New Skills or Sharper Primitives? A Probabilistic Perspective on the Emergence of Reasoning in RLVR
作者: Zhilin Wang, Yafu Li, Shunkai Zhang, Zhi Wang, Haoran Zhang, Xiaoye Qu, Yu Cheng
分类: cs.CL
发布日期: 2026-02-09
备注: 15 pages
💡 一句话要点
提出概率框架以解释RLVR中推理能力的出现
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 可验证奖励 推理能力 概率框架 多步骤任务 模型训练 自然语言处理
📋 核心要点
- 现有方法在多步骤推理中面临成功率指数衰减的挑战,导致模型难以有效解决复杂任务。
- 本文提出了一种概率框架,通过提高原子步骤的成功概率,促进复杂推理能力的出现。
- 实验证明,RLVR能够激励模型探索新解路径,且复合性能与原子步骤的联合概率高度相关。
📝 摘要(中文)
在强化学习与可验证奖励(RLVR)中,是否赋予大型语言模型(LLMs)新能力或仅仅是激发潜在能力仍是一个重要争论。本文提出了一种概率框架,将能力定义为实例级可解性。我们假设复杂推理的出现可以通过提高原子步骤概率来驱动,从而使模型克服多步骤推理链中固有的成功率指数衰减。通过Algebrarium框架,我们仅在单步骤操作上训练模型,并评估其在未见多步骤任务上的表现。实验证明,RLVR激励模型探索以前无法访问的解决路径,复合性能严格受原子步骤的联合概率控制,并且RLVR作为全局优化器,可能导致特定技能的牺牲以最大化总奖励。我们的工作为RLVR中的新兴能力提供了新解释,表明可解问题的迭代优化使模型能够发展应对以前无法解决场景的能力。
🔬 方法详解
问题定义:本文旨在解决在多步骤推理中,模型成功率因指数衰减而降低的问题。现有方法未能有效利用模型的潜在能力,导致复杂任务的解决能力不足。
核心思路:我们提出通过提高原子步骤的成功概率来驱动复杂推理的出现。该方法假设,模型在单步骤操作上的训练可以提升其在多步骤任务中的表现。
技术框架:整体架构包括单步骤操作的训练模块和多步骤任务的评估模块。模型首先在单步骤任务上进行训练,然后在未见的多步骤任务上进行性能评估。
关键创新:最重要的创新在于将能力定义为实例级可解性,并通过概率框架解释RLVR中推理能力的出现。这与传统方法的能力定义有所不同,强调了原子步骤的联合概率对复合性能的影响。
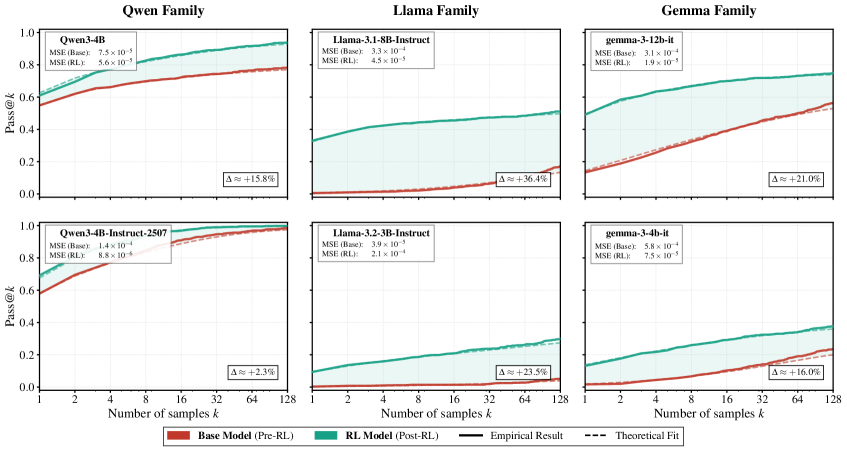
关键设计:在模型训练中,采用了特定的损失函数以优化原子步骤的成功概率,并通过高Pearson相关系数(ρ∈[0.69, 0.96])验证了复合性能与原子步骤的关系。
🖼️ 关键图片

📊 实验亮点
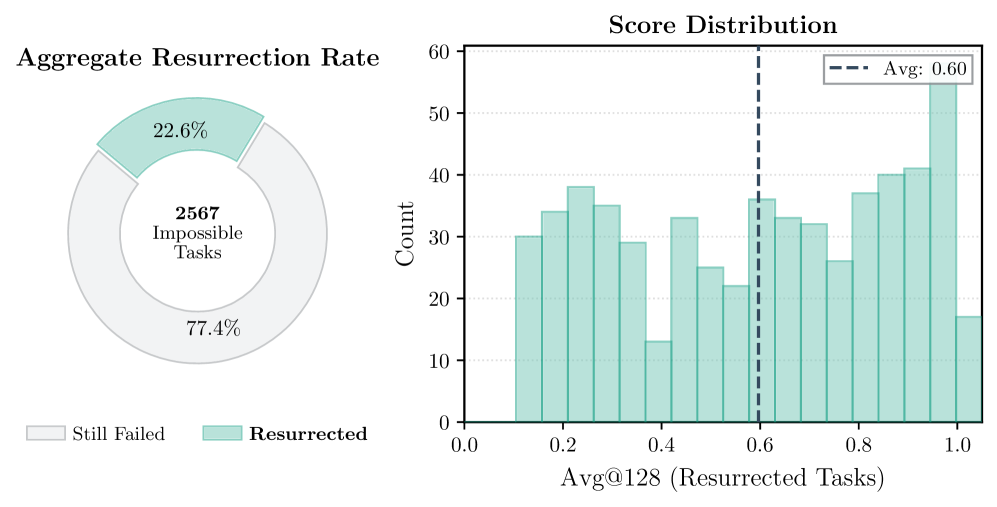
实验结果显示,RLVR显著提高了模型在未见多步骤任务上的表现,复合性能与原子步骤的联合概率之间的Pearson相关系数高达0.96,表明该方法有效促进了模型能力的提升。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理、智能问答系统和复杂决策支持系统。通过提升模型的推理能力,能够更好地解决复杂任务,具有重要的实际价值和未来影响。
📄 摘要(原文)
Whether Reinforcement Learning with Verifiable Rewards (RLVR) endows Large Language Models (LLMs) with new capabilities or merely elicits latent traces remains a central debate. In this work, we align with the former view, proposing a probabilistic framework where capability is defined by instance-level solvability. We hypothesize that the emergence of complex reasoning can be driven by sharpening atomic step probabilities, which enables models to overcome the exponential decay of success rates inherent in multi-step reasoning chains. Utilizing the Algebrarium framework, we train models exclusively on single-step operations and evaluate their performance on unseen multi-step tasks. Our empirical results confirm that: (1) RLVR incentivizes the exploration of previously inaccessible solution paths by amplifying the model's existing skills; (2) composite performance is strictly governed by the joint probability of atomic steps, evidenced by high Pearson correlation coefficients ($ρ\in [0.69, 0.96]$); and (3) RLVR, acting as a global optimizer, can cause specific skills to be sacrificed to maximize aggregate reward. Our work offers a novel explanation for emergent abilities in RLVR, suggesting that the iterative optimization of solvable problems enables models to develop the capabilities to tackle previously unsolvable scenarios.