Blind to the Human Touch: Overlap Bias in LLM-Based Summary Evaluation
作者: Jiangnan Fang, Cheng-Tse Liu, Hanieh Deilamsalehy, Nesreen K. Ahmed, Puneet Mathur, Nedim Lipka, Franck Dernoncourt, Ryan A. Rossi
分类: cs.CL
发布日期: 2026-02-07
💡 一句话要点
揭示LLM摘要评估中的重叠偏差:LLM倾向于与自身相似的生成摘要
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM评估 摘要评估 重叠偏差 自然语言生成 ROUGE BLEU 偏差分析 人工智能
📋 核心要点
- 现有LLM评估器在摘要任务中存在偏差,尤其是在与人类撰写摘要的重叠度较低时,倾向于选择机器生成的摘要。
- 该研究通过分析LLM评估器与人类摘要的重叠度,揭示了LLM在摘要评估中存在的偏差模式,并测试了多个主流LLM。
- 实验结果表明,LLM评估器在低重叠度情况下更偏好机器生成的摘要,提示需要更复杂的评估方法。
📝 摘要(中文)
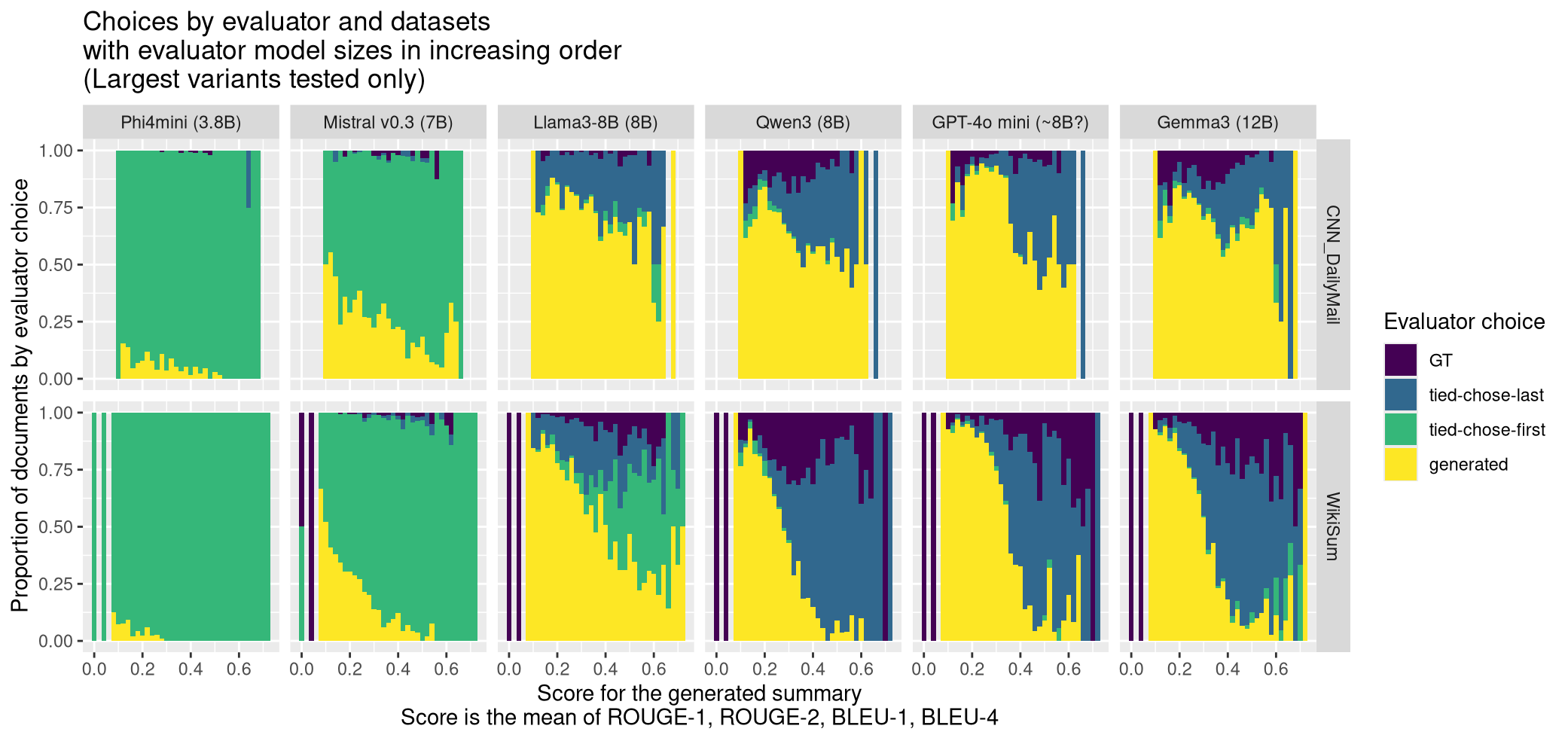
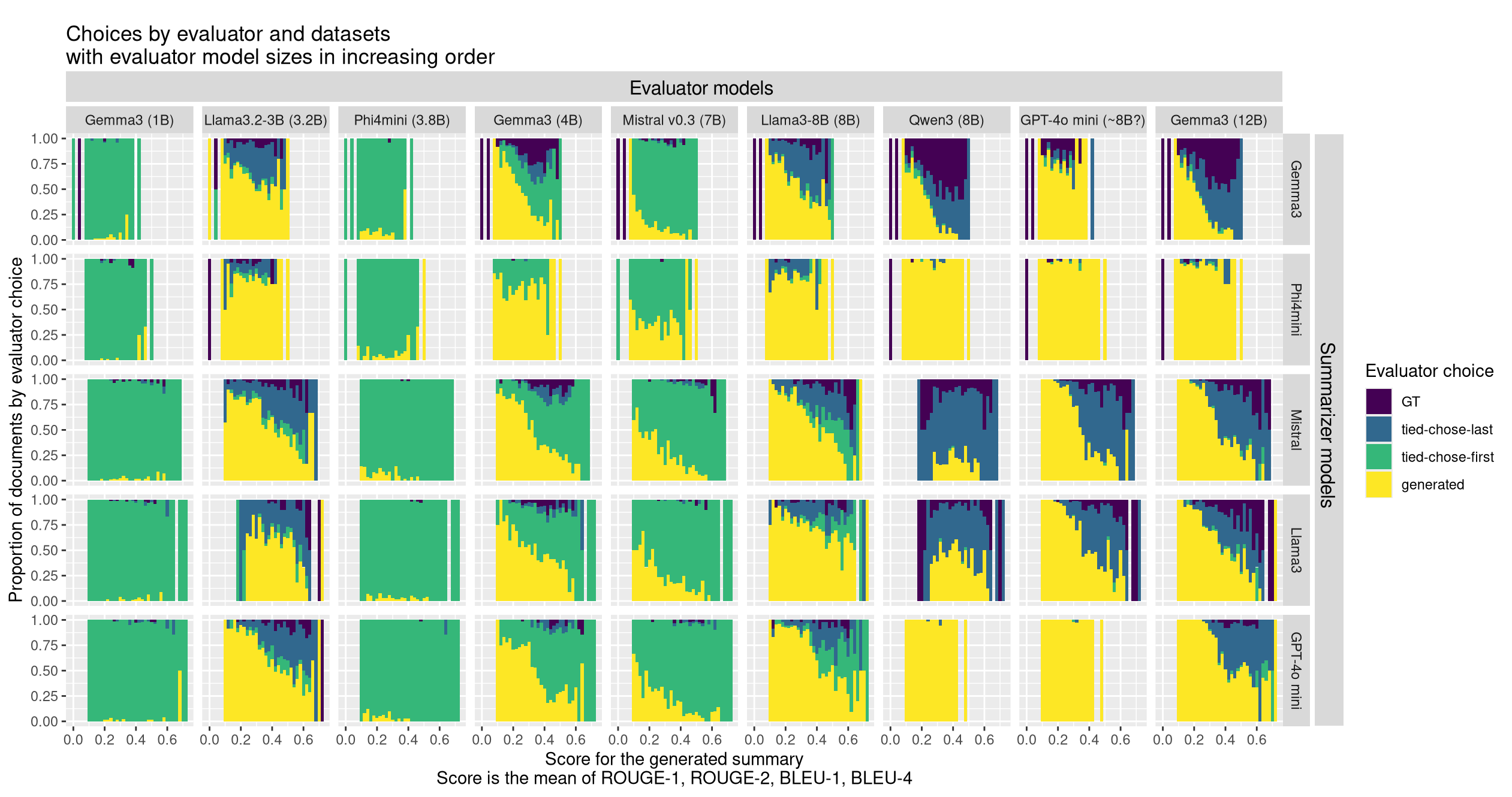
大型语言模型(LLM)评估器因其能更好地捕捉语义信息、进行推理和抵抗释义,常被用于摘要等任务,与传统的基于算法的指标并用。然而,LLM评估器表现出长度和顺序等偏差,并且容易受到各种对抗性输入提示的影响。虽然最近的研究已经调查了这些偏差,但很少有研究在与明确定义的重叠指标相关的更细粒度层面上分析它们。在这项工作中,我们提供了一个LLM评估器偏差分析,作为与人类撰写的回应重叠程度的函数,领域为摘要。我们测试了9个最新的LLM,参数数量从10亿到120亿不等,包括Gemma 3和LLaMA 3的变体。我们发现,随着被评估摘要之间的相似性(通过ROUGE和BLEU衡量)降低,LLM评估器越来越倾向于其他LLM生成的摘要而不是人类撰写的摘要,并且这种模式延伸到所有测试模型(除一个之外),并且无论模型自身的position偏差如何都存在。此外,我们发现模型难以评估即使是重叠有限的摘要,这表明摘要领域的LLM评估器应该依赖于简单比较之外的技术。
🔬 方法详解
问题定义:论文旨在研究在使用大型语言模型(LLM)作为评估器来评估摘要质量时,LLM评估器本身存在的偏差问题。现有方法,即直接使用LLM评估摘要,存在对长度、顺序等方面的偏好,并且容易受到对抗性攻击。更重要的是,现有研究缺乏对LLM评估器偏差与人类撰写摘要之间重叠度关系的细致分析,这使得我们难以理解LLM评估器在何种情况下会做出不合理的判断。
核心思路:论文的核心思路是分析LLM评估器对摘要的偏好程度与该摘要和人类撰写摘要之间的相似度(重叠度)之间的关系。通过控制摘要与人类摘要的重叠度,观察LLM评估器对不同摘要的评分,从而揭示LLM评估器在不同重叠度下的偏差行为。这种方法能够更细粒度地理解LLM评估器的评估机制,并发现其潜在的缺陷。
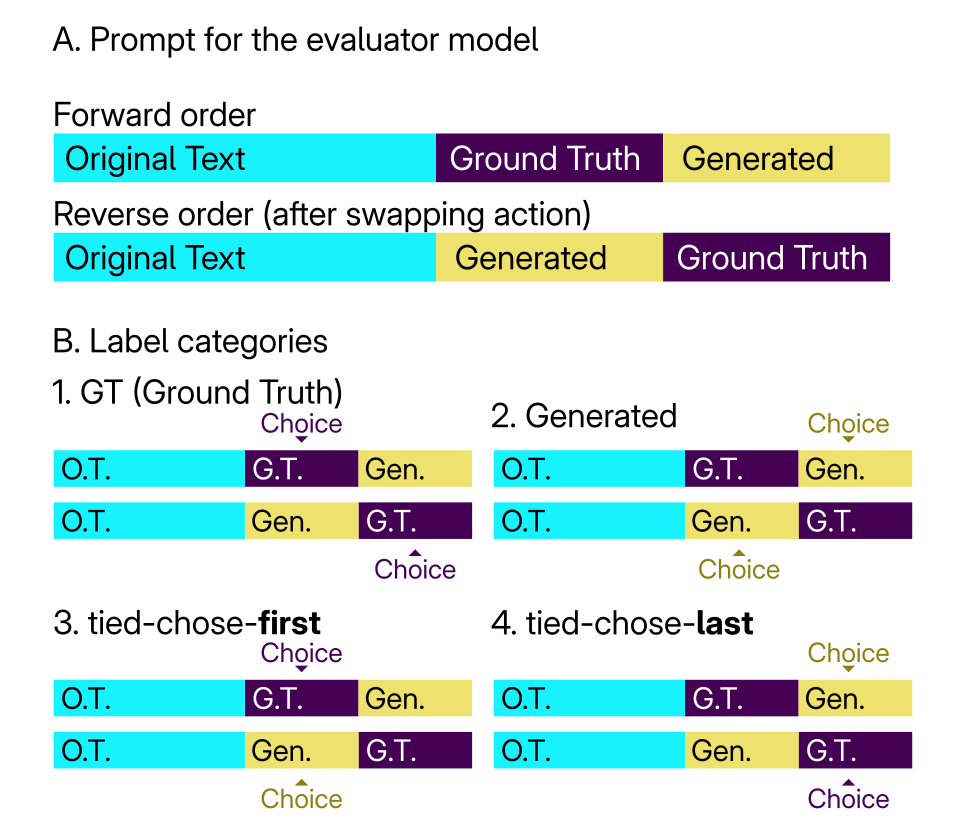
技术框架:该研究的技术框架主要包括以下几个步骤: 1. 数据集准备:选择摘要数据集,并准备人类撰写的摘要作为参考。 2. 摘要生成:使用不同的LLM生成摘要,并计算这些摘要与人类撰写摘要之间的ROUGE和BLEU分数,作为重叠度的衡量标准。 3. LLM评估:使用多个LLM评估器对生成的摘要进行评分。 4. 偏差分析:分析LLM评估器的评分与摘要重叠度之间的关系,揭示LLM评估器的偏差模式。
关键创新:该研究的关键创新在于: 1. 首次系统性地分析了LLM评估器在摘要评估任务中,其偏差与被评估摘要和人类撰写摘要之间重叠度的关系。 2. 揭示了LLM评估器在低重叠度情况下,更倾向于机器生成的摘要而非人类撰写摘要的现象。 3. 通过实验验证了这种偏差在多个主流LLM中普遍存在,并且与模型自身的position偏差无关。
关键设计:该研究的关键设计包括: 1. 使用ROUGE和BLEU分数作为衡量摘要之间重叠度的指标。 2. 选择多个不同参数规模的LLM作为评估器,以验证结果的普适性。 3. 控制实验变量,例如摘要的长度和顺序,以排除其他因素对结果的影响。 4. 采用统计分析方法,例如回归分析,来量化LLM评估器的偏差程度。
🖼️ 关键图片
📊 实验亮点
实验结果表明,随着被评估摘要与人类撰写摘要的相似度降低,LLM评估器越来越倾向于其他LLM生成的摘要。这种现象在测试的9个LLM中普遍存在(除一个之外),并且与模型自身的position偏差无关。即使在摘要重叠度有限的情况下,LLM也难以做出准确判断,表明简单的比较方法不足以胜任摘要评估任务。
🎯 应用场景
该研究成果可应用于改进LLM摘要评估方法,例如设计更鲁棒的评估指标或训练更公正的LLM评估器。此外,该研究也为其他自然语言生成任务的评估提供了借鉴,有助于构建更可靠的AI系统。未来的研究可以探索如何利用这些发现来开发自动偏差校正技术,从而提高LLM评估的准确性和公平性。
📄 摘要(原文)
Large language model (LLM) judges have often been used alongside traditional, algorithm-based metrics for tasks like summarization because they better capture semantic information, are better at reasoning, and are more robust to paraphrasing. However, LLM judges show biases for length and order among others, and are vulnerable to various adversarial input prompts. While recent studies have looked into these biases, few have analyzed them at a more granular level in relation to a well-defined overlap metric. In this work we provide an LLM judge bias analysis as a function of overlap with human-written responses in the domain of summarization. We test 9 recent LLMs with parameter counts ranging from 1 billion to 12 billion, including variants of Gemma 3 and LLaMA 3. We find that LLM judges increasingly prefer summaries generated by other LLMs over those written by humans as the similarities (as measured by ROUGE and BLEU) between the judged summaries decrease, and this pattern extends to all but one model tested, and exists regardless of the models' own position biases. Additionally, we find that models struggle to judge even summaries with limited overlaps, suggesting that LLM-as-a-judge in the summary domain should rely on techniques beyond a simple comparison.