Improving Variable-Length Generation in Diffusion Language Models via Length Regularization
作者: Zicong Cheng, Ruixuan Jia, Jia Li, Guo-Wei Yang, Meng-Hao Guo, Shi-Min Hu
分类: cs.CL, cs.LG
发布日期: 2026-02-07
备注: diffusion language models
💡 一句话要点
提出LR-DLLM,通过长度正则化改进扩散语言模型中的变长生成问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散语言模型 变长生成 长度正则化 代码补全 文本填充
📋 核心要点
- 扩散语言模型在变长生成任务中面临挑战,因为它们依赖固定长度的画布,对未知长度的文本生成存在偏差。
- LR-DLLM通过显式地将生成长度视为变量,并引入长度正则化来校正置信度偏差,从而解耦语义和长度。
- 实验结果表明,LR-DLLM在代码补全和多语言评估任务中显著优于现有方法,提高了生成质量。
📝 摘要(中文)
扩散大型语言模型(DLLM)本质上不适合变长生成,因为它们的推理是在固定长度的画布上定义的,并隐式地假定已知目标长度。当长度未知时,例如在实际的补全和填充任务中,简单地比较不同掩码长度的置信度会产生系统性的偏差,导致生成不足或冗余延续。本文表明,这种失败源于生成置信度估计中固有的长度诱导偏差,使得现有的DLLM无法可靠地确定生成长度,从而导致变长推理不可靠。为了解决这个问题,我们提出了LR-DLLM,一个用于DLLM的长度正则化推理框架,它将生成长度视为一个显式变量,并在推理时实现可靠的长度确定。它通过显式的长度正则化来纠正有偏差的置信度估计,从而将语义兼容性与长度诱导的不确定性解耦。在此基础上,LR-DLLM能够在不修改底层DLLM或其训练过程的情况下,动态地扩展或收缩生成跨度。实验表明,在完全未知长度的情况下,LR-DLLM在HumanEvalInfilling上实现了51.3%的Pass@1(比DreamOn高+13.4%),在四种语言的McEval上实现了51.5%的平均Pass@1(比DreamOn高+14.3%)。
🔬 方法详解
问题定义:论文旨在解决扩散语言模型(DLLM)在变长文本生成任务中的固有缺陷。现有DLLM的推理过程基于固定长度的画布,这导致在处理未知长度的文本生成(如代码补全、文本填充)时,模型对不同长度的文本置信度估计存在系统性偏差,从而导致生成结果不准确,容易出现生成不足或冗余延续的问题。现有方法缺乏一种可靠的方式来确定生成文本的长度。
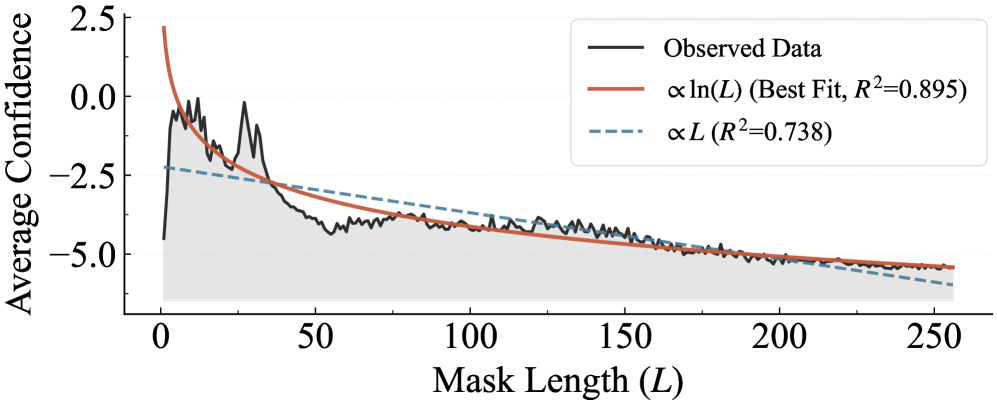
核心思路:论文的核心思路是将生成文本的长度视为一个显式变量,并通过引入长度正则化项来校正模型对不同长度文本的置信度估计偏差。通过解耦语义兼容性和长度诱导的不确定性,使得模型能够更准确地评估不同长度文本的合理性,从而实现更可靠的变长文本生成。
技术框架:LR-DLLM框架主要包含以下几个关键部分:首先,将生成长度显式地建模为一个变量。其次,引入长度正则化项,用于校正模型对不同长度文本的置信度估计偏差。最后,基于校正后的置信度估计,模型可以动态地扩展或收缩生成跨度,从而生成变长文本。整个框架不需要修改底层DLLM的结构或训练过程,可以灵活地应用于各种DLLM。
关键创新:论文最重要的技术创新在于提出了长度正则化(Length Regularization)的概念,并将其应用于DLLM的推理过程中。通过显式地建模生成长度并校正置信度偏差,LR-DLLM能够更准确地评估不同长度文本的合理性,从而克服了现有DLLM在变长文本生成任务中的固有缺陷。与现有方法相比,LR-DLLM不需要修改底层DLLM的结构或训练过程,具有更好的通用性和可扩展性。
关键设计:长度正则化项的具体形式未知,论文中可能涉及对置信度估计进行加权或调整的函数,以平衡不同长度文本的生成概率。具体的参数设置和损失函数细节未知,但其目标是最小化长度偏差,使模型能够更准确地评估不同长度文本的语义合理性。网络结构方面,LR-DLLM没有引入新的网络结构,而是基于现有的DLLM进行改进。
🖼️ 关键图片
📊 实验亮点
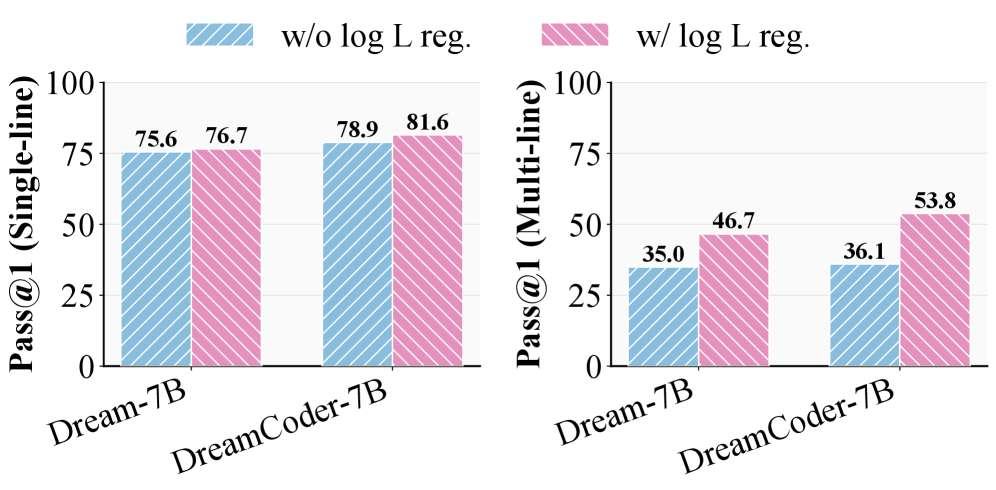
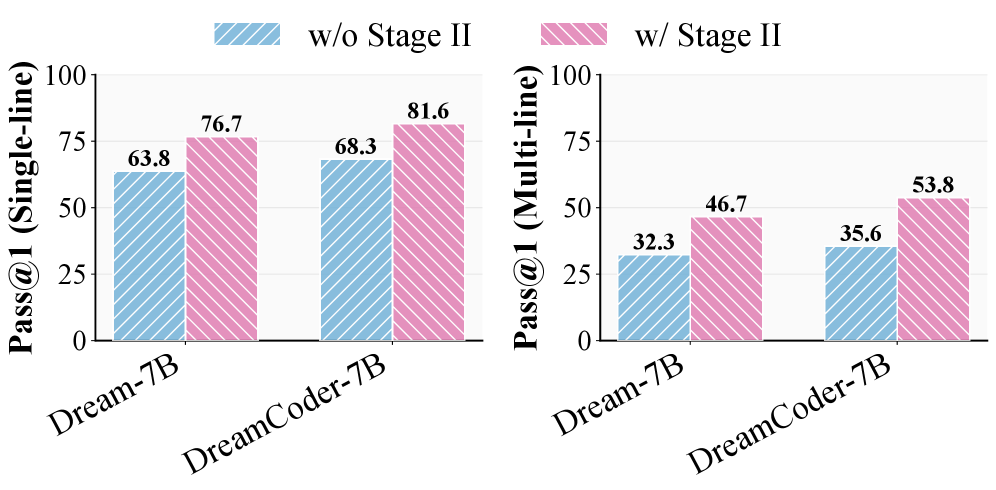
LR-DLLM在HumanEvalInfilling和McEval数据集上取得了显著的性能提升。在完全未知长度的情况下,LR-DLLM在HumanEvalInfilling上实现了51.3%的Pass@1,比DreamOn高出13.4%。在四种语言的McEval上,LR-DLLM实现了51.5%的平均Pass@1,比DreamOn高出14.3%。这些结果表明,LR-DLLM能够有效地解决DLLM在变长生成任务中的问题。
🎯 应用场景
LR-DLLM在代码补全、文本续写、机器翻译等领域具有广泛的应用前景。它可以提高代码补全的准确性和效率,减少文本续写的冗余和不连贯性,并改善机器翻译的流畅性和自然度。该研究对于提升语言生成模型的实用性和可靠性具有重要意义。
📄 摘要(原文)
Diffusion Large Language Models (DLLMs) are inherently ill-suited for variable-length generation, as their inference is defined on a fixed-length canvas and implicitly assumes a known target length. When the length is unknown, as in realistic completion and infilling, naively comparing confidence across mask lengths becomes systematically biased, leading to under-generation or redundant continuations. In this paper, we show that this failure arises from an intrinsic lengthinduced bias in generation confidence estimates, leaving existing DLLMs without a robust way to determine generation length and making variablelength inference unreliable. To address this issue, we propose LR-DLLM, a length-regularized inference framework for DLLMs that treats generation length as an explicit variable and achieves reliable length determination at inference time. It decouples semantic compatibility from lengthinduced uncertainty through an explicit length regularization that corrects biased confidence estimates. Based on this, LR-DLLM enables dynamic expansion or contraction of the generation span without modifying the underlying DLLM or its training procedure. Experiments show that LRDLLM achieves 51.3% Pass@1 on HumanEvalInfilling under fully unknown lengths (+13.4% vs. DreamOn) and 51.5% average Pass@1 on four-language McEval (+14.3% vs. DreamOn).