Diverge to Induce Prompting: Multi-Rationale Induction for Zero-Shot Reasoning
作者: Po-Chun Chen, Hen-Hsen Huang, Hsin-Hsi Chen
分类: cs.CL
发布日期: 2026-02-08
备注: Accepted to Findings of IJCNLP-AACL 2025
💡 一句话要点
DIP:发散诱导提示,通过多策略归纳提升零样本推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 零样本推理 思维链提示 大型语言模型 多策略归纳 提示工程
📋 核心要点
- 现有思维链方法依赖单一推理策略,限制了LLM在复杂任务中的表现。
- DIP框架通过生成多个理由并归纳为最终计划,提升推理的稳定性和准确性。
- 实验结果表明,DIP在零样本推理任务中优于单策略提示方法。
📝 摘要(中文)
为了解决标准思维链提示中无引导推理路径的不稳定性,现有方法通常引导大型语言模型(LLMs)首先引出一个单一的推理策略。然而,仅仅依赖于每个问题的单一策略可能会限制跨多样化任务的性能。我们提出了发散诱导提示(DIP),该框架首先提示LLM为每个问题生成多个不同的高层次理由。然后,将每个理由细化成详细的、逐步的草案计划。最后,将这些草案计划归纳成最终计划。DIP增强了零样本推理的准确性,而无需依赖资源密集型采样。实验表明,DIP优于单策略提示,证明了多计划归纳对于基于提示的推理的有效性。
🔬 方法详解
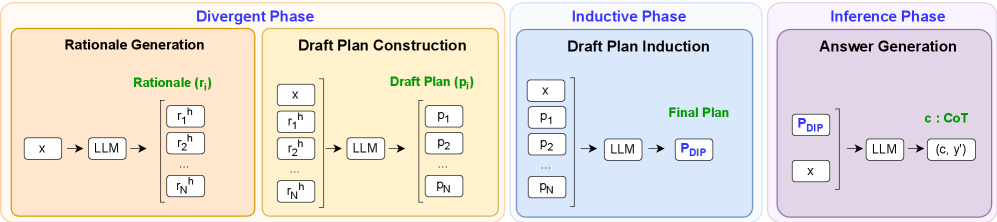
问题定义:论文旨在解决大型语言模型在零样本推理任务中,由于标准思维链提示方法依赖单一推理路径而导致的不稳定性和性能瓶颈问题。现有方法往往只引导LLM生成一个推理策略,这限制了模型探索多种可能的解决方案,尤其是在复杂和多样化的任务中。
核心思路:DIP的核心思路是“发散-归纳”。首先,鼓励LLM针对每个问题生成多个不同的、高层次的理由(rationales),从而扩展搜索空间。然后,将每个理由细化为详细的步骤计划,最后将这些计划归纳整合为一个更全面、更可靠的最终计划。这种多策略融合的方式旨在提高推理的鲁棒性和准确性。
技术框架:DIP框架包含三个主要阶段:1) 理由发散(Rationale Divergence):使用提示工程,引导LLM生成多个针对同一问题的不同理由。2) 计划细化(Plan Elaboration):将每个理由进一步细化为详细的、逐步的草案计划。3) 计划归纳(Plan Induction):将多个草案计划归纳整合为一个最终的、更全面的推理计划。
关键创新:DIP的关键创新在于其“发散-归纳”的框架,它不同于以往依赖单一推理路径的方法。通过鼓励LLM探索多种可能的推理策略,并将其整合为一个最终计划,DIP能够更有效地利用LLM的知识和推理能力,从而提高零样本推理的性能。
关键设计:DIP的关键设计在于提示工程的设计,如何有效地引导LLM生成多样化的理由是至关重要的。此外,如何将多个草案计划有效地归纳为一个最终计划也是一个关键的技术挑战。论文中可能涉及一些启发式规则或简单的融合策略来实现计划的归纳,但具体细节未知。
🖼️ 关键图片


📊 实验亮点
论文通过实验证明了DIP方法在零样本推理任务中的有效性。DIP优于依赖单一策略的提示方法,表明多计划归纳能够显著提升基于提示的推理性能。具体的性能提升幅度未知,但摘要强调了DIP的优越性,说明其在实验中取得了显著的成果。
🎯 应用场景
DIP方法可以应用于各种需要复杂推理的任务,例如常识推理、数学问题求解、代码生成等。该方法通过提升零样本推理能力,降低了对大量标注数据的依赖,有助于在资源受限的场景下部署和应用大型语言模型。未来,DIP可以进一步扩展到其他模态,例如视觉推理和多模态推理。
📄 摘要(原文)
To address the instability of unguided reasoning paths in standard Chain-of-Thought prompting, recent methods guide large language models (LLMs) by first eliciting a single reasoning strategy. However, relying on just one strategy for each question can still limit performance across diverse tasks. We propose Diverge-to-Induce Prompting (DIP), a framework that first prompts an LLM to generate multiple diverse high-level rationales for each question. Each rationale is then elaborated into a detailed, step-by-step draft plan. Finally, these draft plans are induced into a final plan. DIP enhances zero-shot reasoning accuracy without reliance on resource-intensive sampling. Experiments show that DIP outperforms single-strategy prompting, demonstrating the effectiveness of multi-plan induction for prompt-based reasoning.