Cross-Linguistic Persona-Driven Data Synthesis for Robust Multimodal Cognitive Decline Detection
作者: Rui Feng, Zhiyao Luo, Liuyu Wu, Wei Wang, Yuting Song, Yong Liu, Kok Pin Ng, Jianqing Li, Xingyao Wang
分类: cs.CL
发布日期: 2026-02-08
备注: 18 pages, 7 figures, 6 tables
💡 一句话要点
SynCog:跨语言的、基于人物驱动的数据合成,用于稳健的多模态认知衰退检测
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 认知衰退检测 多模态学习 数据合成 思维链 跨语言学习 语音识别 自然语言处理
📋 核心要点
- 现有语音认知障碍诊断模型面临临床数据稀缺、跨语言泛化能力弱和缺乏可解释性的挑战。
- SynCog框架通过可控的零样本多模态数据合成,模拟不同认知特征的虚拟受试者,扩充训练数据。
- 实验表明,SynCog在多个数据集上取得了优异的诊断性能,并展现出良好的跨语言泛化能力。
📝 摘要(中文)
本文提出SynCog框架,旨在解决轻度认知障碍(MCI)早期识别中,基于语音的数字生物标志物所面临的临床数据稀缺和缺乏可解释推理的问题。SynCog集成了可控的零样本多模态数据合成与思维链(CoT)演绎微调。通过模拟具有不同认知特征的虚拟受试者,有效缓解数据稀缺。该生成范式实现了跨语言临床语料库的快速零样本扩展,克服了低资源环境下的数据瓶颈,提升了多模态大语言模型(MLLM)的诊断性能。利用合成数据集,使用CoT演绎策略微调多模态骨干模型,使其能够清晰表达诊断过程,而非依赖黑盒预测。在ADReSS和ADReSSo基准测试中,使用合成表型增强有限的临床数据,获得了具有竞争力的诊断性能,Macro-F1分别达到80.67%和78.46%,优于现有基线模型。在独立的真实世界普通话队列(CIR-E)上的评估表明,该方法具有强大的跨语言泛化能力,Macro-F1达到48.71%。
🔬 方法详解
问题定义:目前基于语音的认知衰退检测方法受限于临床数据的稀缺,尤其是在低资源语言中。此外,现有模型通常是黑盒模型,缺乏可解释性,难以获得临床信任。跨语言泛化能力也是一个挑战,因为不同语言的语音特征和表达方式存在差异。
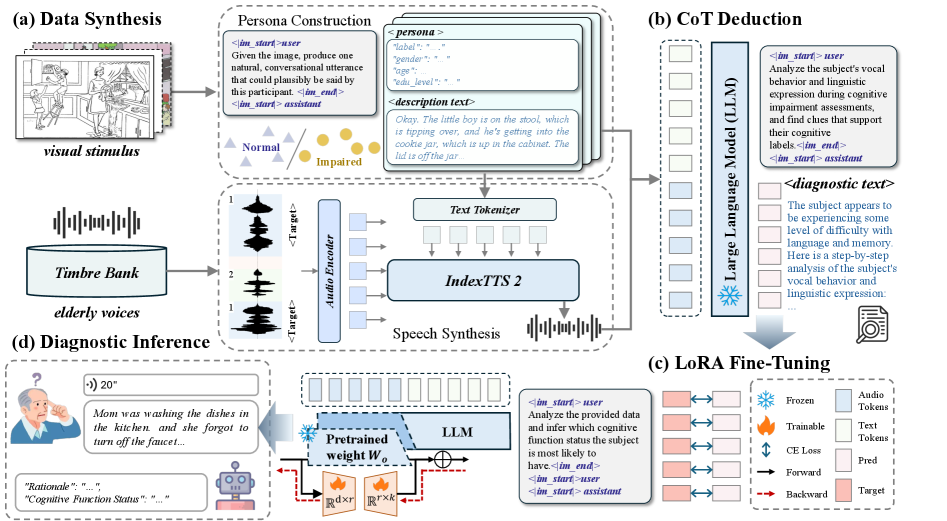
核心思路:SynCog的核心思路是利用可控的生成模型合成具有不同认知特征的虚拟受试者数据,从而缓解数据稀缺问题。通过思维链(CoT)微调,使模型能够显式地推理诊断过程,提高可解释性。同时,利用多模态信息(例如语音和文本)来提高模型的鲁棒性和泛化能力。
技术框架:SynCog框架主要包含两个阶段:数据合成阶段和模型微调阶段。在数据合成阶段,利用生成模型(具体模型类型未知)生成具有不同认知特征的语音和文本数据。在模型微调阶段,使用合成数据和少量真实数据,对多模态大语言模型进行微调,采用CoT策略,使模型能够输出推理过程。
关键创新:SynCog的关键创新在于:1) 提出了一种基于人物驱动的数据合成方法,能够有效地扩充临床数据,尤其是在低资源语言中。2) 结合CoT微调策略,提高了模型的可解释性,使其能够输出诊断推理过程。3) 实现了跨语言的认知衰退检测,提高了模型的泛化能力。
关键设计:论文中未明确给出生成模型的具体类型和参数设置,以及CoT微调的具体实现细节(例如prompt的设计、损失函数等)。这些是需要进一步研究的未知细节。
🖼️ 关键图片
📊 实验亮点
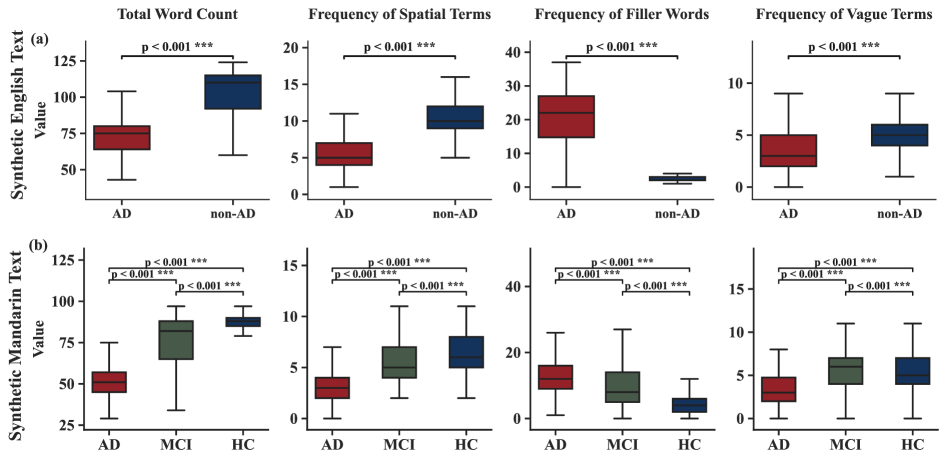
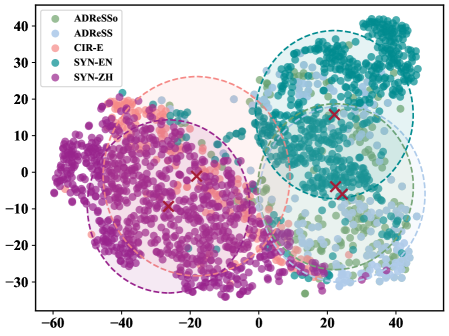
SynCog在ADReSS和ADReSSo基准测试中取得了显著的性能提升,Macro-F1分别达到80.67%和78.46%,优于现有基线模型。更重要的是,SynCog在独立的真实世界普通话队列(CIR-E)上展现出强大的跨语言泛化能力,Macro-F1达到48.71%,证明了其在实际应用中的潜力。
🎯 应用场景
SynCog框架可应用于早期认知障碍的筛查和诊断,尤其是在医疗资源匮乏的地区和低资源语言环境中。该技术能够降低诊断成本,提高诊断效率,并为临床医生提供可解释的诊断依据。未来,该技术有望推广到其他神经退行性疾病的早期诊断和监测。
📄 摘要(原文)
Speech-based digital biomarkers represent a scalable, non-invasive frontier for the early identification of Mild Cognitive Impairment (MCI). However, the development of robust diagnostic models remains impeded by acute clinical data scarcity and a lack of interpretable reasoning. Current solutions frequently struggle with cross-lingual generalization and fail to provide the transparent rationales essential for clinical trust. To address these barriers, we introduce SynCog, a novel framework integrating controllable zero-shot multimodal data synthesis with Chain-of-Thought (CoT) deduction fine-tuning. Specifically, SynCog simulates diverse virtual subjects with varying cognitive profiles to effectively alleviate clinical data scarcity. This generative paradigm enables the rapid, zero-shot expansion of clinical corpora across diverse languages, effectively bypassing data bottlenecks in low-resource settings and bolstering the diagnostic performance of Multimodal Large Language Models (MLLMs). Leveraging this synthesized dataset, we fine-tune a foundational multimodal backbone using a CoT deduction strategy, empowering the model to explicitly articulate diagnostic thought processes rather than relying on black-box predictions. Extensive experiments on the ADReSS and ADReSSo benchmarks demonstrate that augmenting limited clinical data with synthetic phenotypes yields competitive diagnostic performance, achieving Macro-F1 scores of 80.67% and 78.46%, respectively, outperforming current baseline models. Furthermore, evaluation on an independent real-world Mandarin cohort (CIR-E) demonstrates robust cross-linguistic generalization, attaining a Macro-F1 of 48.71%. These findings constitute a critical step toward providing clinically trustworthy and linguistically inclusive cognitive assessment tools for global healthcare.