SparseEval: Efficient Evaluation of Large Language Models by Sparse Optimization
作者: Taolin Zhang, Hang Guo, Wang Lu, Tao Dai, Shu-Tao Xia, Jindong Wang
分类: cs.CL, cs.LG
发布日期: 2026-02-08
备注: ICLR2026
🔗 代码/项目: GITHUB
💡 一句话要点
SparseEval:通过稀疏优化实现大语言模型的高效评估
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型评估 稀疏优化 梯度下降 锚点选择 性能预测 模型选择 高效评估 基准测试
📋 核心要点
- 现有大语言模型评估方法计算成本高昂,难以高效评估模型性能。
- SparseEval通过稀疏优化,选择代表性样本作为锚点,降低评估所需的计算量。
- 实验表明,SparseEval在多种基准测试中表现出低估计误差和高排序相关性。
📝 摘要(中文)
随着大型语言模型(LLMs)规模的不断扩大,它们在各种下游任务上的性能也得到了显著提高。然而,评估它们的能力变得越来越昂贵,因为对大量基准样本执行推理会产生很高的计算成本。本文重新审视了模型-项目性能矩阵,并表明它具有稀疏性,可以选择代表性项目作为锚点,并且高效基准测试的任务可以被表述为一个稀疏优化问题。基于这些见解,我们提出SparseEval,这是一种首次采用梯度下降来优化锚点权重,并采用迭代细化策略进行锚点选择的方法。我们利用MLP的表示能力来处理稀疏优化,并提出锚点重要性评分和候选重要性评分来评估每个项目对于任务感知细化的价值。大量的实验证明了我们的方法在各种基准测试中具有较低的估计误差和较高的Kendall's~$τ$,展示了其在实际场景中的卓越鲁棒性和实用性。
🔬 方法详解
问题定义:现有的大语言模型评估方法,需要对大量的基准测试样本进行推理,计算成本非常高昂。尤其是在模型规模持续增长的情况下,评估一次模型的性能需要消耗大量的计算资源和时间,这限制了模型迭代的速度和研究的效率。因此,如何高效地评估大语言模型的性能是一个亟待解决的问题。
核心思路:论文的核心思路是利用模型-项目性能矩阵的稀疏性。作者观察到,并非所有的测试样本都对评估模型的性能至关重要,其中一部分样本具有代表性,可以作为“锚点”。通过选择这些锚点样本,并优化它们在评估过程中的权重,可以显著减少所需的计算量,同时保持评估结果的准确性。这种方法类似于在海量数据中寻找最具代表性的子集。
技术框架:SparseEval的整体框架包含以下几个主要阶段:1) 初始化锚点集合:从所有测试样本中选择一部分样本作为初始的锚点集合。2) 锚点权重优化:使用梯度下降算法,优化每个锚点样本的权重,使得基于锚点样本的性能估计尽可能接近真实性能。3) 锚点迭代细化:根据锚点重要性评分和候选重要性评分,迭代地更新锚点集合,选择更有价值的样本加入锚点集合,并移除价值较低的样本。4) 性能评估:使用优化后的锚点集合和权重,对模型进行性能评估。
关键创新:SparseEval的关键创新在于:1) 稀疏优化视角:首次将大语言模型的评估问题转化为一个稀疏优化问题,利用模型-项目性能矩阵的稀疏性来降低计算成本。2) 梯度下降优化锚点权重:采用梯度下降算法来优化锚点样本的权重,使得评估结果更加准确。3) 迭代细化策略:提出锚点重要性评分和候选重要性评分,用于迭代地更新锚点集合,提高评估的效率和准确性。
关键设计:SparseEval的关键设计包括:1) 锚点重要性评分(Anchor Importance Score):用于评估当前锚点集合中每个样本的重要性,指导移除价值较低的锚点。2) 候选重要性评分(Candidate Importance Score):用于评估候选样本的重要性,指导选择更有价值的样本加入锚点集合。3) MLP表示能力:使用多层感知机(MLP)来学习锚点权重,利用MLP的非线性表示能力来更好地拟合模型-项目性能矩阵。4) 损失函数:采用均方误差(MSE)作为损失函数,衡量基于锚点样本的性能估计与真实性能之间的差距。
🖼️ 关键图片
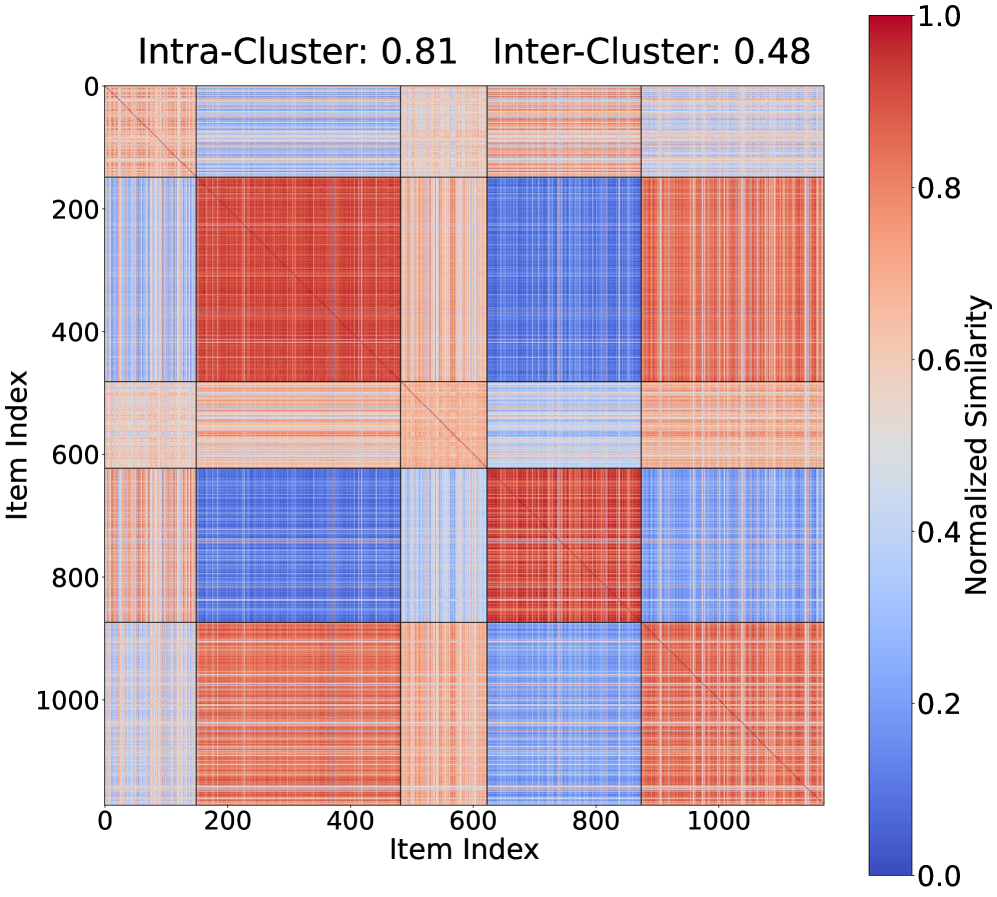
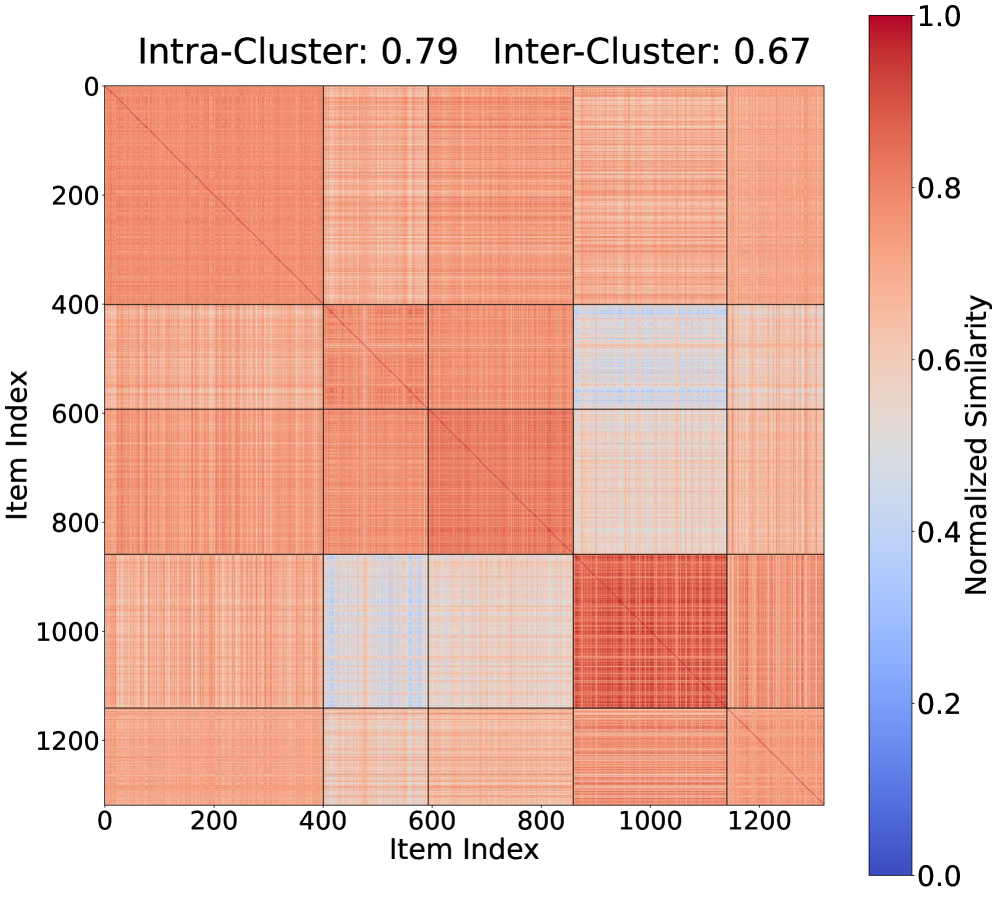
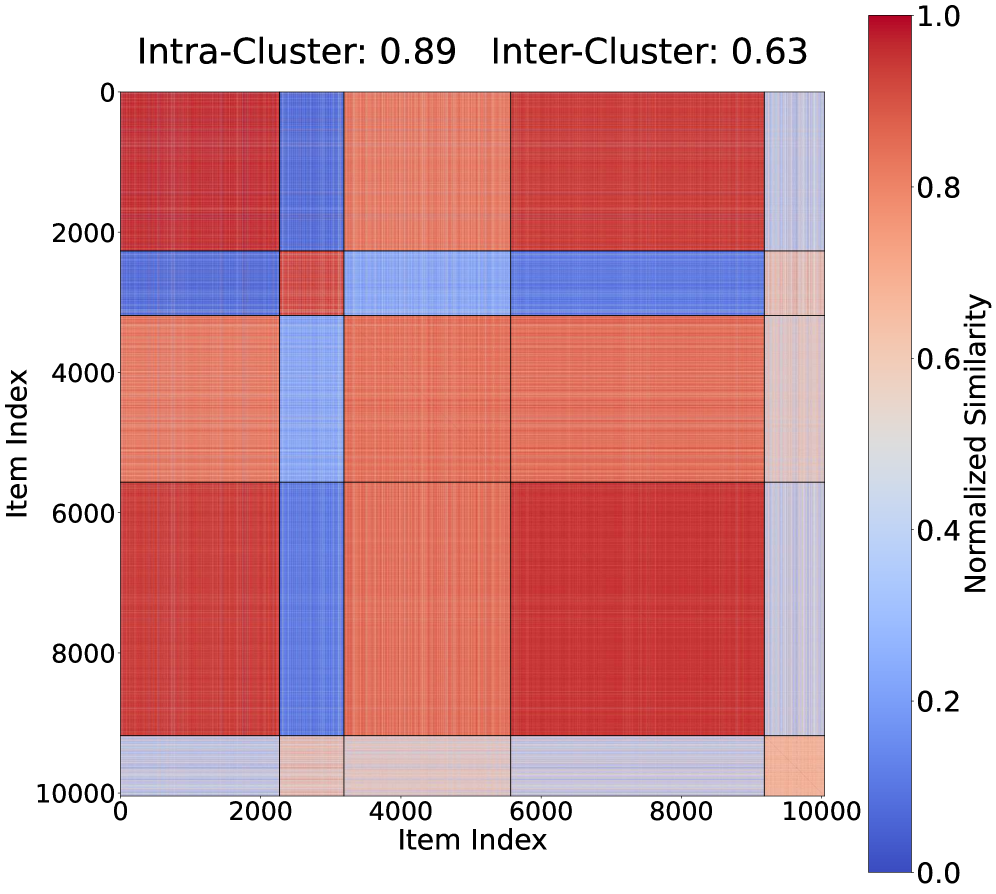
📊 实验亮点
实验结果表明,SparseEval在多个基准测试中实现了较低的估计误差和较高的Kendall's τ相关系数,显著优于现有的评估方法。例如,在某些任务上,SparseEval可以在仅使用少量样本的情况下,达到与使用全部样本相似的评估精度,从而大大降低了计算成本。实验还证明了SparseEval在不同任务和模型上的鲁棒性和泛化能力。
🎯 应用场景
SparseEval可应用于大语言模型的快速评估和选择,尤其是在资源受限的场景下。它可以帮助研究人员和开发者在模型开发过程中快速评估模型的性能,选择合适的模型进行部署。此外,SparseEval还可以用于自动化模型评估平台,降低模型评估的成本,提高评估效率,加速大语言模型的研究和应用。
📄 摘要(原文)
As large language models (LLMs) continue to scale up, their performance on various downstream tasks has significantly improved. However, evaluating their capabilities has become increasingly expensive, as performing inference on a large number of benchmark samples incurs high computational costs. In this paper, we revisit the model-item performance matrix and show that it exhibits sparsity, that representative items can be selected as anchors, and that the task of efficient benchmarking can be formulated as a sparse optimization problem. Based on these insights, we propose SparseEval, a method that, for the first time, adopts gradient descent to optimize anchor weights and employs an iterative refinement strategy for anchor selection. We utilize the representation capacity of MLP to handle sparse optimization and propose the Anchor Importance Score and Candidate Importance Score to evaluate the value of each item for task-aware refinement. Extensive experiments demonstrate the low estimation error and high Kendall's~$τ$ of our method across a variety of benchmarks, showcasing its superior robustness and practicality in real-world scenarios. Code is available at {https://github.com/taolinzhang/SparseEval}.