Emergent Structured Representations Support Flexible In-Context Inference in Large Language Models
作者: Ningyu Xu, Qi Zhang, Xipeng Qiu, Xuanjing Huang
分类: cs.CL, cs.AI
发布日期: 2026-02-08 (更新: 2026-02-10)
备注: 27 pages, 16 figures
💡 一句话要点
揭示大语言模型中涌现的结构化表征如何支持灵活的上下文推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 上下文推理 结构化表征 因果中介分析 注意力机制
📋 核心要点
- 现有工作未能充分理解LLM推理能力与内部结构化表征之间的功能性联系。
- 论文通过因果中介分析,揭示LLM内部概念子空间在推理中的关键因果作用。
- 研究发现LLM通过分层处理,利用注意力机制构建和利用上下文相关的结构化表征。
📝 摘要(中文)
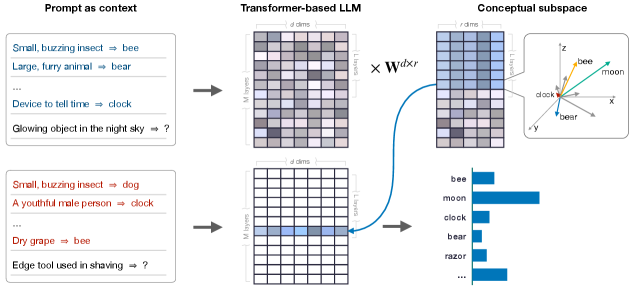
大型语言模型(LLMs)展现出类似人类推理的涌现行为。虽然最近的研究已经识别出这些模型中存在结构化的、类似人类的概念表征,但它们是否在功能上依赖于这些表征进行推理仍然不清楚。本文研究了LLMs在上下文概念推理过程中的内部处理机制。结果表明,在中后期层中出现了一个概念子空间,其表征结构在不同上下文中保持不变。通过因果中介分析,我们证明了这个子空间不仅仅是一种伴随现象,而是在功能上对模型预测至关重要,从而确立了其在推理中的因果作用。我们进一步识别出一个分层递进的过程,其中早期到中期层的注意力头整合上下文线索来构建和完善子空间,随后由后期层利用该子空间来生成预测。总之,这些发现提供了证据,表明LLMs在上下文中动态地构建和使用结构化的潜在表征进行推理,从而深入了解了灵活适应背后的计算过程。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在上下文推理中,其涌现的结构化表征是否真正被功能性地利用的问题。现有研究虽然发现了LLMs内部存在类似人类的结构化概念表征,但缺乏证据表明这些表征在推理过程中起着关键作用,还是仅仅是伴随现象。因此,需要深入探究LLMs的内部处理机制,理解其如何利用这些表征进行灵活的上下文推理。
核心思路:论文的核心思路是通过因果中介分析,量化LLMs内部概念子空间对最终预测结果的影响。如果该子空间在模型预测中起着重要的因果作用,则可以证明LLMs确实依赖于结构化表征进行推理。此外,论文还研究了LLMs内部不同层之间的信息传递,特别是注意力机制在构建和利用这些表征中的作用。
技术框架:论文的技术框架主要包括以下几个步骤:1) 在LLM中识别出概念子空间;2) 使用因果中介分析,评估该子空间对模型预测的因果效应;3) 分析不同层之间的信息传递,特别是注意力头的行为,以理解上下文信息如何被整合到概念子空间的构建中;4) 验证表征结构在不同上下文中的持久性。
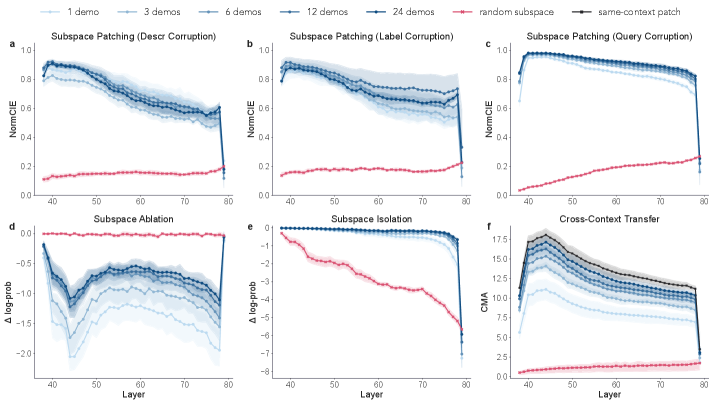
关键创新:论文最重要的技术创新在于使用因果中介分析来证明LLMs内部结构化表征的因果作用。与以往仅仅观察到表征的存在不同,该方法能够量化表征对最终预测的影响,从而更直接地揭示其在推理过程中的重要性。此外,对LLM分层处理机制的分析,也为理解LLM如何利用上下文信息构建和利用结构化表征提供了新的视角。
关键设计:论文的关键设计包括:1) 选择合适的概念推理任务,例如概念分类或关系推理;2) 使用合适的因果中介分析方法,例如Sobel检验或Bootstrap方法,来评估概念子空间的因果效应;3) 设计实验来分析不同层之间的信息传递,例如通过注意力可视化或注意力权重分析;4) 使用合适的指标来评估表征结构的持久性,例如表征相似度或对齐度。
🖼️ 关键图片

📊 实验亮点
研究发现,LLM中存在一个概念子空间,其表征结构在不同上下文中保持不变。因果中介分析表明,该子空间对模型预测具有显著的因果效应,证明了LLM在推理过程中依赖于结构化表征。此外,研究还揭示了LLM内部的分层处理机制,其中早期到中期层负责构建和完善概念子空间,而后期层则利用该子空间进行预测。
🎯 应用场景
该研究成果有助于提升大语言模型的可解释性和可控性,并为开发更高效、更可靠的AI系统提供理论基础。潜在应用领域包括:智能问答、机器翻译、知识图谱构建、以及需要复杂推理能力的各种AI应用。未来,该研究可以扩展到其他类型的模型和任务,并为开发更通用的人工智能系统提供指导。
📄 摘要(原文)
Large language models (LLMs) exhibit emergent behaviors suggestive of human-like reasoning. While recent work has identified structured, human-like conceptual representations within these models, it remains unclear whether they functionally rely on such representations for reasoning. Here we investigate the internal processing of LLMs during in-context concept inference. Our results reveal a conceptual subspace emerging in middle to late layers, whose representational structure persists across contexts. Using causal mediation analyses, we demonstrate that this subspace is not merely an epiphenomenon but is functionally central to model predictions, establishing its causal role in inference. We further identify a layer-wise progression where attention heads in early-to-middle layers integrate contextual cues to construct and refine the subspace, which is subsequently leveraged by later layers to generate predictions. Together, these findings provide evidence that LLMs dynamically construct and use structured, latent representations in context for inference, offering insights into the computational processes underlying flexible adaptation.