LLMs and people both learn to form conventions -- just not with each other
作者: Cameron R. Jones, Agnese Lombardi, Kyle Mahowald, Benjamin K. Bergen
分类: cs.CL, cs.HC
发布日期: 2026-02-09
备注: 10 pages, 4 figures
💡 一句话要点
研究表明,大型语言模型与人类均能形成对话惯例,但无法在人机交互中有效建立
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 人机交互 对话惯例 多模态交流 提示工程
📋 核心要点
- 现有研究缺乏对人机交互中对话惯例形成的深入理解,阻碍了有效人机协作。
- 本研究通过多模态交流游戏,对比人-人、AI-AI和人-AI配对的对话惯例形成过程。
- 实验表明,LLM能独立形成对话惯例,但无法与人类有效建立,提示模仿人类行为也无法弥补。
📝 摘要(中文)
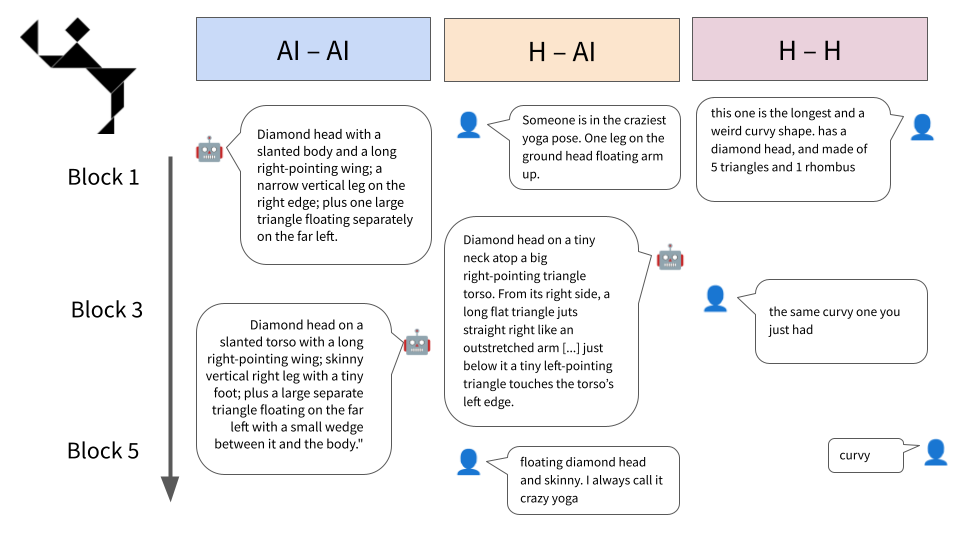
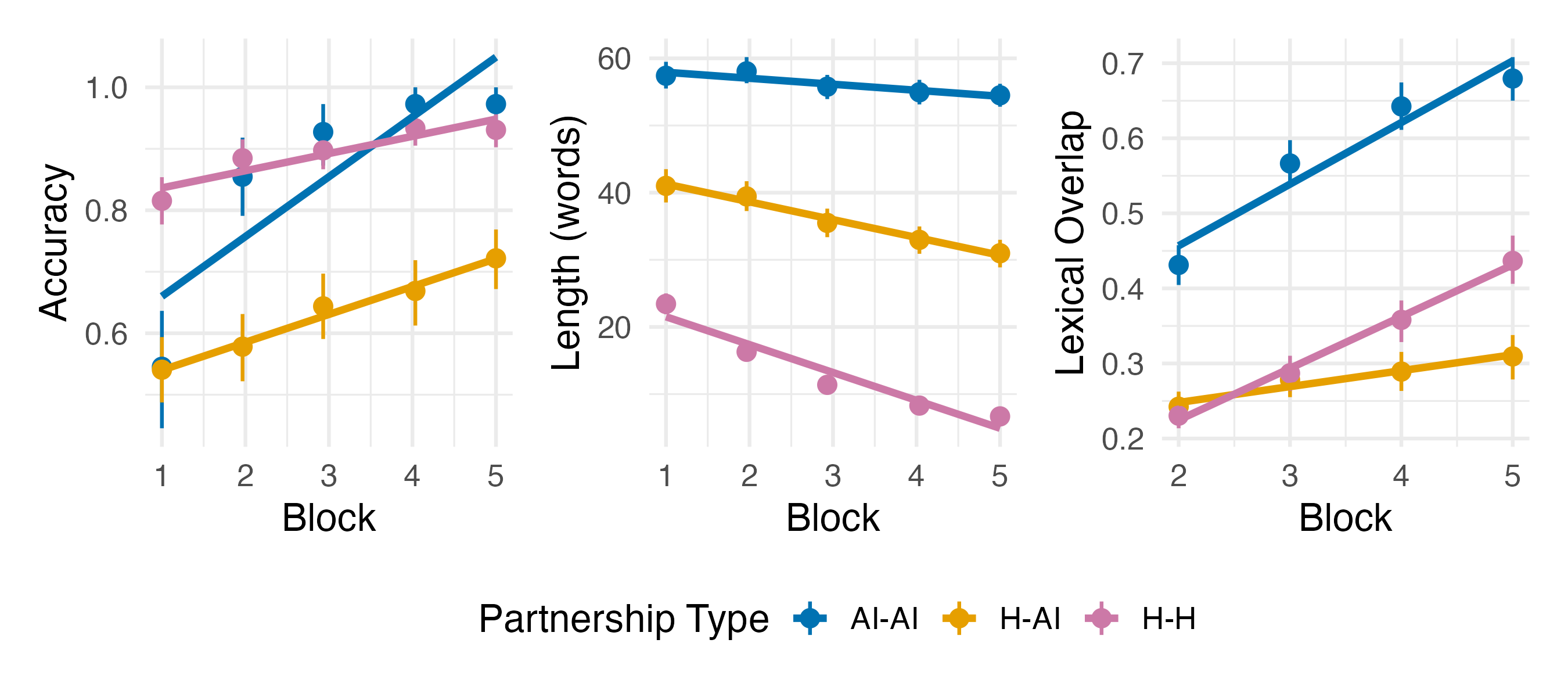
人类在对话中会彼此协调,形成共享的惯例以简化沟通。本研究测试了大型语言模型(LLM)是否能在多模态交流游戏中形成相同的惯例。结果表明,当同类型个体(人与人,AI与AI)进行交流时,人类和LLM都表现出惯例形成的迹象(提高准确性和一致性,同时缩短语句长度)。然而,在异构的人机配对中,这种惯例形成失败,表明两者在交流倾向方面存在差异。在第二个实验中,研究人员试图通过提示LLM产生表面上类似人类的行为,来诱导LLM表现得更像人类对话者。虽然人机配对的消息长度与人类配对的消息长度相匹配,但人机配对的准确性和词汇重叠仍然落后于人-人和AI-AI配对。这些结果表明,对话协调不仅需要模仿先前交互的能力,还需要对所传达含义的共享解释偏差。
🔬 方法详解
问题定义:本研究旨在探究大型语言模型(LLM)是否能在对话中像人类一样形成和遵循惯例,从而实现更有效的沟通。现有方法主要关注LLM的生成能力和对话流畅性,而忽略了对话惯例形成这一关键方面。人机交互中,由于缺乏共同的理解和交流模式,导致沟通效率低下,甚至产生误解。
核心思路:核心思路是通过设计一个多模态交流游戏,观察不同类型的对话配对(人-人、AI-AI、人-AI)在交流过程中的行为变化,从而判断惯例是否形成。通过对比不同配对的表现,揭示LLM在对话惯例形成方面的能力和局限性。此外,还尝试通过提示工程,诱导LLM模仿人类的交流方式,观察其对惯例形成的影响。
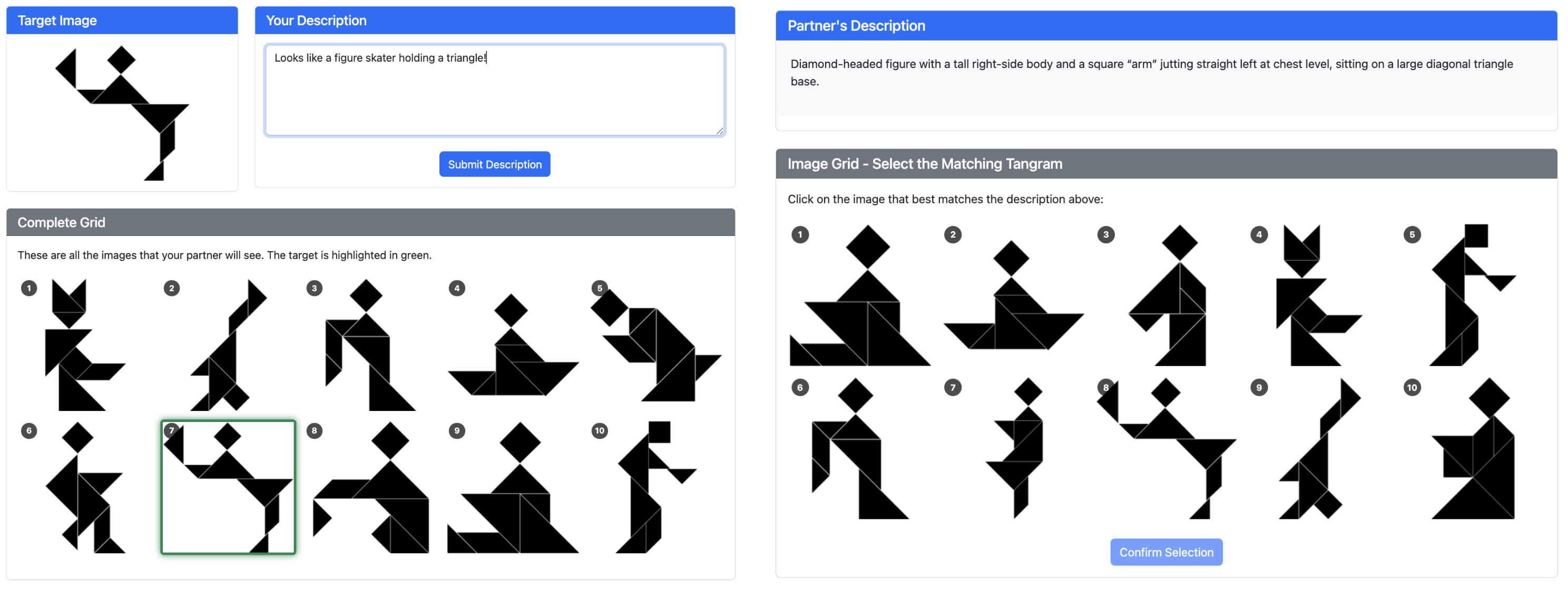
技术框架:研究采用了一个多模态交流游戏,参与者需要通过视觉信息和语言描述来协作完成任务。游戏流程包括:1) 参与者观察共享的视觉场景;2) 一方(发送者)用语言描述场景中的特定对象;3) 另一方(接收者)根据描述在场景中选择对应的对象;4) 系统反馈选择是否正确。通过多轮迭代,观察参与者在描述和选择过程中的准确性、一致性和语句长度的变化。
关键创新:本研究的关键创新在于:1) 将对话惯例形成这一概念引入到LLM的研究中,提出了一个新的视角;2) 通过实验对比了不同类型对话配对的惯例形成过程,揭示了LLM在人机交互中的局限性;3) 尝试通过提示工程来改善LLM的对话行为,为未来的人机交互研究提供了新的思路。
关键设计:实验中,LLM采用预训练的大型语言模型,并通过微调来适应特定的交流游戏。提示工程方面,采用了多种提示策略,例如要求LLM模仿人类的语言风格、使用更简洁的描述等。评估指标包括:1) 准确性(选择正确对象的比例);2) 一致性(描述同一对象时使用的词汇的相似度);3) 语句长度(描述的平均词数)。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在同类型配对中(人-人、AI-AI),准确性和一致性随对话轮数增加而提高,语句长度缩短,表明惯例形成。然而,在人-AI配对中,准确性和一致性显著低于同类型配对,即使通过提示工程诱导LLM模仿人类行为,也无法有效改善这一状况。人-AI配对的消息长度虽然与人-人配对相似,但准确率和词汇重叠率仍然较低。
🎯 应用场景
该研究成果可应用于改善人机对话系统,例如智能客服、虚拟助手等。通过使LLM能够更好地理解和适应人类的交流习惯,可以提高人机交互的效率和用户满意度。此外,该研究也为开发更自然、更智能的机器人提供了理论基础。
📄 摘要(原文)
Humans align to one another in conversation -- adopting shared conventions that ease communication. We test whether LLMs form the same kinds of conventions in a multimodal communication game. Both humans and LLMs display evidence of convention-formation (increasing the accuracy and consistency of their turns while decreasing their length) when communicating in same-type dyads (humans with humans, AI with AI). However, heterogenous human-AI pairs fail -- suggesting differences in communicative tendencies. In Experiment 2, we ask whether LLMs can be induced to behave more like human conversants, by prompting them to produce superficially humanlike behavior. While the length of their messages matches that of human pairs, accuracy and lexical overlap in human-LLM pairs continues to lag behind that of both human-human and AI-AI pairs. These results suggest that conversational alignment requires more than just the ability to mimic previous interactions, but also shared interpretative biases toward the meanings that are conveyed.