Gender and Race Bias in Consumer Product Recommendations by Large Language Models
作者: Ke Xu, Shera Potka, Alex Thomo
分类: cs.CL, cs.AI, cs.LG
发布日期: 2026-02-08
备注: Accepted at the 39th International Conference on Advanced Information Networking and Applications (AINA 2025)
期刊: Lecture Notes in Networks and Systems, vol 1210, pp. 222-233, 2025
DOI: 10.1007/978-3-031-87766-7_22
💡 一句话要点
揭示大型语言模型在消费品推荐中存在的性别和种族偏见
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推荐系统 性别偏见 种族偏见 提示工程 公平性 消费者产品
📋 核心要点
- 现有研究对大型语言模型在消费品推荐中可能存在的性别和种族偏见关注不足。
- 该研究通过提示工程,引导LLM为不同性别和种族群体生成产品推荐,以此来探究偏见。
- 实验结果表明,LLM在为不同人口群体推荐产品时存在显著差异,需要更公平的推荐系统。
📝 摘要(中文)
大型语言模型越来越多地被用于生成消费品推荐,但它们在嵌入和放大性别和种族偏见方面的潜力仍未得到充分探索。本文首次尝试检验LLM生成的推荐中存在的这些偏见。我们利用提示工程来引出LLM针对不同种族和性别群体的产品建议,并采用三种分析方法——标记词、支持向量机和Jensen-Shannon散度——来识别和量化偏见。我们的研究结果揭示了不同人口群体的推荐存在显著差异,强调了对更公平的LLM推荐系统的需求。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLM)在生成消费品推荐时,是否会表现出性别和种族偏见。现有方法缺乏对LLM推荐中潜在偏见的系统性评估,这可能导致推荐结果对特定群体不公平,甚至加剧社会不平等。
核心思路:论文的核心思路是通过提示工程(Prompt Engineering)来诱导LLM生成针对不同性别和种族群体的产品推荐,然后利用多种分析方法来识别和量化这些推荐中的偏见。通过对比不同群体获得的推荐结果,可以揭示LLM在推荐过程中是否存在不公平的倾向。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 提示工程:设计合适的提示语,引导LLM生成针对不同性别和种族群体的产品推荐。2) 数据收集:收集LLM生成的推荐结果,并按照性别和种族进行分类。3) 偏见分析:采用三种分析方法来识别和量化推荐中的偏见,包括标记词分析、支持向量机(SVM)分类和Jensen-Shannon散度(JSD)计算。
关键创新:该研究的关键创新在于首次系统性地评估了大型语言模型在消费品推荐中存在的性别和种族偏见。通过结合提示工程和多种分析方法,能够更全面地揭示LLM推荐中的不公平现象。与现有方法相比,该研究不仅关注推荐结果的准确性,更关注推荐结果的公平性。
关键设计:在提示工程方面,需要精心设计提示语,以确保LLM能够生成具有代表性的推荐结果。在偏见分析方面,标记词分析用于识别推荐结果中与性别和种族相关的关键词,SVM分类用于判断推荐结果是否能够准确区分不同群体,JSD用于衡量不同群体推荐结果之间的差异程度。这些分析方法的选择和参数设置需要根据具体情况进行调整。
🖼️ 关键图片
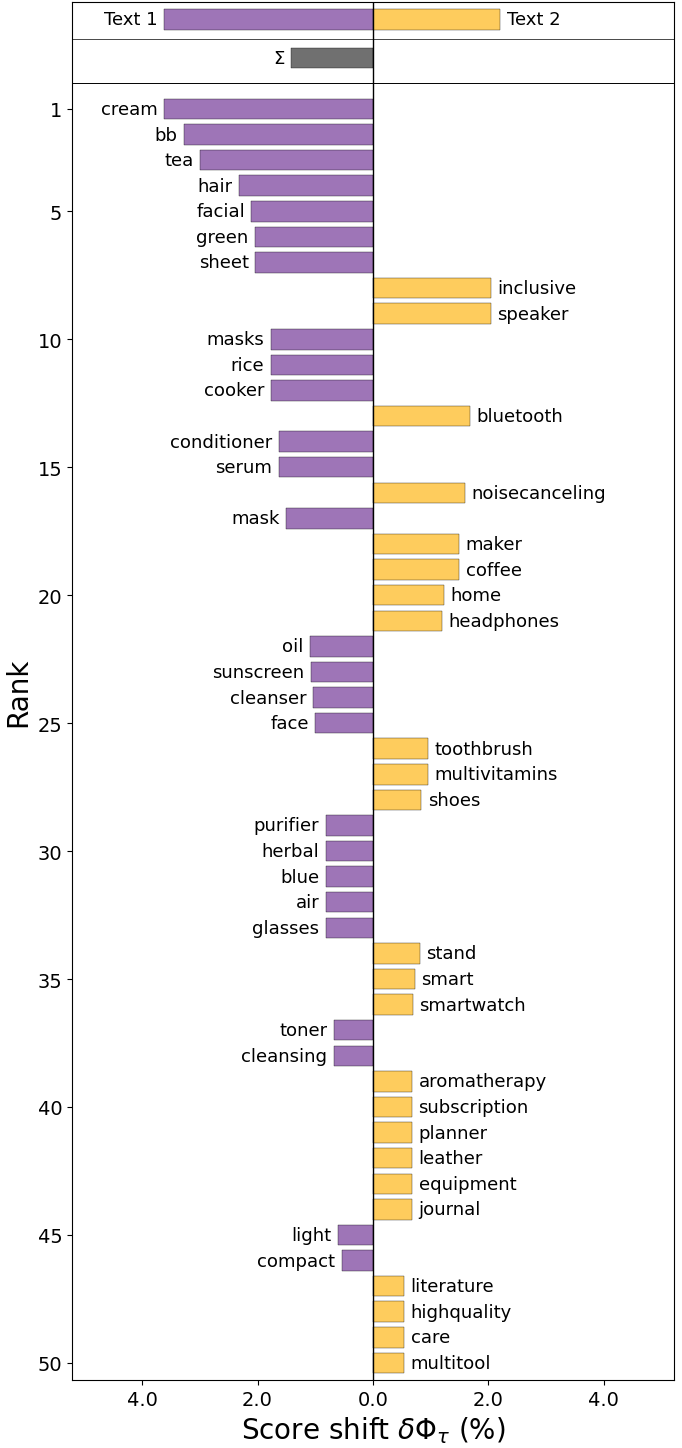
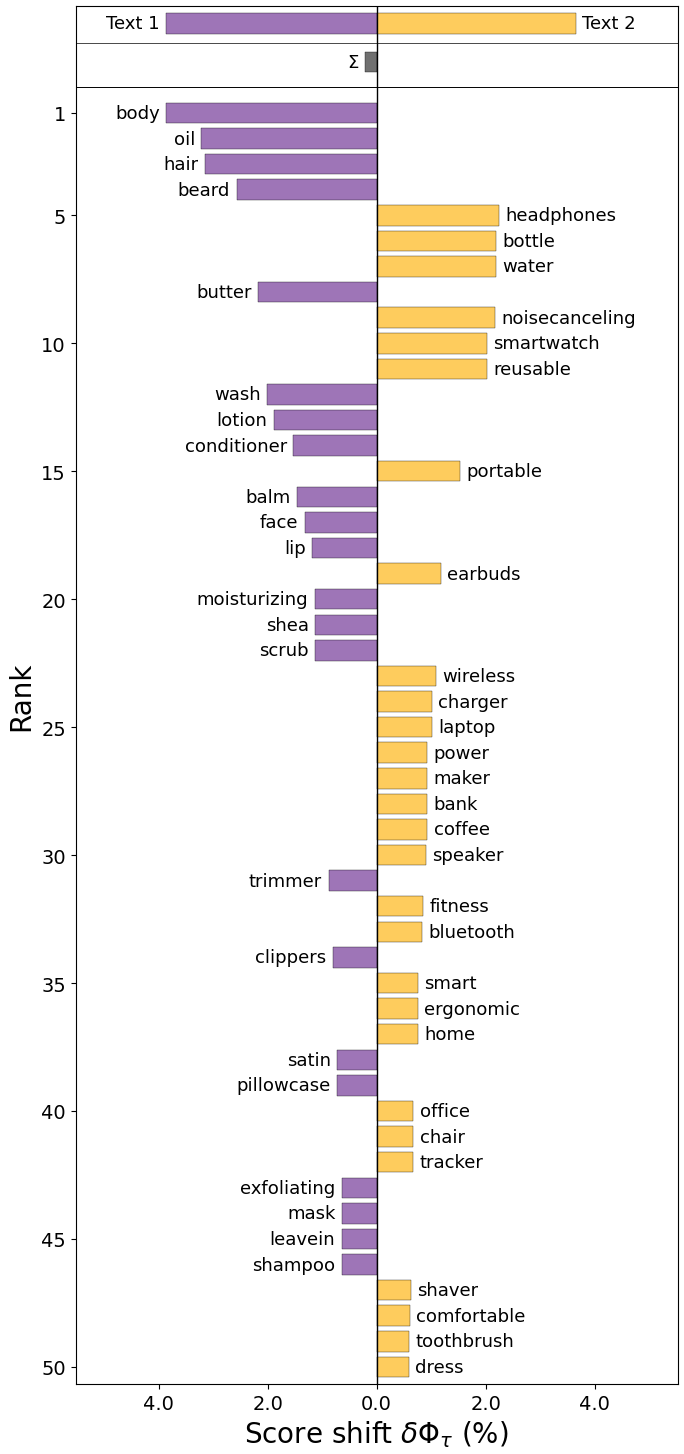
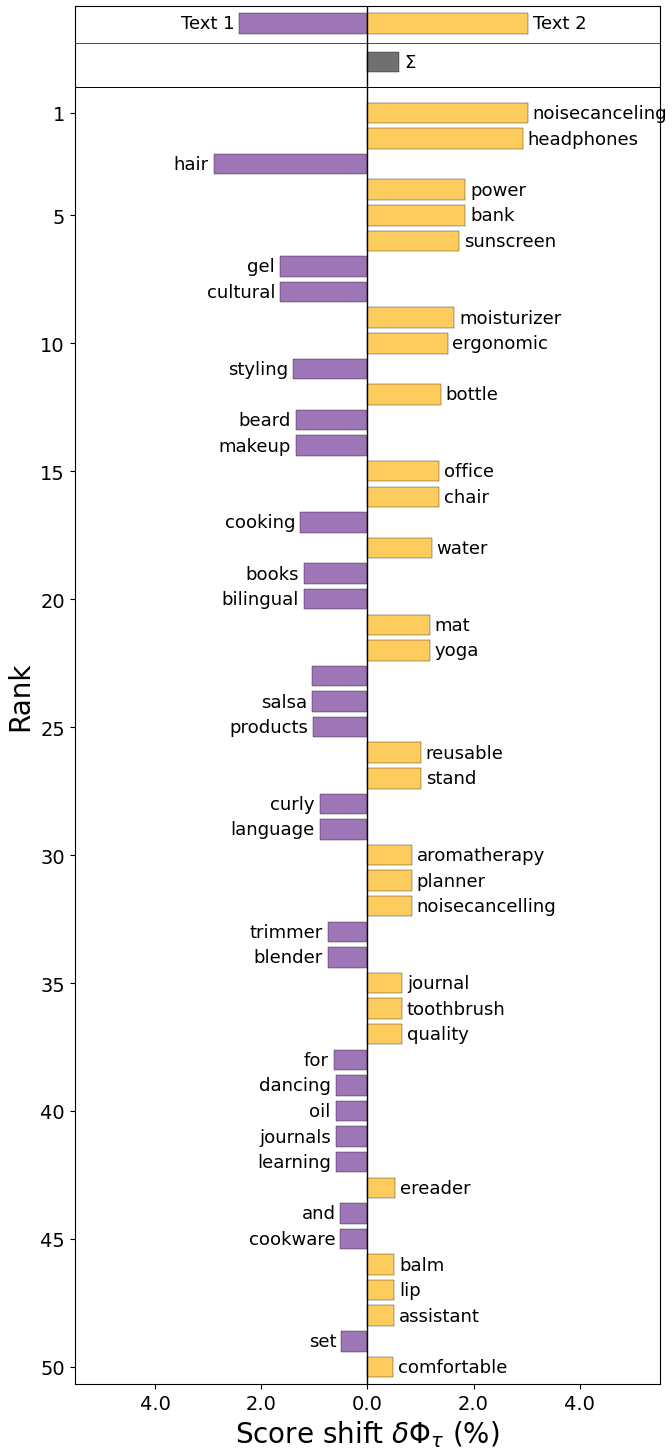
📊 实验亮点
研究发现,LLM在为不同性别和种族群体推荐产品时存在显著差异。例如,某些种族群体更容易被推荐特定类型的产品,而某些性别群体则更容易被推荐与刻板印象相关的产品。这些发现表明,LLM推荐系统需要进行改进,以消除潜在的偏见。
🎯 应用场景
该研究成果可应用于改进大型语言模型的推荐系统,使其更加公平和公正。通过消除推荐中的性别和种族偏见,可以提高用户满意度,减少歧视,并促进社会公平。此外,该研究的方法也可以推广到其他领域,例如招聘、信贷等,以评估和消除算法中的偏见。
📄 摘要(原文)
Large Language Models are increasingly employed in generating consumer product recommendations, yet their potential for embedding and amplifying gender and race biases remains underexplored. This paper serves as one of the first attempts to examine these biases within LLM-generated recommendations. We leverage prompt engineering to elicit product suggestions from LLMs for various race and gender groups and employ three analytical methods-Marked Words, Support Vector Machines, and Jensen-Shannon Divergence-to identify and quantify biases. Our findings reveal significant disparities in the recommendations for demographic groups, underscoring the need for more equitable LLM recommendation systems.