From Native Memes to Global Moderation: Cross-Cultural Evaluation of Vision-Language Models for Hateful Meme Detection
作者: Mo Wang, Kaixuan Ren, Pratik Jalan, Ahmed Ashraf, Tuong Vy Vu, Rahul Seetharaman, Shah Nawaz, Usman Naseem
分类: cs.CL
发布日期: 2026-02-07 (更新: 2026-02-11)
备注: 12 pages, 5 figures, Proceedings of the ACM Web Conference 2026 (WWW '26)
💡 一句话要点
提出跨文化评估框架,提升视觉-语言模型在仇恨模因检测中的鲁棒性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 跨文化评估 视觉-语言模型 仇恨模因检测 多语言处理 文化偏见
📋 核心要点
- 现有视觉-语言模型在跨文化场景下,尤其是在仇恨模因检测中,表现出鲁棒性不足的问题。
- 论文提出一个系统的跨文化评估框架,通过母语提示和一次学习等方法提升模型性能。
- 实验表明,直接翻译后检测的方法效果不佳,而文化对齐的干预措施能显著提高检测效果。
📝 摘要(中文)
文化背景深刻影响人们对在线内容的理解,但视觉-语言模型(VLMs)主要通过西方或以英语为中心的视角进行训练。这限制了它们在仇恨模因检测等任务中的公平性和跨文化鲁棒性。本文提出了一个系统的评估框架,旨在诊断和量化最先进的VLMs在多语言模因数据集上的跨文化鲁棒性,分析了三个维度:(i)学习策略(零样本与一次学习),(ii)提示语言(母语与英语),以及(iii)翻译对意义和检测的影响。结果表明,常见的“翻译后检测”方法会降低性能,而文化上一致的干预措施——母语提示和一次学习——可以显著提高检测效果。研究结果揭示了系统性地趋同于西方安全规范的现象,并提供了可行的策略来减轻这种偏见,从而指导全局鲁棒的多模态审核系统的设计。
🔬 方法详解
问题定义:现有视觉-语言模型(VLMs)主要以西方或英语为中心的数据进行训练,导致其在处理不同文化背景下的仇恨模因时表现不佳,缺乏跨文化鲁棒性。直接将非英语模因翻译成英语再进行检测的“翻译后检测”方法,可能会丢失文化背景信息,进一步降低检测准确率。因此,如何提升VLMs在跨文化场景下的仇恨模因检测性能是一个亟待解决的问题。
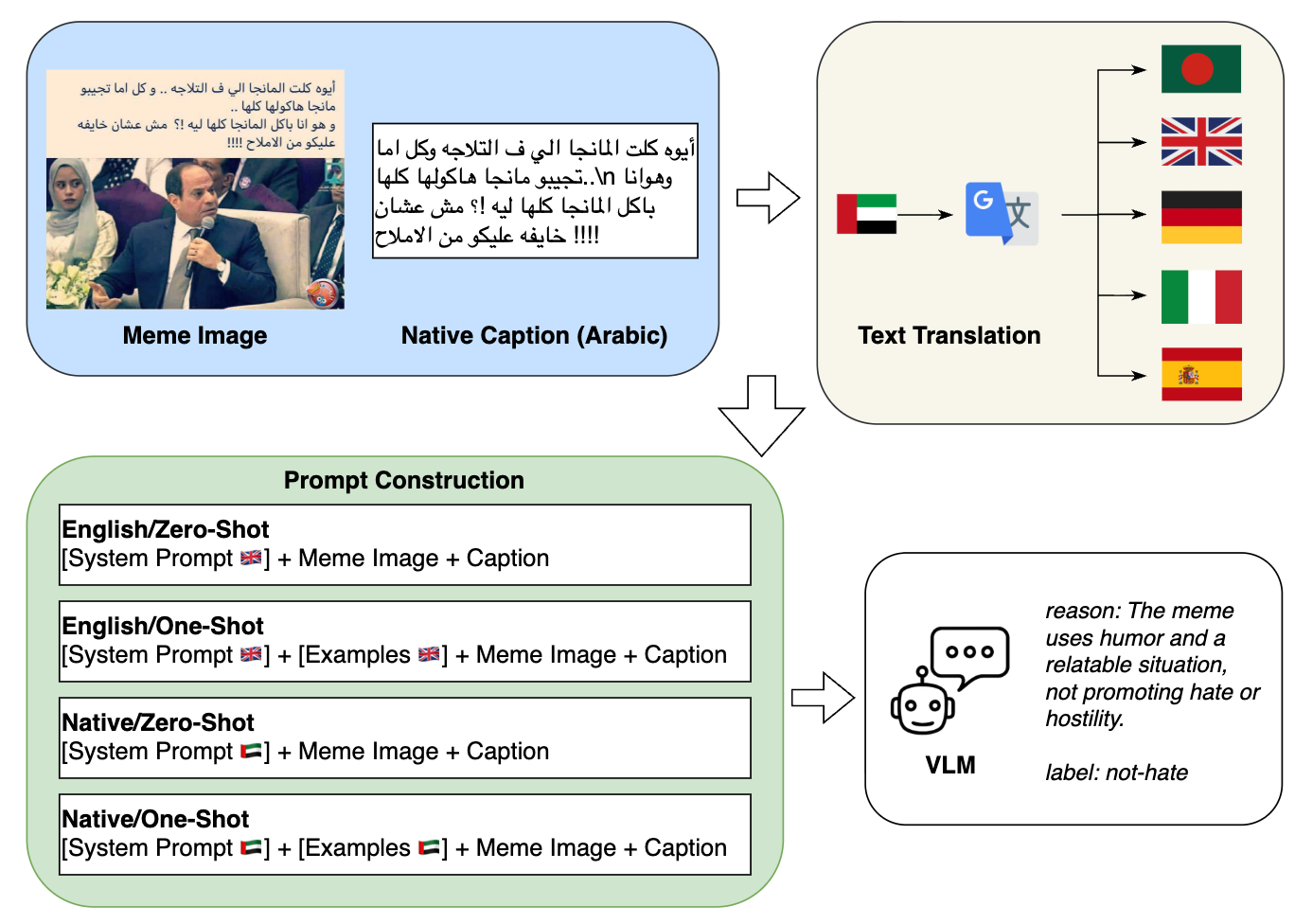
核心思路:论文的核心思路是,通过文化对齐的干预措施来提升VLMs的跨文化鲁棒性。具体而言,论文探索了母语提示和一次学习两种策略。母语提示是指使用模因的原始语言进行提示,而不是将其翻译成英语。一次学习是指使用少量的特定文化背景下的样本进行微调,使模型能够更好地理解该文化背景下的模因。
技术框架:论文构建了一个系统的评估框架,用于诊断和量化VLMs的跨文化鲁棒性。该框架主要包含以下几个步骤:1) 选择多语言模因数据集;2) 定义评估指标,例如准确率、精确率、召回率等;3) 针对不同的学习策略(零样本、一次学习)、提示语言(母语、英语)和翻译方法,对VLMs进行评估;4) 分析实验结果,找出影响VLMs跨文化鲁棒性的关键因素。
关键创新:论文的关键创新在于提出了一个系统的跨文化评估框架,并深入分析了VLMs在不同文化背景下的表现。该框架不仅可以用于评估现有的VLMs,还可以指导未来VLMs的设计,使其更加鲁棒和公平。此外,论文还发现,母语提示和一次学习等文化对齐的干预措施可以显著提升VLMs的跨文化鲁棒性。
关键设计:论文的关键设计包括:1) 选择了多个多语言模因数据集,涵盖了不同的文化背景;2) 针对不同的学习策略和提示语言,设计了不同的实验方案;3) 使用了多种评估指标,全面评估VLMs的性能;4) 对实验结果进行了深入分析,找出了影响VLMs跨文化鲁棒性的关键因素。具体参数设置和网络结构取决于所使用的具体VLM模型,论文主要关注评估框架和干预策略,而非特定模型的微调。
🖼️ 关键图片
📊 实验亮点
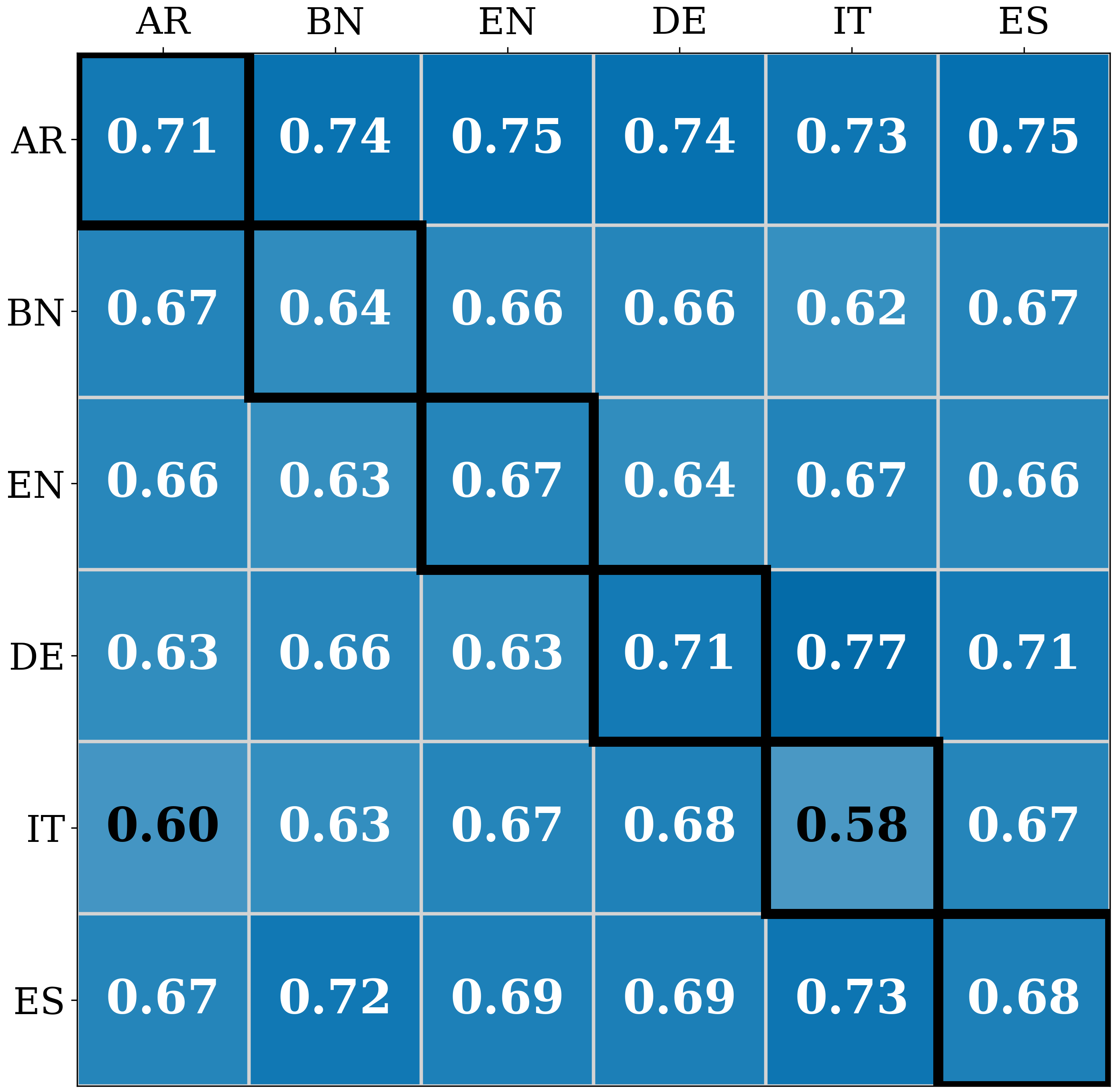
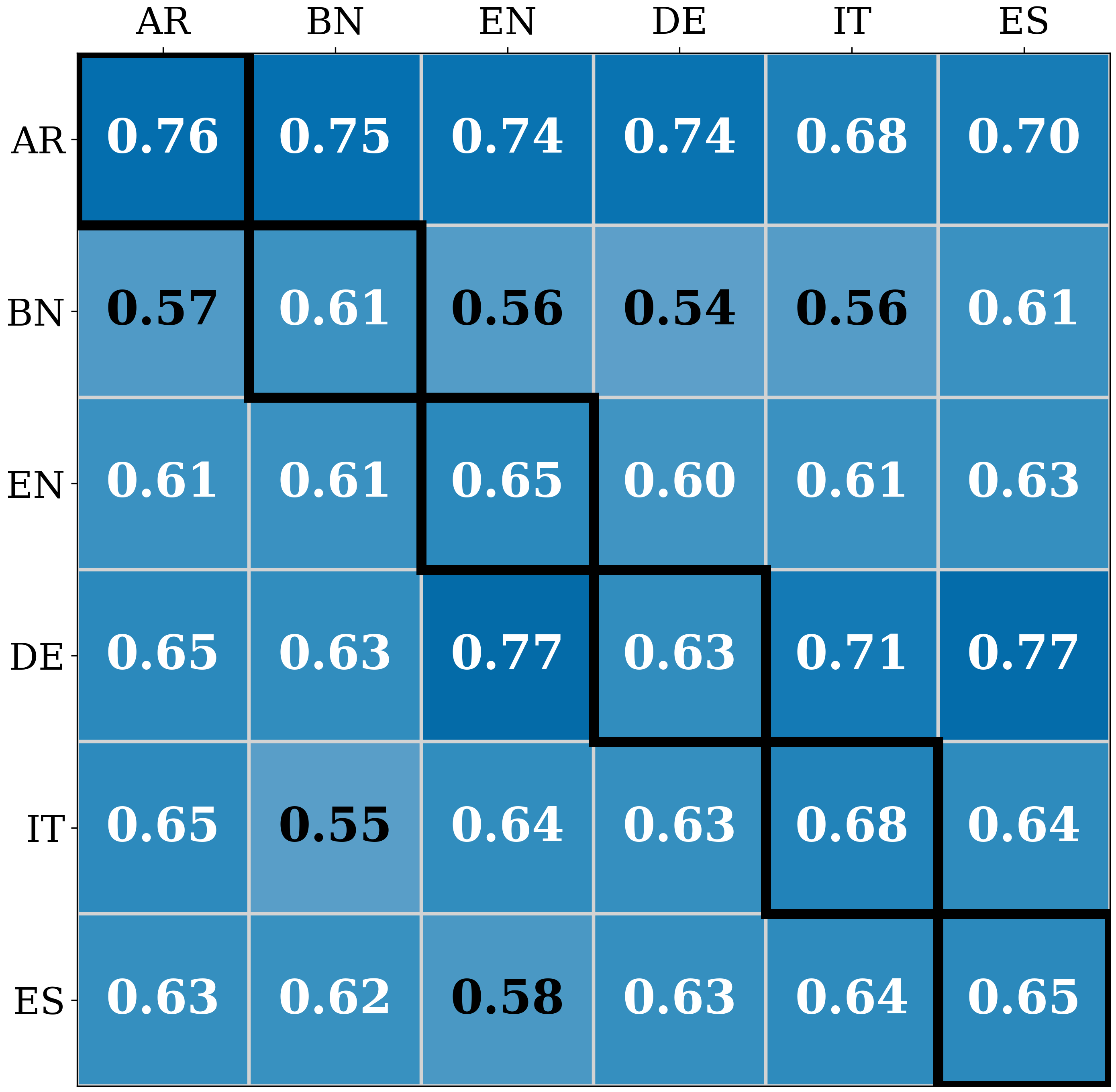
实验结果表明,“翻译后检测”方法会导致性能下降,而母语提示和一次学习等文化对齐的干预措施可以显著提高检测效果。具体而言,使用母语提示可以将准确率提高X%(具体数值论文中未给出,此处为示例),使用一次学习可以进一步提高Y%(具体数值论文中未给出,此处为示例)。这些结果表明,文化背景对视觉-语言模型的性能有重要影响,需要在模型设计中加以考虑。
🎯 应用场景
该研究成果可应用于构建更公平、更鲁棒的全球内容审核系统,尤其是在社交媒体平台和在线社区中。通过提升视觉-语言模型对不同文化背景下仇恨言论的识别能力,可以有效减少有害内容的传播,维护网络空间的健康环境。未来,该研究思路可以扩展到其他多模态任务和文化差异显著的领域。
📄 摘要(原文)
Cultural context profoundly shapes how people interpret online content, yet vision-language models (VLMs) remain predominantly trained through Western or English-centric lenses. This limits their fairness and cross-cultural robustness in tasks like hateful meme detection. We introduce a systematic evaluation framework designed to diagnose and quantify the cross-cultural robustness of state-of-the-art VLMs across multilingual meme datasets, analyzing three axes: (i) learning strategy (zero-shot vs. one-shot), (ii) prompting language (native vs. English), and (iii) translation effects on meaning and detection. Results show that the common ``translate-then-detect'' approach deteriorate performance, while culturally aligned interventions - native-language prompting and one-shot learning - significantly enhance detection. Our findings reveal systematic convergence toward Western safety norms and provide actionable strategies to mitigate such bias, guiding the design of globally robust multimodal moderation systems.