数约束。进一步表明,上下文校正范数存在一个由上下文-查询相关性和互补性决定的显式上界。这些结果可以推广到多上下文和多层Transformer。在ICL、检索增强生成和记忆演化等实验中,验证了该理论,并提出了一个基于原则的上下文选择策略,将性能提高了0.6%。
🔬 方法详解
问题定义:现有的大语言模型(LLMs)在推理时,可以通过上下文信息(如示例、检索知识或交互历史)来显著提升性能,而无需更新模型参数。然而,除了上下文学习(ICL)等特定设置外,对于上下文信息在LLMs中的理论作用,目前还缺乏深入的理解。现有的方法难以解释和预测上下文信息在各种场景下的影响,以及如何有效地选择和利用上下文信息。
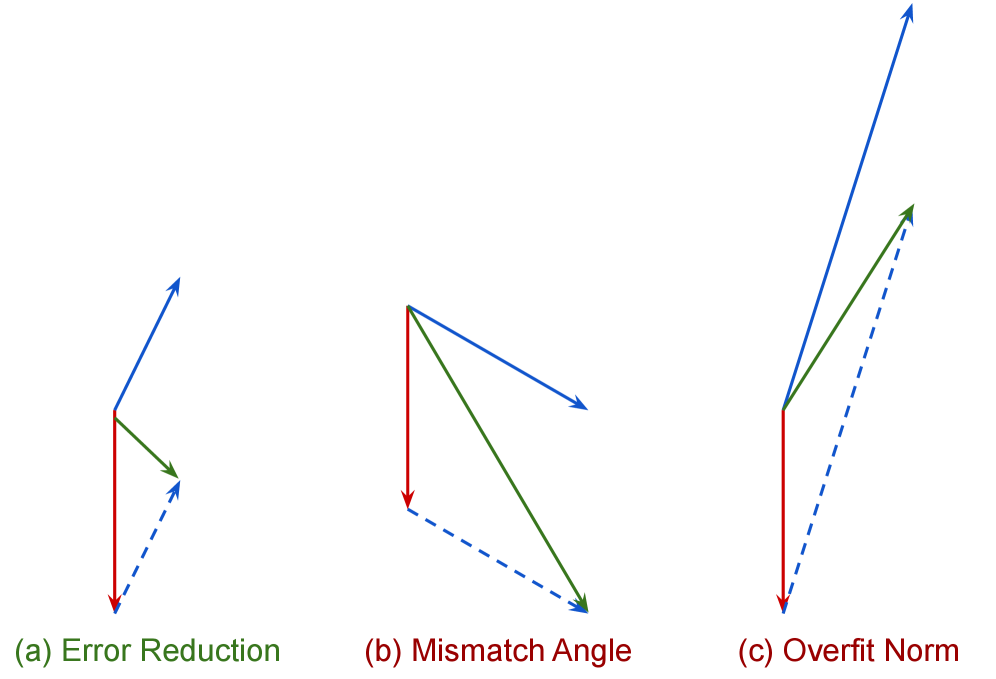
核心思路:本文的核心思路是通过分析输出误差的动态变化来理解上下文信息的影响。具体来说,将上下文信息对模型输出的影响分解为基线误差和上下文校正两部分。通过研究上下文校正向量与基线误差向量之间的关系,可以推导出误差减少的几何条件,从而为上下文选择提供理论指导。
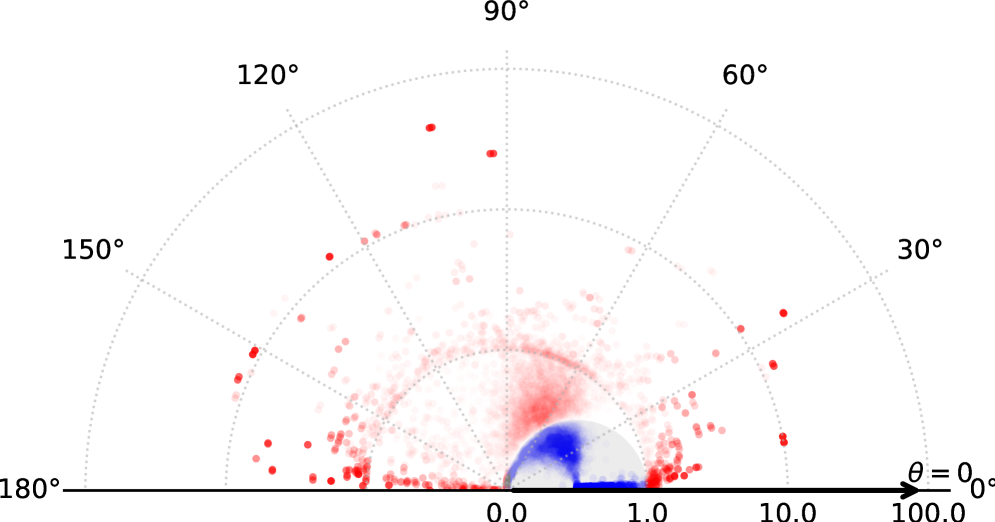
技术框架:该理论框架主要针对基于Transformer的LLMs。首先,在单层Transformer中,将上下文条件下的误差向量分解为基线误差向量和上下文校正向量的加和。然后,推导出误差减少的必要几何条件,即上下文校正向量必须与负基线误差向量对齐,并满足一定的范数约束。接着,分析了上下文校正向量的范数上界,该上界由上下文-查询相关性和互补性决定。最后,将这些结果推广到多上下文和多层Transformer。
关键创新:该论文的关键创新在于提出了一个统一的理论框架,用于分析任意上下文信息在Transformer-based LLMs中的影响。与以往主要关注ICL的研究不同,该框架可以应用于更广泛的场景,如检索增强生成和记忆演化。此外,通过将上下文信息的影响分解为基线误差和上下文校正,为理解上下文信息的作用提供了新的视角。
关键设计:论文的关键设计包括:1) 将误差向量分解为基线误差和上下文校正,从而可以独立分析上下文信息的影响;2) 推导了误差减少的几何条件,为上下文选择提供了理论指导;3) 分析了上下文校正向量的范数上界,该上界由上下文-查询相关性和互补性决定,为理解上下文信息的有效性提供了新的见解。具体的参数设置和网络结构与标准的Transformer模型一致,没有引入新的参数或结构。
🖼️ 关键图片

📊 实验亮点
实验结果表明,基于该理论提出的上下文选择策略能够有效提升大语言模型的性能。在多个任务中,该策略将性能提高了0.6%。这些实验结果验证了该理论的有效性,并表明通过理论指导的上下文选择可以显著提升大语言模型的性能。
🎯 应用场景
该研究成果可应用于多种场景,包括提升大语言模型在问答系统、对话系统、文本生成等任务中的性能。通过理论指导的上下文选择策略,可以更有效地利用上下文信息,提高模型的准确性和可靠性。此外,该研究也有助于理解人类认知中上下文信息的作用,为开发更智能的人工智能系统提供理论基础。
📄 摘要(原文)
Contextual information at inference time, such as demonstrations, retrieved knowledge, or interaction history, can substantially improve large language models (LLMs) without parameter updates, yet its theoretical role remains poorly understood beyond specific settings such as in-context learning (ICL). We present a unified theoretical framework for analyzing the effect of arbitrary contextual information in Transformer-based LLMs. Our analysis characterizes contextual influence through output error dynamics. In a single-layer Transformer, we prove that the context-conditioned error vector decomposes additively into the baseline error vector and a contextual correction vector. This yields necessary geometric conditions for error reduction: the contextual correction must align with the negative baseline error and satisfy a norm constraint. We further show that the contextual correction norm admits an explicit upper bound determined by context-query relevance and complementarity. These results extend to multi-context and multi-layer Transformers. Experiments across ICL, retrieval-augmented generation, and memory evolution validate our theory and motivate a principled context selection strategy that improves performance by $0.6\%$.