Attn-GS: Attention-Guided Context Compression for Efficient Personalized LLMs
作者: Shenglai Zeng, Tianqi Zheng, Chuan Tian, Dante Everaert, Yau-Shian Wang, Yupin Huang, Michael J. Morais, Rohit Patki, Jinjin Tian, Xinnan Dai, Kai Guo, Monica Xiao Cheng, Hui Liu
分类: cs.CL
发布日期: 2026-02-08
💡 一句话要点
提出Attn-GS,利用注意力机制引导上下文压缩,提升个性化LLM效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 个性化LLM 上下文压缩 注意力机制 大型语言模型 用户画像
📋 核心要点
- 现有个性化LLM方法难以有效压缩用户画像,导致推理延迟高和成本增加。
- Attn-GS利用LLM的注意力模式识别重要个性化信号,指导上下文压缩。
- 实验表明,Attn-GS在显著减少token使用量的情况下,性能接近使用完整上下文。
📝 摘要(中文)
为了将大量交互历史和用户画像融入个性化大型语言模型(LLM),需要考虑输入token的限制,这会带来高推理延迟和API成本。现有方法依赖于启发式方法,例如选择最近的交互或提示摘要模型来压缩用户画像。然而,这些方法将上下文视为一个整体,没有考虑LLM如何内部处理和区分不同画像组成部分的重要性。我们研究了LLM的注意力模式是否能有效识别重要的个性化信号,从而实现智能上下文压缩。通过对代表性个性化任务的初步研究,我们发现(a) LLM的注意力模式自然地揭示了重要信号,(b) 微调增强了LLM区分相关和不相关信息的能力。基于这些发现,我们提出了Attn-GS,一个注意力引导的上下文压缩框架,它利用来自标记模型的注意力反馈来标记重要的个性化句子,然后引导压缩模型生成任务相关的、高质量的压缩用户上下文。大量实验表明,Attn-GS在不同的任务、token限制和设置下,显著优于各种基线,在减少50倍token使用量的情况下,性能接近使用完整上下文。
🔬 方法详解
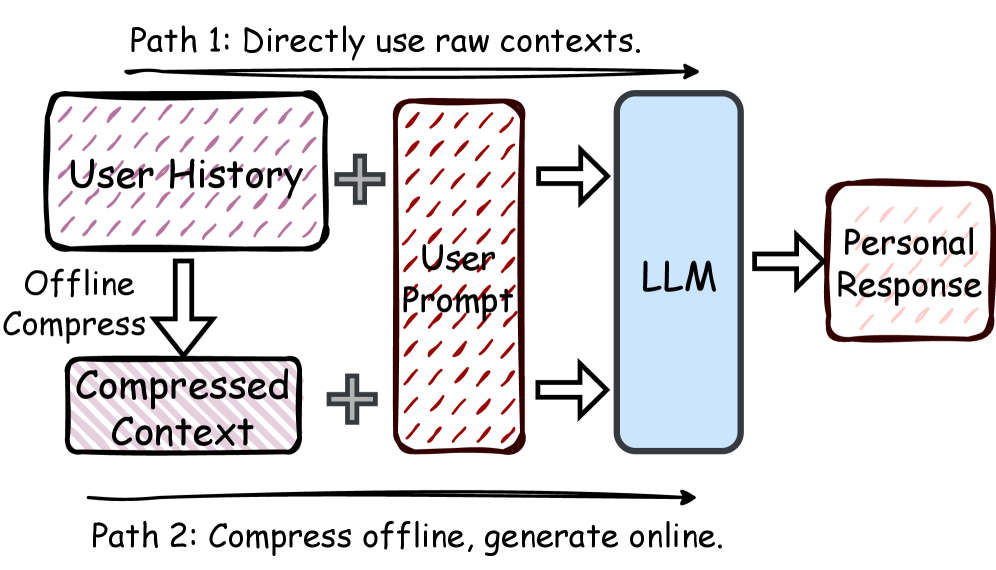
问题定义:个性化LLM需要整合用户的历史交互和个人资料,但受限于输入token数量的限制,直接使用完整上下文会导致推理延迟增加和API成本上升。现有的上下文压缩方法,例如选择最近交互记录或使用摘要模型,通常采用启发式规则,忽略了LLM内部对不同上下文信息的处理和优先级区分,导致压缩后的上下文可能丢失关键的个性化信息。
核心思路:Attn-GS的核心思路是利用LLM自身的注意力机制来识别上下文中最重要的个性化信号。通过分析LLM在处理用户上下文时的注意力分布,可以确定哪些句子或token对特定任务最为重要。然后,利用这些注意力信息来指导上下文压缩过程,确保压缩后的上下文能够保留关键的个性化信息,从而在减少token数量的同时,保持甚至提升LLM的性能。
技术框架:Attn-GS框架包含两个主要模块:标记模型(Marking Model)和压缩模型(Compression Model)。首先,标记模型通过微调LLM,使其能够根据任务需求,对用户上下文中的每个句子进行重要性评分,这个评分基于LLM的注意力分布。然后,压缩模型利用标记模型提供的句子重要性评分,生成压缩后的用户上下文。压缩模型可以使用各种文本摘要或压缩技术,例如抽取式摘要或生成式摘要。整个流程通过注意力反馈机制连接,确保压缩过程能够保留关键的个性化信息。
关键创新:Attn-GS的关键创新在于利用LLM自身的注意力机制来指导上下文压缩。与传统的启发式方法或通用的摘要模型不同,Attn-GS能够根据LLM对不同上下文信息的实际利用情况,有针对性地进行压缩,从而更好地保留关键的个性化信息。此外,通过微调LLM作为标记模型,可以进一步提升其区分相关和不相关信息的能力。
关键设计:标记模型通常采用预训练的LLM进行微调,微调的目标是使LLM能够预测每个句子对特定任务的重要性。可以使用交叉熵损失函数,将句子重要性评分作为标签。压缩模型可以使用Transformer架构的序列到序列模型,输入是原始用户上下文和标记模型提供的句子重要性评分,输出是压缩后的用户上下文。在训练过程中,可以使用强化学习方法,例如策略梯度,来优化压缩模型的性能,使其能够生成任务相关的、高质量的压缩上下文。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Attn-GS在多个个性化任务上显著优于现有基线方法。例如,在某些任务上,Attn-GS在token使用量减少50倍的情况下,性能接近使用完整上下文。与使用启发式方法压缩上下文相比,Attn-GS能够显著提升LLM的性能,证明了利用注意力机制进行上下文压缩的有效性。
🎯 应用场景
Attn-GS可应用于各种需要个性化LLM的场景,例如个性化推荐系统、定制化对话机器人、以及需要根据用户历史行为进行预测的金融风控系统。通过降低token使用量,Attn-GS可以显著降低API成本和推理延迟,使得在资源受限的环境中部署个性化LLM成为可能。未来,该方法可以扩展到处理更复杂的上下文信息,例如多模态数据或知识图谱。
📄 摘要(原文)
Personalizing large language models (LLMs) to individual users requires incorporating extensive interaction histories and profiles, but input token constraints make this impractical due to high inference latency and API costs. Existing approaches rely on heuristic methods such as selecting recent interactions or prompting summarization models to compress user profiles. However, these methods treat context as a monolithic whole and fail to consider how LLMs internally process and prioritize different profile components. We investigate whether LLMs' attention patterns can effectively identify important personalization signals for intelligent context compression. Through preliminary studies on representative personalization tasks, we discover that (a) LLMs' attention patterns naturally reveal important signals, and (b) fine-tuning enhances LLMs' ability to distinguish between relevant and irrelevant information. Based on these insights, we propose Attn-GS, an attention-guided context compression framework that leverages attention feedback from a marking model to mark important personalization sentences, then guides a compression model to generate task-relevant, high-quality compressed user contexts. Extensive experiments demonstrate that Attn-GS significantly outperforms various baselines across different tasks, token limits, and settings, achieving performance close to using full context while reducing token usage by 50 times.