Document Reconstruction Unlocks Scalable Long-Context RLVR
作者: Yao Xiao, Lei Wang, Yue Deng, Guanzheng Chen, Ziqi Jin, Jung-jae Kim, Xiaoli Li, Roy Ka-wei Lee, Lidong Bing
分类: cs.CL
发布日期: 2026-02-09
💡 一句话要点
提出基于文档重构的无监督RLVR方法,提升LLM长文本处理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本处理 强化学习 无监督学习 文档重构 语言模型 自监督学习 叙事连贯性
📋 核心要点
- 现有RLVR方法依赖于高质量的标注数据或强大的教师模型,成本高昂且耗时。
- 该论文提出一种基于文档重构的无监督强化学习方法,无需人工标注或教师模型。
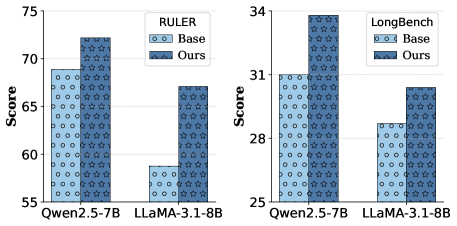
- 实验表明,该方法在RULER和LongBench~v2基准测试中均取得了显著或合理的性能提升。
📝 摘要(中文)
本文提出一种无监督方法,旨在提升大型语言模型(LLM)的长文本处理能力,无需人工标注或教师模型的监督。该方法通过在长文档中用占位符替换部分段落,然后利用强化学习训练LLM,使其能够从候选选项中正确识别并排序缺失的段落,从而重构文档。这种训练范式使模型能够捕捉全局叙事连贯性,显著提升长文本性能。在RULER和LongBench~v2两个基准测试中验证了该方法的有效性。在RULER上取得了显著收益,在LongBench~v2上实现了合理的改进,且无需任何手动策划的长文本问答数据。此外,还进行了广泛的消融研究,以分析奖励设计、数据管理策略、训练方案和数据缩放效应对模型性能的影响。代码、数据和模型已公开。
🔬 方法详解
问题定义:现有基于强化学习的语言模型长文本能力提升方法(RLVR)通常依赖于人工标注的黄金标准答案或强大的教师模型提供的显式评估规则。这些方法成本高昂,限制了其可扩展性。因此,需要一种无需人工干预或教师模型监督的无监督方法来提升LLM的长文本处理能力。
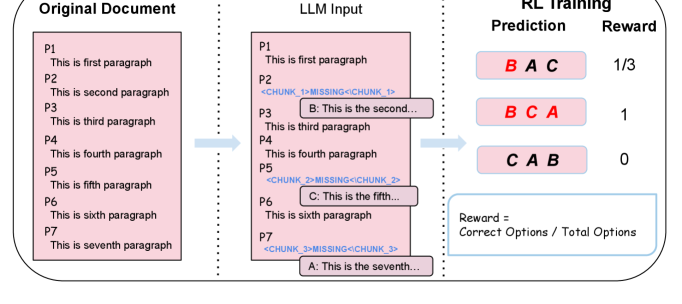
核心思路:论文的核心思路是利用文档重构任务作为自监督信号来训练LLM。具体来说,通过在长文档中随机遮蔽部分段落,并让模型学习从候选段落集合中恢复被遮蔽的内容,从而使模型能够捕捉文档的全局叙事连贯性。这种方式无需人工标注,可以大规模地利用现有的文本数据。
技术框架:整体框架包含以下几个主要步骤:1) 数据准备:从长文档中随机选择若干段落进行遮蔽,并构建包含正确段落和若干负样本的候选段落集合。2) 模型训练:使用强化学习训练LLM,目标是最大化模型正确选择被遮蔽段落的概率。奖励函数的设计至关重要,需要能够有效区分正确和错误的段落选择。3) 模型评估:在长文本基准测试中评估模型的性能,例如RULER和LongBench~v2。
关键创新:该方法最重要的创新点在于利用文档重构任务作为无监督的强化学习信号。与传统的监督学习或需要教师模型指导的强化学习方法不同,该方法完全依赖于数据本身的结构信息,无需任何人工标注或外部知识。这种自监督的方式具有更好的可扩展性和泛化能力。
关键设计:关键设计包括:1) 奖励函数的设计:如何设计奖励函数以鼓励模型选择正确的段落,并惩罚错误的选择?论文可能探索了不同的奖励函数形式,例如基于交叉熵损失的奖励、基于文本相似度的奖励等。2) 候选段落集合的构建:如何构建具有挑战性的候选段落集合,以迫使模型学习更强的区分能力?论文可能探索了不同的负样本采样策略。3) 训练方案:如何有效地训练模型,避免过拟合或训练不稳定?论文可能探索了不同的训练技巧,例如梯度裁剪、学习率衰减等。
🖼️ 关键图片

📊 实验亮点
该方法在RULER基准测试中取得了显著的性能提升,表明其能够有效捕捉文档的全局叙事连贯性。在LongBench~v2基准测试中,该方法也实现了合理的改进,证明了其在更复杂长文本任务中的有效性。值得注意的是,所有这些改进都是在没有使用任何手动标注的长文本问答数据的情况下实现的。
🎯 应用场景
该研究成果可广泛应用于需要处理长文本的场景,例如长篇小说续写、法律文档分析、金融报告解读、科研论文总结等。通过提升LLM的长文本处理能力,可以提高信息提取、问答、推理等任务的准确性和效率,具有重要的实际应用价值和商业前景。
📄 摘要(原文)
Reinforcement Learning with Verifiable Rewards~(RLVR) has become a prominent paradigm to enhance the capabilities (i.e.\ long-context) of Large Language Models~(LLMs). However, it often relies on gold-standard answers or explicit evaluation rubrics provided by powerful teacher models or human experts, which are costly and time-consuming. In this work, we investigate unsupervised approaches to enhance the long-context capabilities of LLMs, eliminating the need for heavy human annotations or teacher models' supervision. Specifically, we first replace a few paragraphs with special placeholders in a long document. LLMs are trained through reinforcement learning to reconstruct the document by correctly identifying and sequencing missing paragraphs from a set of candidate options. This training paradigm enables the model to capture global narrative coherence, significantly boosting long-context performance. We validate the effectiveness of our method on two widely used benchmarks, RULER and LongBench~v2. While acquiring noticeable gains on RULER, it can also achieve a reasonable improvement on LongBench~v2 without any manually curated long-context QA data. Furthermore, we conduct extensive ablation studies to analyze the impact of reward design, data curation strategies, training schemes, and data scaling effects on model performance. We publicly release our code, data, and models.