Lost in Translation? A Comparative Study on the Cross-Lingual Transfer of Composite Harms
作者: Vaibhav Shukla, Hardik Sharma, Adith N Reganti, Soham Wasmatkar, Bagesh Kumar, Vrijendra Singh
分类: cs.CL, cs.AI
发布日期: 2026-02-08
备注: Accepted at the AICS Workshop, AAAI 2026
💡 一句话要点
提出CompositeHarm基准,评估LLM在跨语言场景下复合危害的迁移能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 跨语言迁移学习 大型语言模型安全 对抗攻击 多语言评估 复合危害 低资源语言 安全基准
📋 核心要点
- 现有LLM安全评估主要集中于英语,翻译方法难以捕捉跨语言场景下的危害迁移。
- 提出CompositeHarm基准,结合对抗攻击和真实世界危害,扩展到多种印度语言。
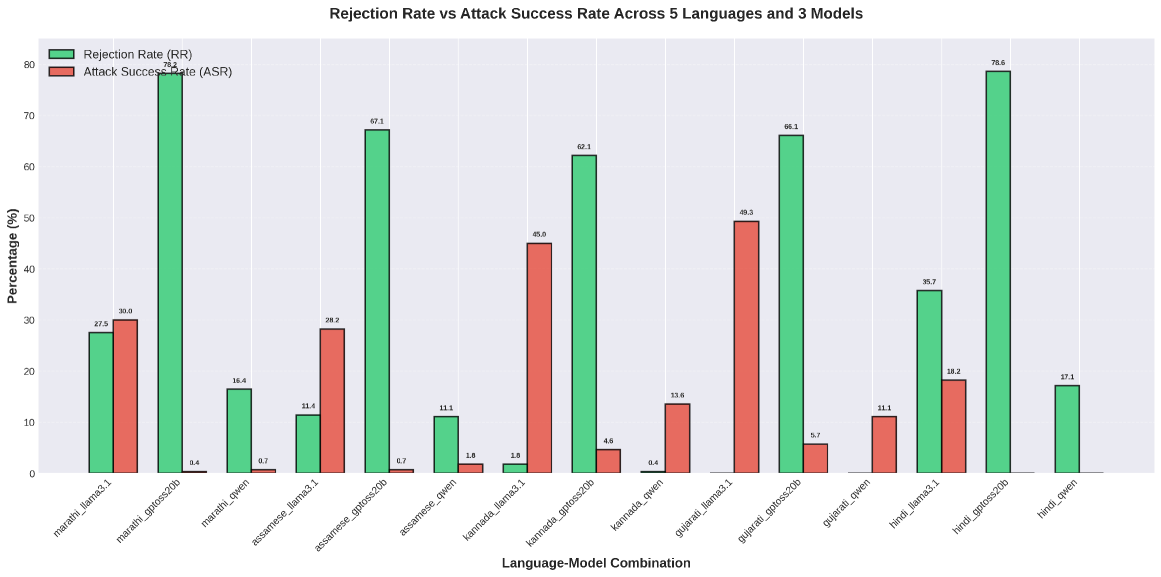
- 实验表明,对抗攻击在印度语言中成功率显著提高,凸显跨语言安全评估的重要性。
📝 摘要(中文)
大型语言模型(LLM)的安全评估主要集中在英语上。翻译常被用作探索多语言行为的捷径,但它很少能捕捉到全貌,尤其是在有害意图或结构跨语言变形时。某些类型的危害在翻译后几乎完整保留,而另一些则扭曲或消失。为了研究这种效应,我们引入了CompositeHarm,这是一个基于翻译的基准,旨在检验安全对齐在语法和语义变化时的表现。它结合了两个互补的英语数据集AttaQ(针对结构化对抗攻击)和MMSafetyBench(涵盖上下文相关的真实世界危害),并将它们扩展到六种语言:英语、印地语、阿萨姆语、马拉地语、卡纳达语和古吉拉特语。使用三个大型模型,我们发现攻击成功率在印度语言中急剧上升,尤其是在对抗性语法下,而上下文危害的迁移则较为缓和。为了确保可扩展性和能源效率,我们的研究采用了受边缘AI设计原则启发的轻量级推理策略,减少了冗余的评估过程,同时保持了跨语言的保真度。这种设计使得大规模多语言安全测试在计算上可行且具有环保意识。总的来说,我们的结果表明,翻译后的基准是构建基于实际、资源感知、语言自适应安全系统的必要的第一步,但还不够充分。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在跨语言场景下的安全评估问题。现有的安全评估方法主要集中在英语上,并且依赖于翻译来评估LLM在其他语言中的安全性。然而,翻译过程可能会改变或丢失原始文本中的有害信息,导致评估结果不准确。此外,不同语言的语法和语义结构差异很大,这使得跨语言的安全评估更具挑战性。
核心思路:论文的核心思路是构建一个基于翻译的复合危害基准(CompositeHarm),该基准结合了结构化对抗攻击和上下文相关的真实世界危害,并将其扩展到多种语言。通过评估LLM在不同语言和不同危害类型下的表现,可以更全面地了解LLM的跨语言安全风险。此外,论文还采用了轻量级的推理策略,以提高评估的可扩展性和能源效率。
技术框架:CompositeHarm基准的构建流程如下:首先,选择两个互补的英语数据集AttaQ和MMSafetyBench,分别代表结构化对抗攻击和上下文相关的真实世界危害。然后,将这两个数据集翻译成六种语言:英语、印地语、阿萨姆语、马拉地语、卡纳达语和古吉拉特语。接下来,使用这六种语言的数据集对三个大型语言模型进行安全评估。最后,分析评估结果,比较LLM在不同语言和不同危害类型下的表现。为了提高评估效率,论文采用了轻量级的推理策略,减少了冗余的评估过程。
关键创新:论文的关键创新点在于提出了CompositeHarm基准,该基准结合了结构化对抗攻击和上下文相关的真实世界危害,并将其扩展到多种语言。与现有的安全评估方法相比,CompositeHarm基准能够更全面地评估LLM的跨语言安全风险。此外,论文还采用了轻量级的推理策略,以提高评估的可扩展性和能源效率。
关键设计:CompositeHarm基准的关键设计包括:1) 选择具有互补性的英语数据集AttaQ和MMSafetyBench;2) 将数据集翻译成多种语言,特别是印度语言,以覆盖不同的语法和语义结构;3) 采用轻量级的推理策略,例如减少冗余的评估过程,以提高评估效率。具体的轻量级推理策略细节未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在印度语言中,LLM对抗攻击的成功率显著高于英语,尤其是在对抗性语法结构下。而上下文相关的危害迁移相对缓和。这表明简单的翻译方法可能无法充分揭示LLM在不同语言中的安全风险,需要更精细的跨语言安全评估方法。
🎯 应用场景
该研究成果可应用于提升多语言大型语言模型的安全性,尤其是在低资源语言场景下。通过CompositeHarm基准,开发者可以更有效地识别和缓解LLM在不同语言中的潜在危害,从而构建更安全、可靠的跨语言人工智能系统。该研究还有助于推动资源节约型AI设计,降低大规模安全测试的计算成本。
📄 摘要(原文)
Most safety evaluations of large language models (LLMs) remain anchored in English. Translation is often used as a shortcut to probe multilingual behavior, but it rarely captures the full picture, especially when harmful intent or structure morphs across languages. Some types of harm survive translation almost intact, while others distort or disappear. To study this effect, we introduce CompositeHarm, a translation-based benchmark designed to examine how safety alignment holds up as both syntax and semantics shift. It combines two complementary English datasets, AttaQ, which targets structured adversarial attacks, and MMSafetyBench, which covers contextual, real-world harms, and extends them into six languages: English, Hindi, Assamese, Marathi, Kannada, and Gujarati. Using three large models, we find that attack success rates rise sharply in Indic languages, especially under adversarial syntax, while contextual harms transfer more moderately. To ensure scalability and energy efficiency, our study adopts lightweight inference strategies inspired by edge-AI design principles, reducing redundant evaluation passes while preserving cross-lingual fidelity. This design makes large-scale multilingual safety testing both computationally feasible and environmentally conscious. Overall, our results show that translated benchmarks are a necessary first step, but not a sufficient one, toward building grounded, resource-aware, language-adaptive safety systems.