SED-SFT: Selectively Encouraging Diversity in Supervised Fine-Tuning
作者: Yijie Chen, Yijin Liu, Fandong Meng
分类: cs.CL
发布日期: 2026-02-07
备注: The code is publicly available at https://github.com/pppa2019/SED-SFT
🔗 代码/项目: GITHUB
💡 一句话要点
SED-SFT:通过选择性鼓励多样性来提升监督式微调效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 监督式微调 多样性鼓励 熵正则化 强化学习 大型语言模型
📋 核心要点
- 传统SFT使用交叉熵损失易导致模式崩溃,限制了后续强化学习的探索效率。
- SED-SFT通过选择性熵正则化,自适应地鼓励模型在token探索空间中的多样性。
- 实验表明,SED-SFT在提升生成多样性的同时,显著提高了后续强化学习的性能。
📝 摘要(中文)
监督式微调(SFT)结合强化学习(RL)已成为大型语言模型(LLMs)的标准后训练范式。然而,传统的SFT过程受交叉熵(CE)损失驱动,常常导致模式崩溃,模型过度集中于特定的响应模式。这种分布多样性的缺乏严重限制了后续RL所需的探索效率。虽然最近的研究试图通过替换CE损失来改进SFT,旨在保持多样性或改进更新策略,但它们未能充分平衡多样性和准确性,从而在RL之后产生次优性能。为了解决模式崩溃问题,我们提出了SED-SFT,它基于token探索空间自适应地鼓励多样性。该框架将带有选择性掩蔽机制的选择性熵正则化项引入到优化目标中。在八个数学基准上的大量实验表明,与CE损失相比,SED-SFT显著提高了生成多样性,且计算开销增加可忽略不计,在Llama-3.2-3B-Instruct和Qwen2.5-Math-7B-Instruct上,后续RL性能分别平均提高了2.06和1.20个点。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在监督式微调(SFT)过程中出现的“模式崩溃”问题。现有方法过度依赖交叉熵损失,导致模型生成结果单一,缺乏多样性,从而限制了后续强化学习阶段的探索效率。现有改进方法往往无法很好地平衡多样性和准确性,导致最终性能不佳。
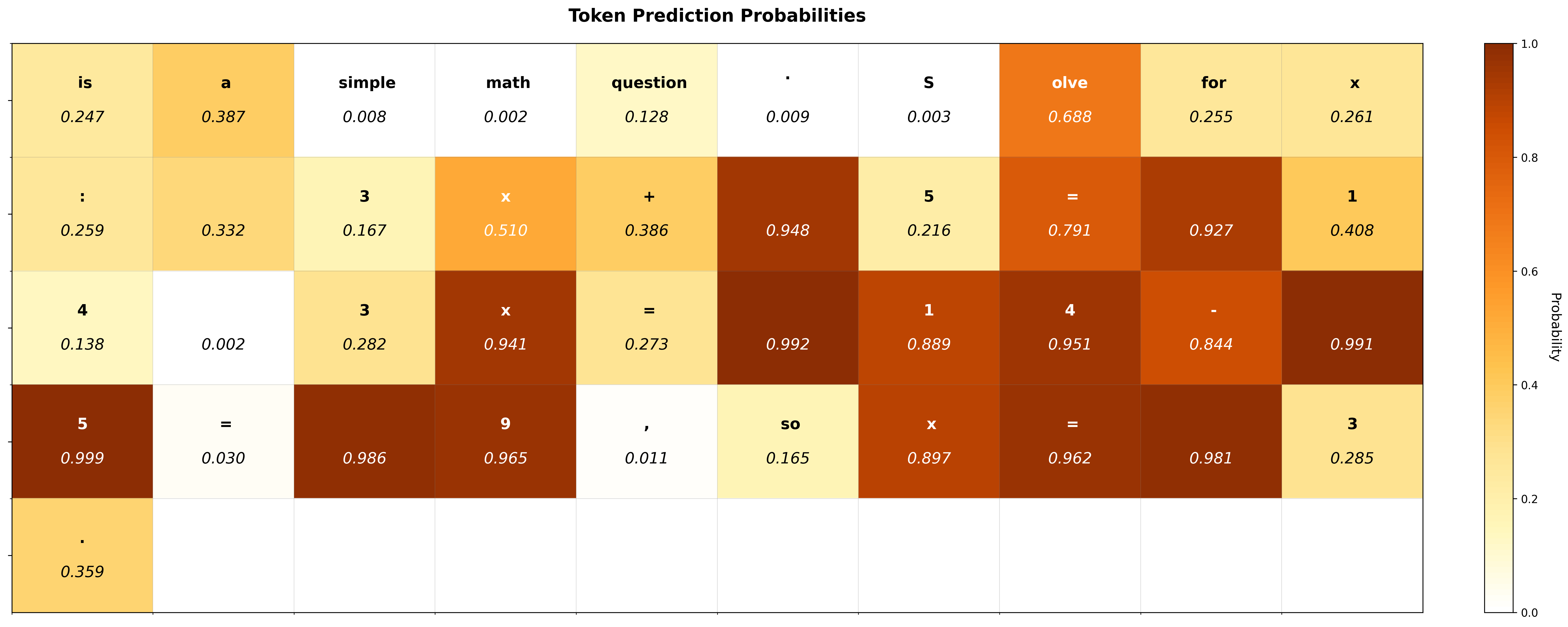
核心思路:SED-SFT的核心思路是自适应地鼓励模型生成的多样性,尤其是在模型探索空间较大的token上。通过引入选择性熵正则化项,使得模型在预测不确定的token时,倾向于生成更多样化的结果,从而避免过早收敛到单一模式。
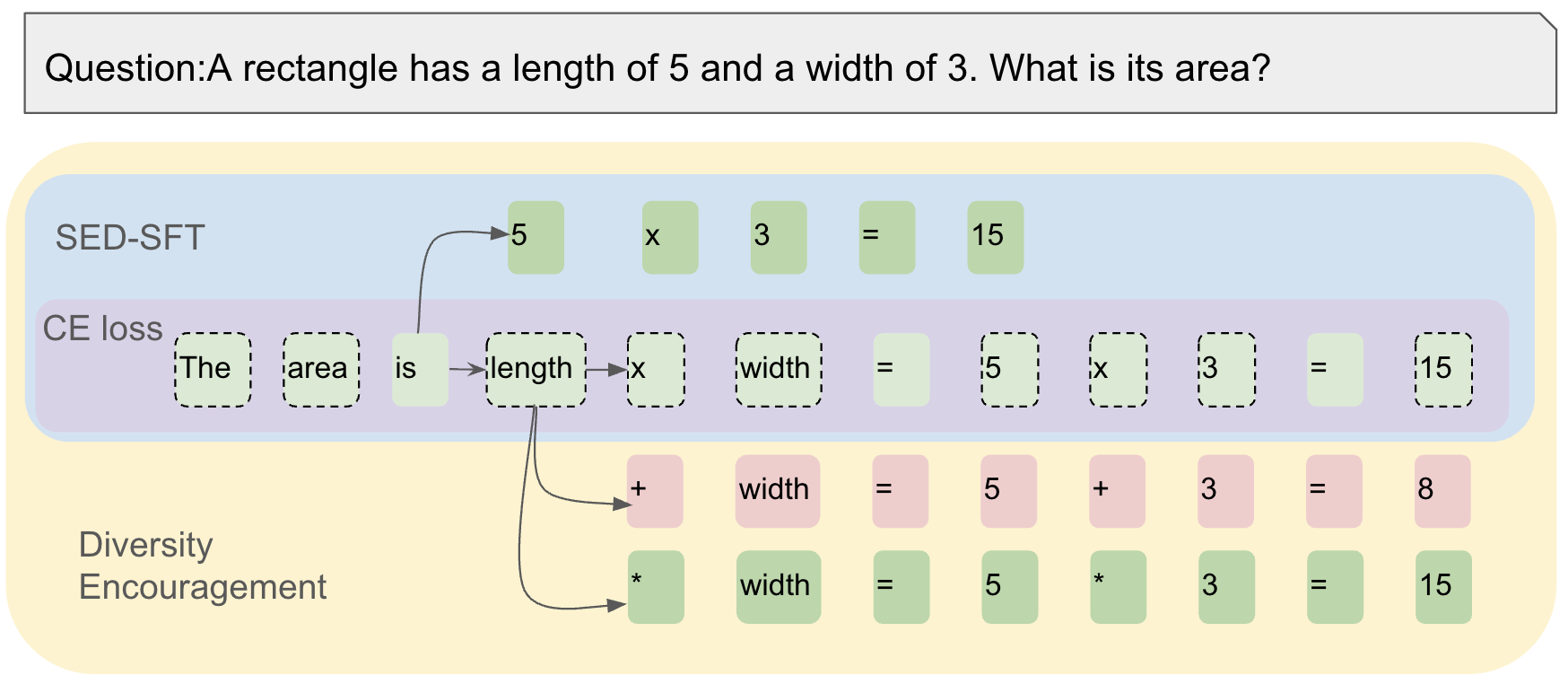
技术框架:SED-SFT框架主要是在标准的SFT训练过程中,在交叉熵损失函数的基础上增加一个选择性熵正则化项。该正则化项通过一个选择性掩蔽机制来控制,只对模型预测不确定性较高的token进行多样性鼓励。整体流程与标准SFT类似,但在损失函数计算和反向传播阶段有所不同。
关键创新:SED-SFT的关键创新在于“选择性”地鼓励多样性。与直接替换或修改交叉熵损失的方法不同,SED-SFT保留了交叉熵损失的主导地位,仅在必要时通过熵正则化来提升多样性。这种选择性机制能够更好地平衡多样性和准确性,避免过度干预模型的学习过程。
关键设计:SED-SFT的关键设计包括:1)选择性掩蔽机制:用于确定哪些token需要进行多样性鼓励,通常基于模型预测概率的熵值或置信度;2)熵正则化项:用于衡量模型生成结果的多样性,并将其添加到损失函数中,引导模型生成更多样化的结果;3)正则化系数:用于控制熵正则化项的强度,需要根据具体任务和数据集进行调整。
🖼️ 关键图片
📊 实验亮点
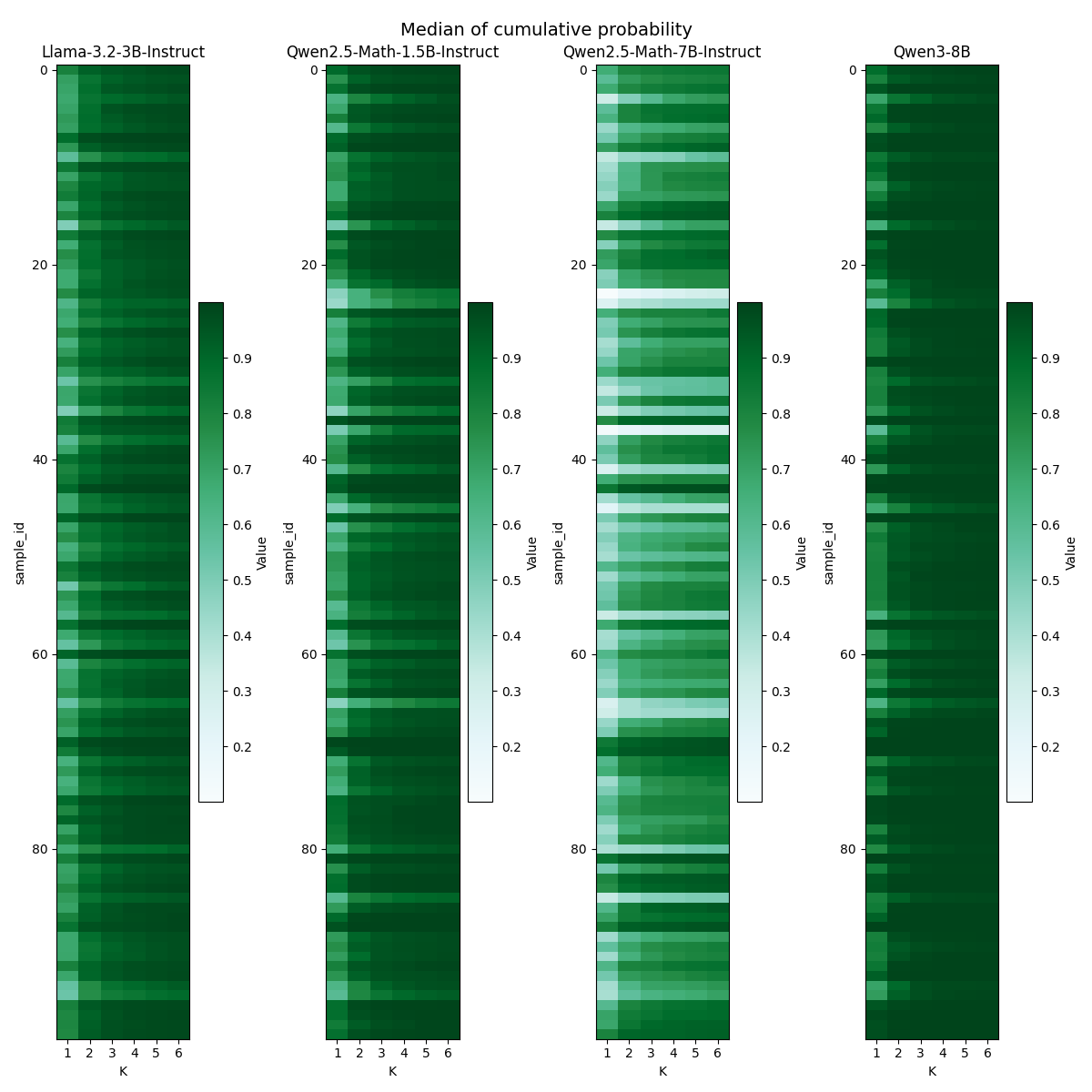
SED-SFT在八个数学基准测试中表现出色,与基于标准交叉熵的基线方法相比,在Llama-3.2-3B-Instruct和Qwen2.5-Math-7B-Instruct上,后续强化学习性能分别平均提高了2.06和1.20个点。同时,SED-SFT的计算开销增加可忽略不计,证明了其在提升性能的同时,保持了较高的效率。
🎯 应用场景
SED-SFT方法可广泛应用于各种需要提升生成多样性的自然语言处理任务中,例如对话生成、文本摘要、机器翻译等。通过提高模型生成结果的多样性,可以改善用户体验,提升模型在复杂场景下的适应能力,并为后续的强化学习提供更好的探索空间。该方法尤其适用于需要模型具备创造性和灵活性的应用场景。
📄 摘要(原文)
Supervised Fine-Tuning (SFT) followed by Reinforcement Learning (RL) has emerged as the standard post-training paradigm for large language models (LLMs). However, the conventional SFT process, driven by Cross-Entropy (CE) loss, often induces mode collapse, where models over-concentrate on specific response patterns. This lack of distributional diversity severely restricts the exploration efficiency required for subsequent RL. While recent studies have attempted to improve SFT by replacing the CE loss, aiming to preserve diversity or refine the update policy, they fail to adequately balance diversity and accuracy, thereby yielding suboptimal performance after RL. To address the mode collapse problem, we propose SED-SFT, which adaptively encourages diversity based on the token exploration space. This framework introduces a selective entropy regularization term with a selective masking mechanism into the optimization objective. Extensive experiments across eight mathematical benchmarks demonstrate that SED-SFT significantly enhances generation diversity with a negligible computational overhead increase compared with CE loss, yielding average improvements of 2.06 and 1.20 points in subsequent RL performance over standard CE-based baselines on Llama-3.2-3B-Instruct and Qwen2.5-Math-7B-Instruct, respectively. The code is publicly available at https://github.com/pppa2019/SED-SFT