Patches of Nonlinearity: Instruction Vectors in Large Language Models
作者: Irina Bigoulaeva, Jonas Rohweder, Subhabrata Dutta, Iryna Gurevych
分类: cs.CL
发布日期: 2026-02-08
💡 一句话要点
揭示大语言模型指令向量:非线性交互与电路选择机制
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 指令调优 机制可解释性 因果中介分析 非线性交互
📋 核心要点
- 现有指令调优语言模型内部处理指令的方式仍然是黑盒,缺乏深入的机制理解。
- 通过因果中介分析和新颖的非线性信息定位方法,揭示指令向量的局部性和电路选择特性。
- 发现指令向量同时具备线性可分性和非线性因果交互,挑战了线性表征假设。
📝 摘要(中文)
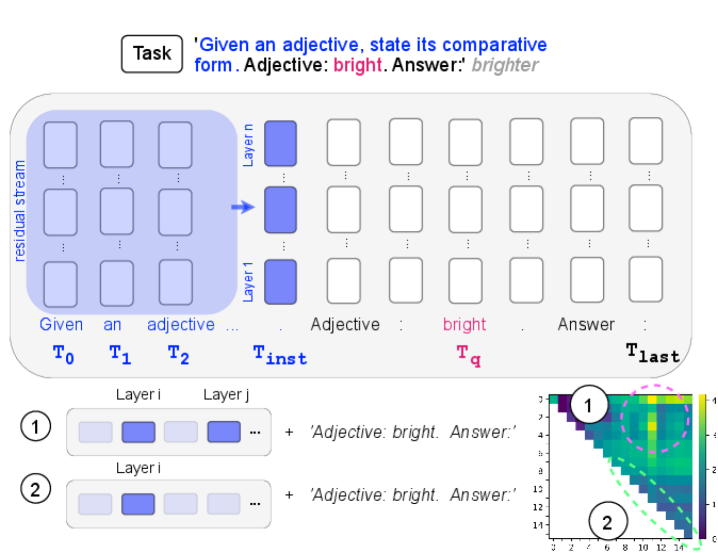
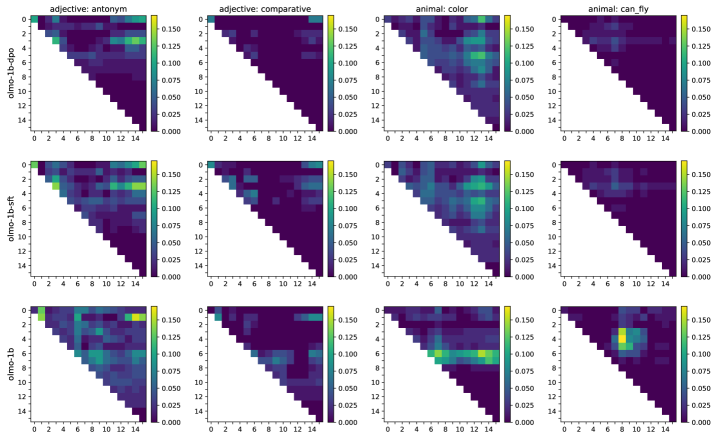
本文从机制可解释性的角度出发,研究了指令调优语言模型在后训练阶段(监督微调SFT和直接偏好优化DPO)中,指令特定表征是如何构建和利用的。通过因果中介分析,发现指令表征在模型中具有相当的局部性,称之为指令向量(IVs)。这些向量表现出线性可分性和非线性因果交互的奇特并置,对机制可解释性中常见的线性表征假设提出了广泛质疑。为了解开非线性因果交互,提出了一种新的方法来定位语言模型中的信息处理过程,该方法不受基于修补技术的隐式线性假设的限制。研究发现,在早期层中形成的task表征的条件下,后续层会选择不同的信息路径来解决该task,即IVs充当电路选择器。
🔬 方法详解
问题定义:现有指令调优的大语言模型取得了显著的成功,但我们对其内部如何处理指令的机制知之甚少。现有的机制可解释性方法,例如基于patching的技术,通常假设模型内部的表征是线性的,这可能无法捕捉到复杂的非线性交互。因此,需要研究指令表征是如何构建和利用的,以及是否存在非线性交互。
核心思路:论文的核心思路是通过因果中介分析来定位模型中与指令相关的表征(指令向量IVs),并使用一种新的、不依赖线性假设的方法来研究这些IVs之间的非线性因果交互。通过分析IVs在不同层中的作用,揭示它们如何影响模型的行为。
技术框架:该研究主要包含以下几个阶段:1) 使用因果中介分析来识别模型中的指令向量(IVs)。2) 分析IVs的线性可分性。3) 提出一种新的方法来定位模型中的信息处理过程,该方法不依赖于线性假设。4) 使用该方法来研究IVs之间的非线性因果交互,并揭示它们如何充当电路选择器,即根据任务选择不同的信息路径。
关键创新:论文的关键创新在于:1) 识别并定义了指令向量(IVs),并证明了它们在模型中的局部性。2) 提出了一种新的、不依赖线性假设的方法来定位模型中的信息处理过程,从而能够研究非线性因果交互。3) 揭示了指令向量在模型中充当电路选择器的作用,即根据任务选择不同的信息路径。
关键设计:论文使用了因果中介分析来识别指令向量,并设计了一种新的信息定位方法来研究非线性因果交互。具体的技术细节包括:1) 使用了监督微调(SFT)和直接偏好优化(DPO)等后训练方法。2) 设计了特定的实验来评估指令向量的线性可分性和非线性因果交互。3) 使用了特定的指标来衡量信息定位的准确性。
🖼️ 关键图片

📊 实验亮点
研究发现指令表征在模型中具有相当的局部性,并称之为指令向量(IVs)。这些向量表现出线性可分性和非线性因果交互的奇特并置。通过新提出的非线性信息定位方法,揭示了指令向量在模型中充当电路选择器的作用。
🎯 应用场景
该研究成果有助于我们更深入地理解大语言模型的工作机制,为改进指令调优方法、提高模型的可控性和安全性提供理论基础。此外,该研究提出的非线性信息定位方法可以应用于其他深度学习模型,以揭示其内部的复杂交互。
📄 摘要(原文)
Despite the recent success of instruction-tuned language models and their ubiquitous usage, very little is known of how models process instructions internally. In this work, we address this gap from a mechanistic point of view by investigating how instruction-specific representations are constructed and utilized in different stages of post-training: Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO). Via causal mediation, we identify that instruction representation is fairly localized in models. These representations, which we call Instruction Vectors (IVs), demonstrate a curious juxtaposition of linear separability along with non-linear causal interaction, broadly questioning the scope of the linear representation hypothesis commonplace in mechanistic interpretability. To disentangle the non-linear causal interaction, we propose a novel method to localize information processing in language models that is free from the implicit linear assumptions of patching-based techniques. We find that, conditioned on the task representations formed in the early layers, different information pathways are selected in the later layers to solve that task, i.e., IVs act as circuit selectors.