Training-Driven Representational Geometry Modularization Predicts Brain Alignment in Language Models
作者: Yixuan Liu, Zhiyuan Ma, Likai Tang, Runmin Gan, Xinche Zhang, Jinhao Li, Chao Xie, Sen Song
分类: q-bio.NC, cs.CL
发布日期: 2026-02-07
💡 一句话要点
训练驱动的表征几何模块化预测语言模型中的大脑对齐
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 表征几何 大脑对齐 神经表征 认知科学
📋 核心要点
- 大型语言模型与人脑语言处理的对齐程度是认知科学的关键问题,现有方法缺乏对模型内部表征几何的深入理解。
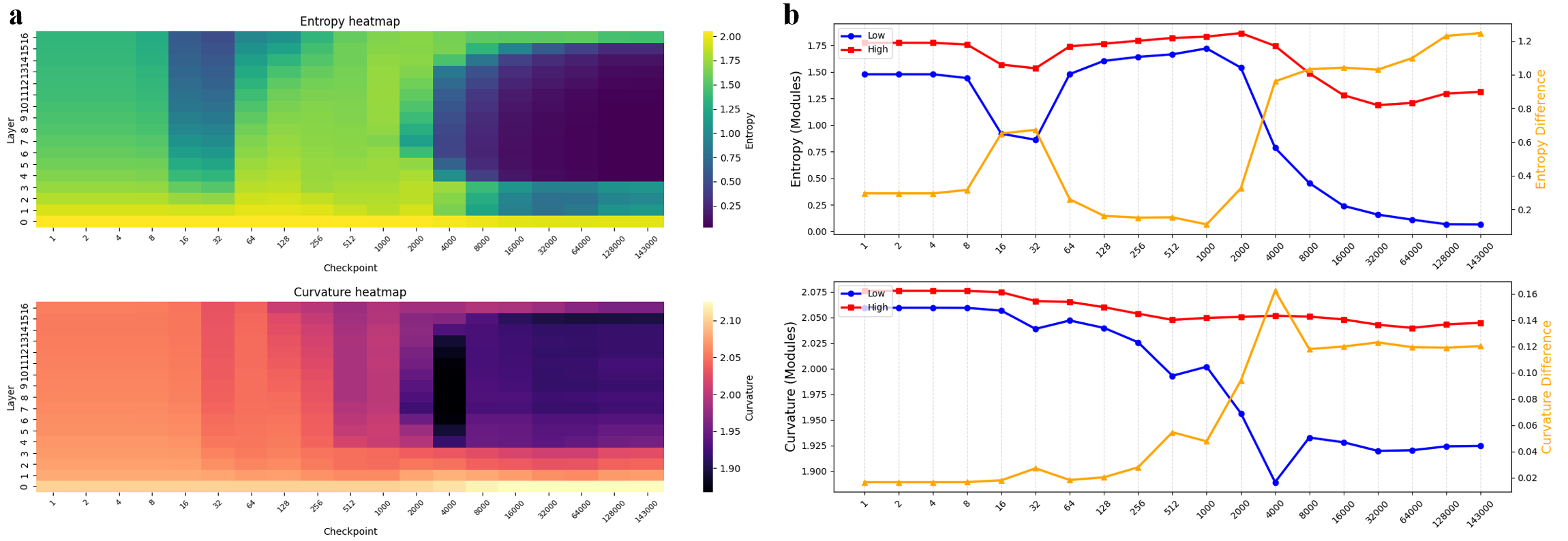
- 该研究通过追踪LLM训练过程中的表征几何变化(熵、曲率),揭示了模型层自组织成低/高复杂度模块的现象。
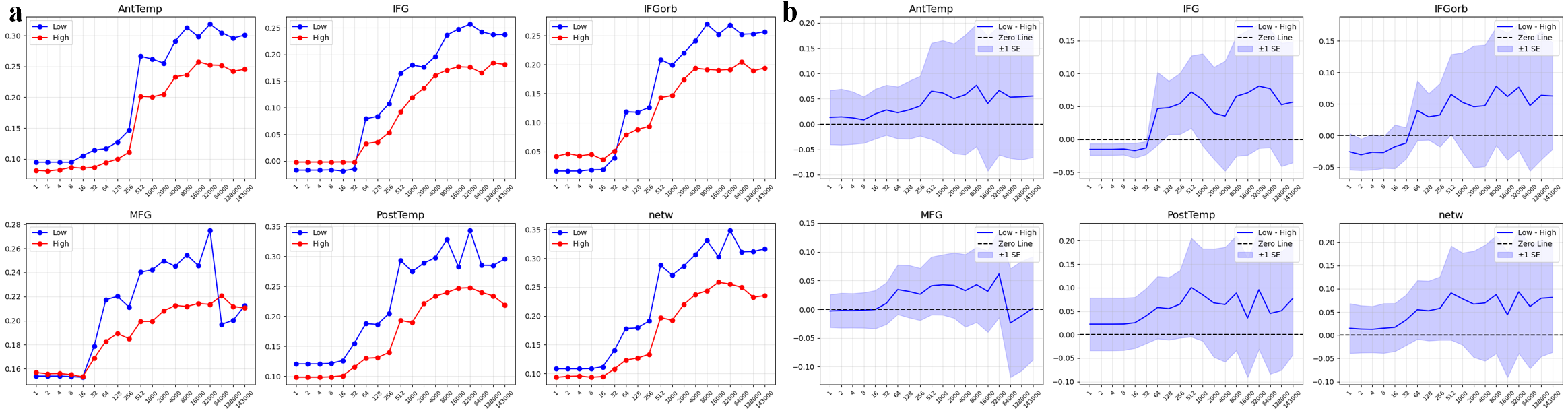
- 实验表明,低复杂度模块的几何特征(低熵、低曲率)能更好地预测人脑语言网络活动,尤其是在颞叶区域。
📝 摘要(中文)
大型语言模型(LLMs)如何与人类语言的神经表征和计算对齐是认知科学的核心问题。本文以表征几何为视角,通过追踪Pythia模型(70M-1B)训练过程中的熵、曲率和fMRI编码得分来研究这个问题。研究发现了一种几何模块化现象,即模型层自组织成稳定的低复杂度和高复杂度簇。低复杂度模块以较低的熵和曲率为特征,能够更好地预测人类语言网络活动。这种对齐遵循异质的时空轨迹:在颞叶区域(AntTemp, PostTemp)快速且稳定,但在额叶区域(IFG, IFGorb)延迟且动态。关键的是,即使在控制了训练进度后,降低的曲率仍然是模型-大脑对齐的可靠预测指标,并且这种效应随着模型规模的扩大而增强。这些结果将训练驱动的几何重组与颞叶-额叶功能专门化联系起来,表明表征平滑促进了类似神经的语言处理。
🔬 方法详解
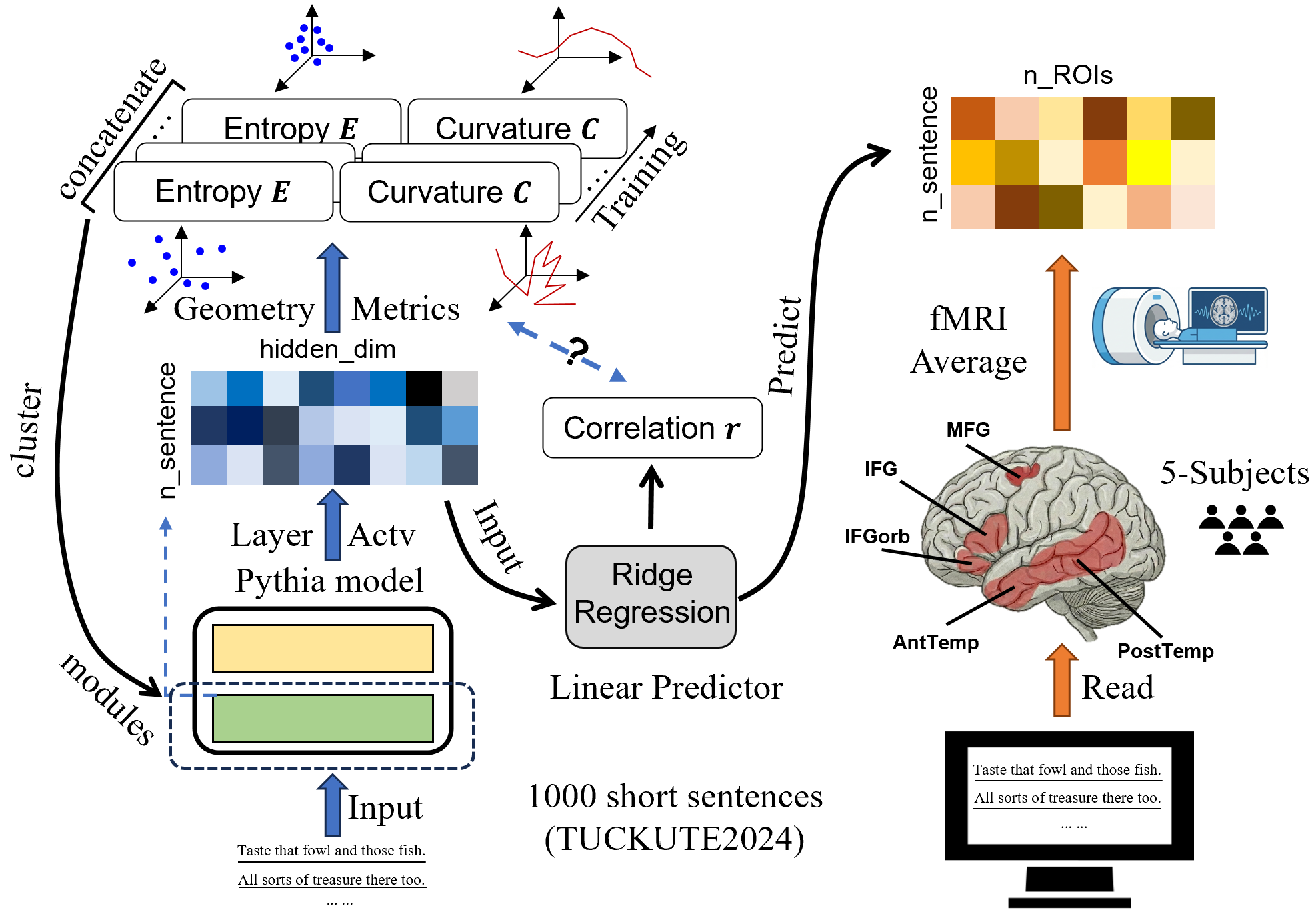
问题定义:该论文旨在研究大型语言模型(LLMs)如何与人类大脑的语言处理机制对齐。现有方法通常关注模型性能或直接比较模型输出与大脑活动,但缺乏对模型内部表征几何的深入理解,难以解释对齐现象背后的机制。
核心思路:论文的核心思路是通过追踪LLM训练过程中表征几何的变化,寻找与大脑活动相关的几何特征。具体来说,研究关注熵和曲率这两个几何指标,并假设模型层会自组织成具有不同复杂度的模块,这些模块可能对应于大脑中不同的功能区域。
技术框架:整体框架包括以下几个主要步骤:1) 使用Pythia系列模型(70M-1B)进行训练;2) 在训练过程中,定期提取模型各层的表征,并计算其熵和曲率;3) 使用fMRI数据测量人类大脑在语言处理任务中的活动;4) 将模型的几何特征(熵、曲率)与fMRI数据进行关联,评估模型与大脑的对齐程度;5) 分析不同脑区(颞叶、额叶)的对齐轨迹。
关键创新:该研究的关键创新在于:1) 将表征几何引入到LLM与大脑对齐的研究中,提供了一种新的分析视角;2) 发现了训练驱动的几何模块化现象,即模型层自组织成低复杂度和高复杂度模块;3) 证明了低曲率是模型-大脑对齐的可靠预测指标,即使在控制了训练进度后仍然有效。
关键设计:论文的关键设计包括:1) 使用Pythia模型,因为它是一个开源的、可复现的LLM;2) 使用熵和曲率作为表征几何的指标,因为它们可以反映表征的复杂度和平滑程度;3) 使用fMRI数据作为大脑活动的测量,因为它具有较高的空间分辨率;4) 使用编码模型将模型的几何特征与fMRI数据进行关联,评估模型与大脑的对齐程度。
🖼️ 关键图片
📊 实验亮点
研究发现,在Pythia模型训练过程中,模型层自组织成低复杂度和高复杂度模块,其中低复杂度模块(低熵、低曲率)能更好地预测人脑语言网络活动。即使控制训练进度后,低曲率仍然是模型-大脑对齐的可靠预测指标,且该效应随模型规模增大而增强。颞叶区域的对齐快速稳定,而额叶区域的对齐延迟且动态。
🎯 应用场景
该研究成果可应用于指导LLM的训练和设计,使其更符合人类大脑的认知机制,提高其在自然语言处理任务中的性能和泛化能力。此外,该研究也有助于深入理解人类语言的神经基础,为认知科学和神经科学提供新的见解。
📄 摘要(原文)
How large language models (LLMs) align with the neural representation and computation of human language is a central question in cognitive science. Using representational geometry as a mechanistic lens, we addressed this by tracking entropy, curvature, and fMRI encoding scores throughout Pythia (70M-1B) training. We identified a geometric modularization where layers self-organize into stable low- and high-complexity clusters. The low-complexity module, characterized by reduced entropy and curvature, consistently better predicted human language network activity. This alignment followed heterogeneous spatial-temporal trajectories: rapid and stable in temporal regions (AntTemp, PostTemp), but delayed and dynamic in frontal areas (IFG, IFGorb). Crucially, reduced curvature remained a robust predictor of model-brain alignment even after controlling for training progress, an effect that strengthened with model scale. These results links training-driven geometric reorganization to temporal-frontal functional specialization, suggesting that representational smoothing facilitates neural-like linguistic processing.