Pretraining with Token-Level Adaptive Latent Chain-of-Thought
作者: Boyi Zeng, Yiqin Hao, He Li, Shixiang Song, Feichen Song, Zitong Wang, Siyuan Huang, Yi Xu, ZiWei He, Xinbing Wang, Zhouhan Lin
分类: cs.CL
发布日期: 2026-02-09
💡 一句话要点
提出Token级自适应潜在CoT预训练方法,提升语言模型效率与性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 预训练 思维链 自适应计算 语言模型 计算效率
📋 核心要点
- 现有大语言模型依赖参数和数据规模扩展,但高质量语料库有限,通信成本高昂。
- 论文提出自适应潜在CoT,在token级别动态调整计算量,困难token分配更多计算资源。
- 实验表明,该方法在Llama架构上提升了困惑度和下游任务准确性,降低了计算成本。
📝 摘要(中文)
本文提出了一种Token级自适应潜在思维链(CoT)预训练方法,旨在通过在预训练中内化潜在的CoT,在不增加参数的情况下增加每个token的计算量。该方法为每个token生成一个可变长度的潜在CoT轨迹,为困难的token分配更长的轨迹,为简单的token分配更短的轨迹(甚至为零)。这种行为自然地从通用文本的单阶段预训练中产生,并通过token级别的自适应停止来减少训练和推理中的计算量。在Llama架构上的实验表明,自适应潜在CoT能够持续提高语言建模的困惑度和广泛的下游任务准确性,即使训练FLOPs少于先前的循环基线。
🔬 方法详解
问题定义:现有大语言模型主要通过增加参数量和训练数据来提升性能,但这种方式面临高质量语料库稀缺以及训练通信成本过高的挑战。因此,如何在不显著增加参数量的前提下,提升模型的性能和效率,是一个亟待解决的问题。
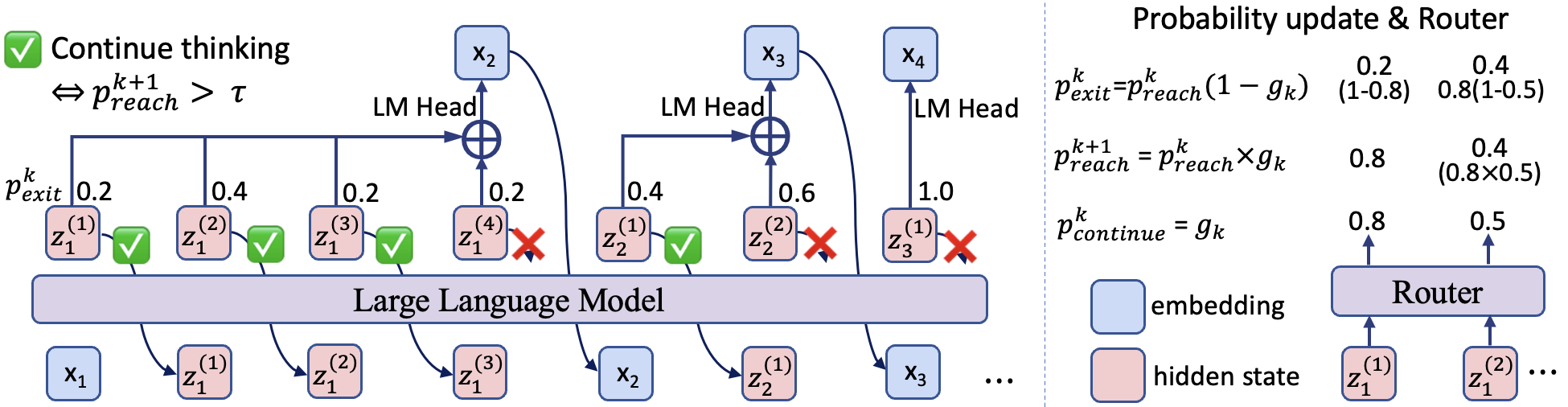
核心思路:论文的核心思路是在预训练阶段引入token级别的自适应潜在思维链(Chain-of-Thought, CoT)。模型在生成每个token之前,先生成一个可变长度的潜在CoT轨迹。对于需要更多推理步骤的“困难”token,模型生成更长的CoT轨迹;而对于简单的token,则生成较短甚至为零的CoT轨迹。这种自适应的计算分配方式,旨在提升模型的推理能力,同时避免不必要的计算开销。
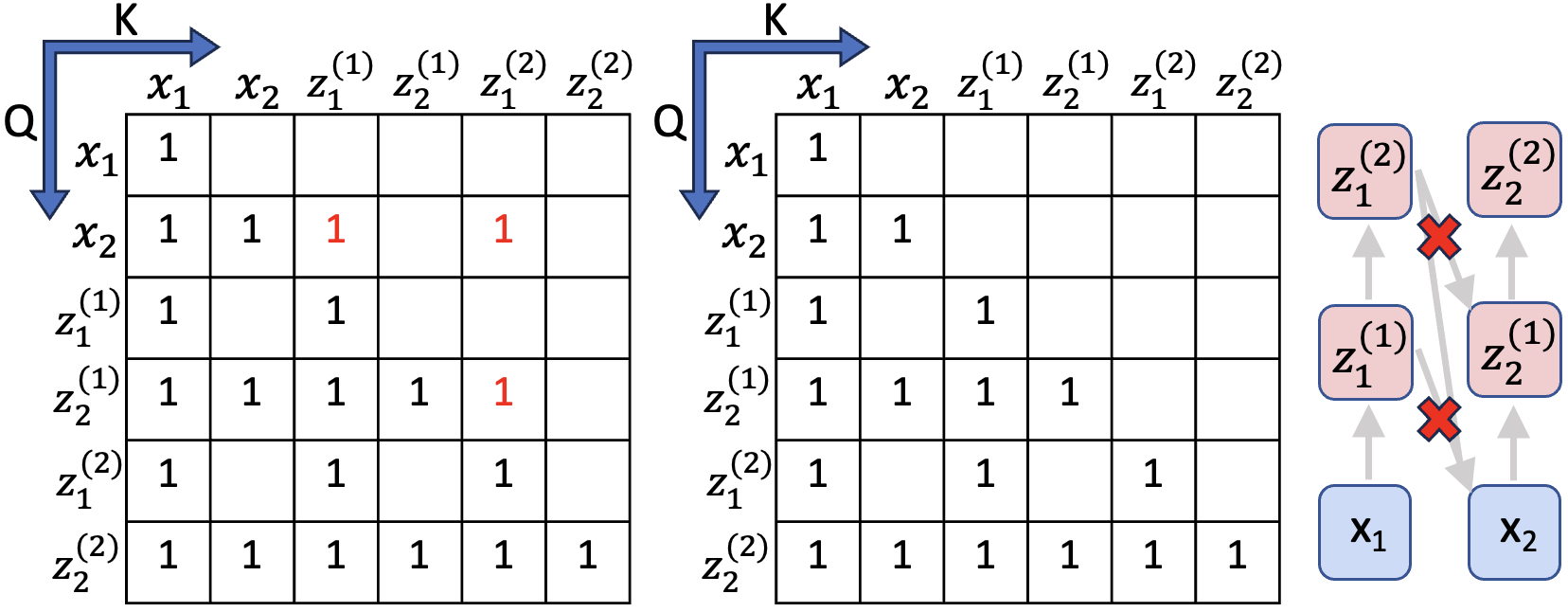
技术框架:该方法采用单阶段预训练框架,直接在通用文本上进行训练。模型在生成每个token时,首先通过一个策略网络(policy network)决定是否需要生成CoT轨迹,以及CoT轨迹的长度。然后,模型根据策略网络的决策,生成相应长度的CoT轨迹,并将CoT轨迹的信息融入到token的生成过程中。整个过程是端到端可训练的。
关键创新:该方法最重要的创新点在于token级别的自适应计算分配。与传统的固定计算量的方法不同,该方法能够根据token的难易程度动态调整计算量,从而更有效地利用计算资源。此外,该方法将CoT推理过程内化到预训练阶段,使得模型在下游任务中能够更好地利用CoT信息。
关键设计:策略网络的设计是关键。策略网络需要根据当前token的上下文信息,准确地预测是否需要生成CoT轨迹以及CoT轨迹的长度。论文中可能使用了强化学习或者监督学习的方法来训练策略网络。损失函数可能包括语言建模损失和策略网络的辅助损失,以鼓励策略网络做出合理的决策。具体的网络结构(例如,Transformer)和参数设置(例如,学习率、batch size)未知,需要查阅论文原文。
🖼️ 关键图片
📊 实验亮点
实验结果表明,自适应潜在CoT方法在Llama架构上取得了显著的性能提升。具体而言,该方法在语言建模任务中降低了困惑度,并在多个下游任务中提高了准确率。更重要的是,该方法在实现性能提升的同时,减少了训练所需的FLOPs,证明了其高效性。具体的性能提升幅度未知,需要查阅论文原文。
🎯 应用场景
该研究成果可应用于各种需要高效语言建模的场景,例如机器翻译、文本摘要、对话系统等。通过减少计算量,该方法有助于在资源受限的设备上部署大型语言模型,并降低训练和推理的成本。未来,该方法可以进一步扩展到其他模态,例如图像和语音,以提升多模态模型的效率和性能。
📄 摘要(原文)
Scaling large language models by increasing parameters and training data is increasingly constrained by limited high-quality corpora and rising communication costs. This work explores an alternative axis: increasing per-token computation without expanding parameters, by internalizing latent Chain-of-Thought (CoT) into pretraining. We propose Pretraining with Token-Level Adaptive Latent CoT (adaptive latent CoT), where the model generates a variable-length latent CoT trajectory before emitting each token -- allocating longer trajectories to difficult tokens and shorter (or even zero) trajectories to easy ones. Importantly, this behavior emerges naturally from one-stage pretraining on general text and reduces computation in both training and inference via token-wise adaptive halting. Experiments with Llama architectures show that adaptive latent CoT consistently improves language modeling perplexity and broad downstream accuracy, even with fewer training FLOPs than prior recurrent baselines.