Pruning as a Cooperative Game: Surrogate-Assisted Layer Contribution Estimation for Large Language Models
作者: Xuan Ding, Pengyu Tong, Ranjie Duan, Yunjian Zhang, Rui Sun, Yao Zhu
分类: cs.CL, cs.AI
发布日期: 2026-02-08
备注: Accepted by ICLR 2026
💡 一句话要点
提出基于合作博弈的LLM剪枝方法,利用代理模型估计层贡献度
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 模型剪枝 合作博弈 Shapley值 代理模型
📋 核心要点
- 现有LLM剪枝方法依赖静态规则,忽略层间依赖,导致剪枝效果受限。
- 论文提出博弈论框架,将层剪枝视为合作博弈,模型性能为效用。
- 使用轻量级代理网络估计层贡献,结合分层蒙特卡罗抽样降低计算成本,实验验证了有效性。
📝 摘要(中文)
大型语言模型(LLM)在各种任务中表现出令人印象深刻的性能,但其高计算需求限制了在实际场景中的部署。层剪枝是缓解推理成本的常用策略,但现有方法通常依赖于静态启发式规则,未能考虑层之间的相互依赖性,从而限制了剪枝过程的有效性。本文提出了一个博弈论框架,将层剪枝形式化为一个合作博弈,其中每一层充当一个参与者,模型性能作为效用。由于计算精确的Shapley值对于大型语言模型(LLM)来说在计算上是不可行的,因此我们提出使用一个轻量级的代理网络来估计层级的边际贡献。该网络能够以较低的计算成本预测任意层组合的LLM性能。此外,我们采用分层蒙特卡罗掩码抽样来进一步降低Sharpley值估计的成本。这种方法捕捉了层间的依赖关系,并动态地识别用于剪枝的关键层。大量实验表明,我们的方法在困惑度和零样本精度方面具有持续的优越性,从而为大型语言模型实现了更有效和高效的层剪枝。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)层剪枝中,现有方法依赖静态启发式规则,忽略层间依赖关系,导致剪枝效果不佳的问题。现有方法无法动态识别关键层,剪枝效率和效果受到限制。
核心思路:论文将层剪枝问题建模为合作博弈,每一层作为一个参与者,模型性能作为该层的效用。通过计算每一层对模型性能的贡献(Shapley值),来确定哪些层应该被剪枝。核心在于利用层间的相互依赖关系,动态地识别对模型性能影响较小的层。
技术框架:整体框架包含三个主要阶段:1) 代理模型训练:训练一个轻量级的代理网络,用于快速预测LLM在不同层组合下的性能。2) Shapley值估计:使用代理模型和分层蒙特卡罗掩码抽样,估计每一层的Shapley值,代表该层对模型性能的边际贡献。3) 层剪枝:根据Shapley值的大小,对LLM进行层剪枝,优先剪枝贡献度低的层。
关键创新:关键创新在于将层剪枝问题建模为合作博弈,并使用代理模型加速Shapley值的计算。与传统方法相比,该方法能够考虑层间的依赖关系,动态地识别关键层,从而实现更有效的剪枝。代理模型的使用显著降低了计算复杂度,使得该方法能够应用于大型语言模型。
关键设计:代理模型是一个轻量级的神经网络,输入是LLM的层组合(例如,哪些层被保留,哪些层被剪枝),输出是LLM在该层组合下的性能指标(例如,困惑度)。分层蒙特卡罗掩码抽样用于减少Shapley值估计的方差,提高估计的准确性。具体而言,将层划分为不同的组,并在每个组内进行抽样,以确保抽样的多样性。
🖼️ 关键图片


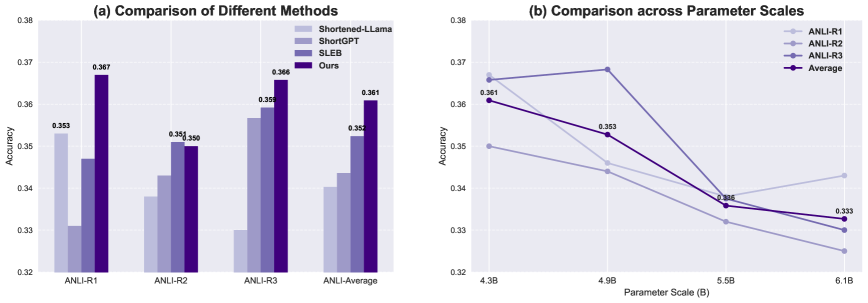
📊 实验亮点
实验结果表明,该方法在困惑度和零样本精度方面均优于现有剪枝方法。例如,在某个LLM上,该方法可以在保持精度基本不变的情况下,剪掉一定比例的层,从而显著降低计算成本。与基于启发式规则的剪枝方法相比,该方法能够更有效地识别和剪枝冗余层。
🎯 应用场景
该研究成果可应用于各种需要部署大型语言模型的场景,例如移动设备、边缘计算设备等资源受限的环境。通过层剪枝,可以显著降低LLM的计算复杂度和内存占用,从而使其能够在这些设备上高效运行。此外,该方法还可以用于模型压缩和加速推理,提高LLM的实用性。
📄 摘要(原文)
While large language models (LLMs) demonstrate impressive performance across various tasks, their deployment in real-world scenarios is still constrained by high computational demands. Layer-wise pruning, a commonly employed strategy to mitigate inference costs, can partially address this challenge. However, existing approaches generally depend on static heuristic rules and fail to account for the interdependencies among layers, thereby limiting the effectiveness of the pruning process. To this end, this paper proposes a game-theoretic framework that formulates layer pruning as a cooperative game in which each layer acts as a player and model performance serves as the utility. As computing exact Shapley values is computationally infeasible for large language models (LLMs), we propose using a lightweight surrogate network to estimate layer-wise marginal contributions. This network can predict LLM performance for arbitrary layer combinations at a low computational cost. Additionally, we employ stratified Monte Carlo mask sampling to further reduce the cost of Sharpley value estimation. This approach captures inter-layer dependencies and dynamically identifies critical layers for pruning. Extensive experiments demonstrate the consistent superiority of our method in terms of perplexity and zero-shot accuracy, achieving more efficient and effective layer-wise pruning for large language models.