Emergent Search and Backtracking in Latent Reasoning Models
作者: Jasmine Cui, Charles Ye
分类: cs.CL, cs.AI
发布日期: 2026-02-08
💡 一句话要点
研究表明,隐式推理模型在潜在空间中涌现搜索和回溯能力,提升问答性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 隐式推理 潜在空间 搜索策略 回溯机制 Transformer 问答系统 自适应学习
📋 核心要点
- 现有推理LLM依赖显式的思维链,计算成本高且易出错,限制了其效率和泛化能力。
- 论文研究隐式推理模型,该模型在潜在空间中进行推理,无需显式的中间步骤。
- 实验表明,隐式推理模型自发学习搜索和回溯机制,显著提升多项选择问答任务的准确率。
📝 摘要(中文)
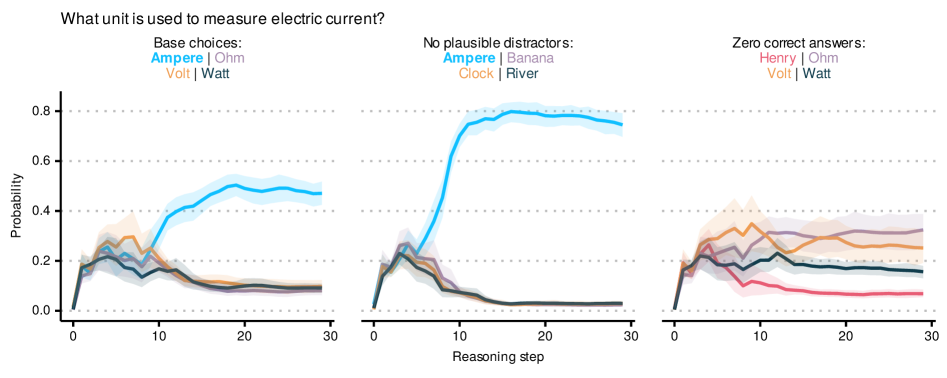
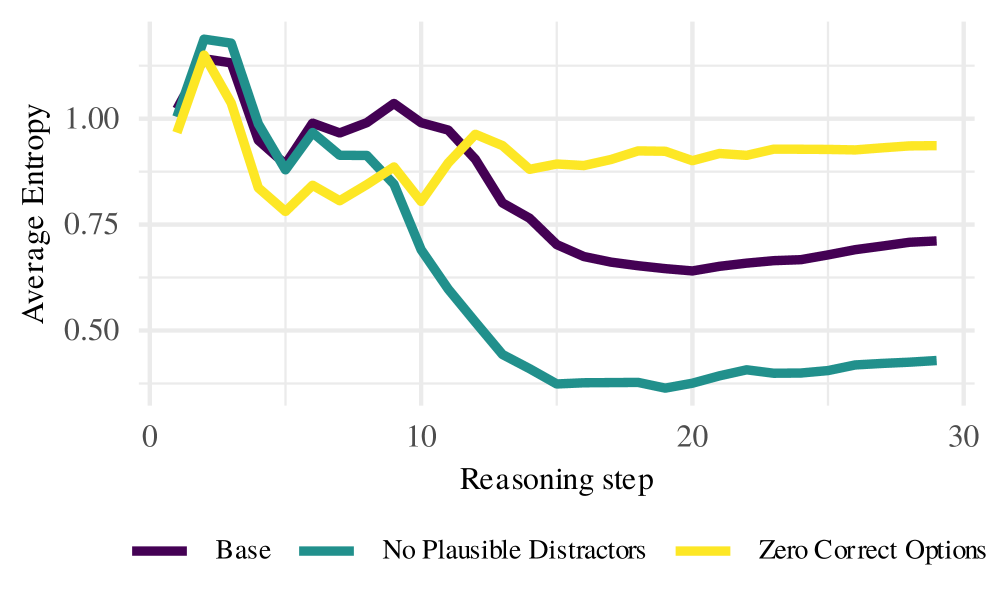
当语言模型在没有文字的情况下思考时会发生什么?标准的推理LLM将中间步骤表达为思维链;而隐式推理Transformer(LRT)则完全在连续隐藏空间中进行推理论证。我们研究了一个LRT,在多项选择QA基准测试中解码模型在每个步骤中不断演变的信念。我们发现该模型在潜在空间中自发地学习了一种结构化的搜索过程。推理论证遵循一致的轨迹:一个探索阶段,概率质量在候选答案中扩散;对领先者的初步承诺;以及收敛或回溯。回溯很普遍(32%的实例),有益(相对于非回溯实例,准确率提高34%),并且主要从语义上最接近的干扰项转向正确答案。搜索是自适应的:用不合理的替代方案替换干扰项可将探索缩短54%。隐式推理模型在激活空间中实现了思维链通过文字实现的效果:犯错、注意并恢复的能力。
🔬 方法详解
问题定义:现有的大型语言模型(LLMs)在进行复杂推理时,通常依赖于显式的“思维链”(Chain-of-Thought, CoT)方法,即逐步生成中间推理步骤。然而,这种方法存在一些痛点:一是计算成本高昂,因为需要生成大量的文本;二是容易出错,因为中间步骤的错误会累积并影响最终结果;三是泛化能力受限,因为模型可能过度依赖于特定的提示或格式。
核心思路:本论文的核心思路是探索一种“隐式推理”模型,即Latent Reasoning Transformer (LRT)。LRT不显式地生成中间推理步骤,而是在连续的潜在空间中进行推理论证。通过分析LRT在潜在空间中的行为,研究人员发现模型能够自发地学习到一种结构化的搜索过程,包括探索、承诺和回溯等阶段。这种隐式推理方式有望克服CoT方法的局限性,提高推理效率和鲁棒性。
技术框架:研究人员使用一个LRT模型,并在多项选择问答(QA)基准测试上对其进行评估。在每个推理步骤中,研究人员解码模型在潜在空间中的“信念”,即对每个候选答案的概率分布。通过分析这些概率分布的变化,研究人员可以观察到模型在潜在空间中的搜索过程。整个流程可以概括为:输入问题和候选答案 -> LRT在潜在空间中进行推理 -> 解码潜在空间中的信念 -> 分析信念的变化,识别探索、承诺和回溯等阶段 -> 输出最终答案。
关键创新:本论文最重要的技术创新点在于揭示了LRT模型在潜在空间中涌现出的搜索和回溯能力。与传统的CoT方法相比,LRT不需要显式地生成中间推理步骤,而是通过在潜在空间中的连续变换来实现推理。这种隐式推理方式更加高效和鲁棒,并且能够自适应地调整搜索策略。此外,研究人员还发现,LRT的回溯行为能够有效地纠正错误,从而提高推理准确率。
关键设计:论文的关键设计包括:1) 使用Transformer架构作为LRT的基础模型;2) 在多项选择QA任务上训练LRT;3) 设计一种解码方法,将潜在空间中的表示转换为对候选答案的概率分布;4) 定义了探索、承诺和回溯等阶段的指标,用于分析LRT在潜在空间中的行为;5) 通过替换干扰项来评估LRT的自适应搜索能力。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LRT模型在潜在空间中自发地学习了一种结构化的搜索过程,包括探索、承诺和回溯等阶段。回溯行为在32%的实例中出现,并且能够带来34%的准确率提升。此外,通过替换干扰项,研究人员发现LRT能够自适应地调整搜索策略,将探索时间缩短54%。
🎯 应用场景
该研究成果可应用于各种需要复杂推理的任务,例如智能客服、自动驾驶和医疗诊断。通过利用隐式推理模型,可以提高这些应用在复杂环境下的决策能力和鲁棒性。未来,该研究方向有望推动通用人工智能的发展,使机器能够像人类一样进行高效、灵活的推理。
📄 摘要(原文)
What happens when a language model thinks without words? Standard reasoning LLMs verbalize intermediate steps as chain-of-thought; latent reasoning transformers (LRTs) instead perform deliberation entirely in continuous hidden space. We investigate an LRT, decoding the model's evolving beliefs at every step on a multiple-choice QA benchmark. We find that the model spontaneously learns a structured search process in latent space. Deliberation follows a consistent trajectory: an exploration phase where probability mass spreads across candidates, tentative commitment to a frontrunner, and either convergence or backtracking. Backtracking is prevalent (32% of instances), beneficial (34% accuracy gain over non-backtracking instances), and predominantly directed away from the semantically closest distractor toward the correct answer. The search is adaptive: replacing distractors with implausible alternatives shortens exploration by 54%. Latent reasoning models achieve in activation space what chain-of-thought achieves through words: the ability to be wrong, notice, and recover.