DLLM Agent: See Farther, Run Faster
作者: Huiling Zhen, Weizhe Lin, Renxi Liu, Kai Han, Yiming Li, Yuchuan Tian, Hanting Chen, Xiaoguang Li, Xiaosong Li, Chen Chen, Xianzhi Yu, Mingxuan Yuan, Youliang Yan, Peifeng Qin, Jun Wang, Yu Wang, Dacheng Tao, Yunhe Wang
分类: cs.CL
发布日期: 2026-02-07 (更新: 2026-02-10)
💡 一句话要点
提出DLLM Agent,利用扩散模型提升Agent多步决策效率与规划能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散模型 大语言模型 Agent 多步决策 工具使用
📋 核心要点
- 现有Agent通常采用自回归模型进行决策,效率较低,限制了其在复杂任务中的应用。
- 本文提出DLLM Agent,利用扩散模型进行决策,旨在提高Agent的规划能力和端到端效率。
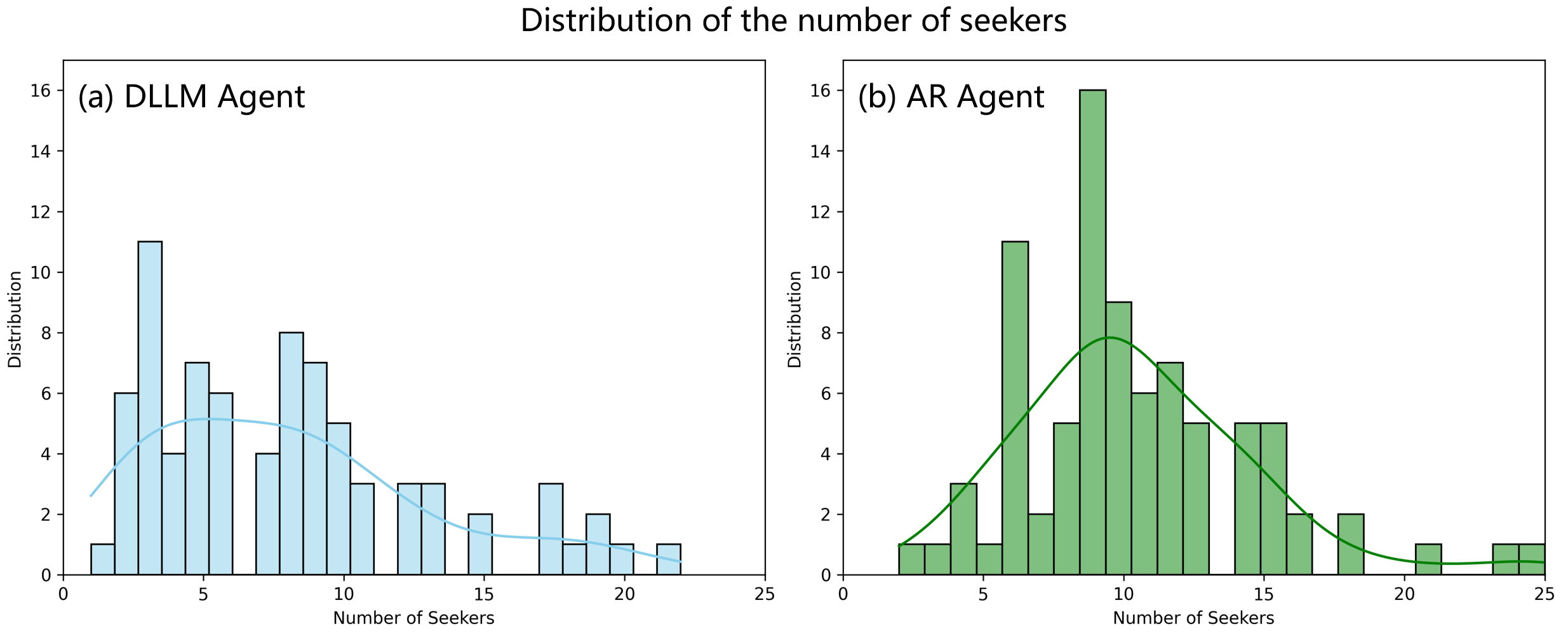
- 实验表明,DLLM Agent在精度相当的情况下,比AR Agent快30%以上,某些情况下甚至超过8倍。
📝 摘要(中文)
扩散大语言模型(DLLM)作为自回归(AR)解码的替代方案,在效率和建模特性方面具有吸引力,但其在Agent多步决策中的应用仍未得到充分探索。本文研究了一个具体问题:当生成范式改变但Agent框架和监督保持不变时,扩散模型是否会引起系统性不同的规划和工具使用行为,以及这些差异是否转化为端到端效率的提升?通过在同一Agent工作流(DeepDiver)中实例化DLLM和AR骨干网络,并在相同的轨迹数据上进行Agent导向的微调,构建了基于扩散的DLLM Agent和直接可比的AR Agent。实验表明,在相当的精度下,DLLM Agent的端到端速度平均比AR Agent快30%以上,某些情况下甚至超过8倍。在完成正确任务的前提下,DLLM Agent也需要更少的交互轮次和工具调用,这与更高的规划命中率相一致,即能更快地收敛到正确的动作路径,减少回溯。此外,本文还确定了在工具使用Agent中部署扩散模型的两个实际考虑因素:一是朴素的DLLM策略更容易出现结构化的工具调用失败,需要更强的工具调用特定训练来生成有效的模式和参数;二是对于交错上下文和动作跨度的多轮输入,扩散风格的跨度损坏需要对齐的注意力掩码,以避免虚假的上下文-动作信息流;否则,性能会下降。最后,本文分析了跨工作流阶段的注意力动态,并观察到特定于范式的协调模式,表明基于扩散的Agent具有更强的全局规划信号。
🔬 方法详解
问题定义:现有Agent通常依赖自回归(AR)模型进行多步决策,这种方式存在固有的效率瓶颈,尤其是在需要大量交互和工具调用的复杂任务中。自回归模型需要逐步生成每个token,导致推理速度较慢,限制了Agent的实时性和可扩展性。因此,如何提升Agent的决策效率,使其能够更快地完成任务,是一个重要的研究问题。
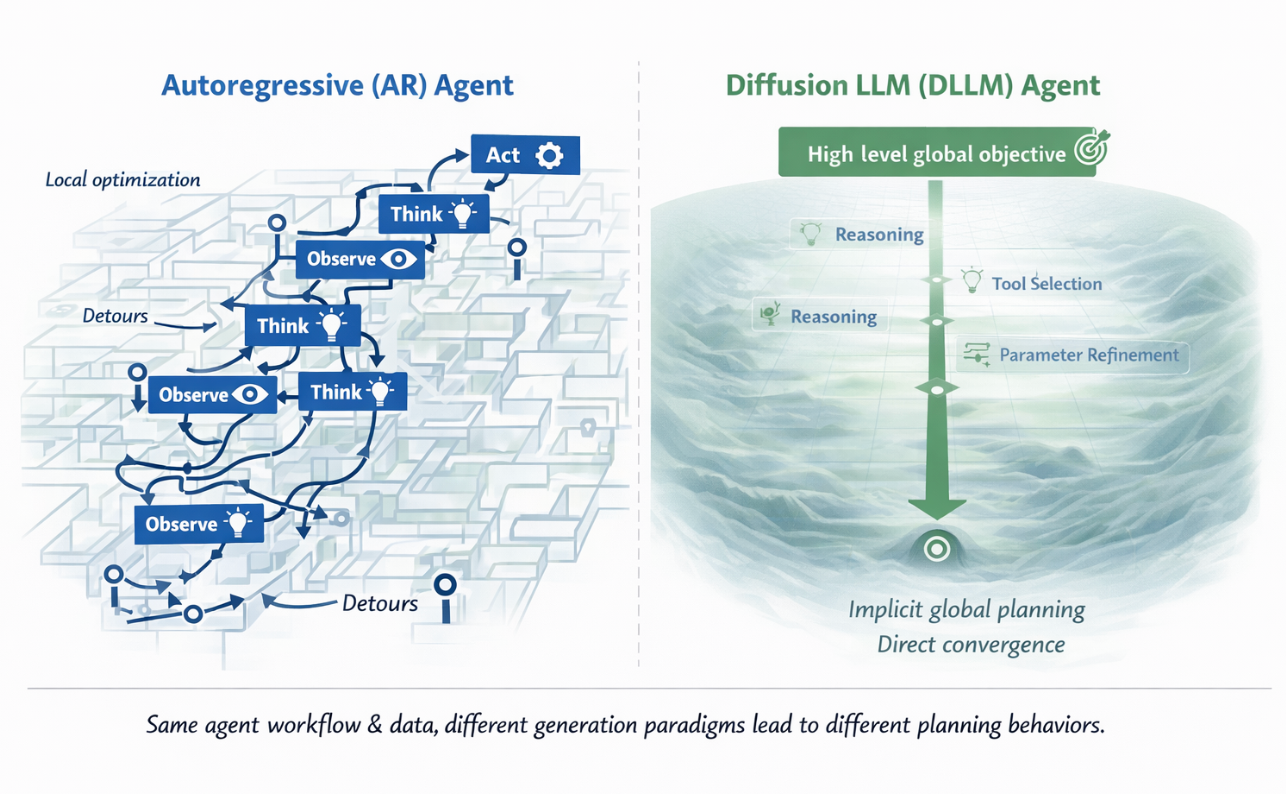
核心思路:本文的核心思路是利用扩散大语言模型(DLLM)替代传统的自回归模型作为Agent的骨干网络。扩散模型通过迭代去噪的方式生成文本,具有并行生成token的潜力,从而可以显著提高生成速度。此外,扩散模型在建模能力方面也具有优势,有望提升Agent的规划能力和决策质量。
技术框架:本文采用DeepDiver作为Agent框架,并在其中分别实例化DLLM和AR骨干网络,构建DLLM Agent和AR Agent。整个流程包括以下几个主要阶段:1) 观察环境并获取上下文信息;2) 利用骨干网络(DLLM或AR)生成动作序列;3) 执行动作并更新环境状态;4) 根据环境反馈调整规划。通过在相同的轨迹数据上进行Agent导向的微调,保证了两种Agent的可比性。
关键创新:本文最重要的技术创新在于将扩散模型引入到Agent的多步决策过程中,并验证了其在效率和规划能力方面的优势。与传统的自回归Agent相比,DLLM Agent能够更快地生成动作序列,从而显著提升端到端效率。此外,本文还针对DLLM在工具使用Agent中的应用,提出了两种实用的解决方案:一是加强工具调用特定训练,以避免结构化的工具调用失败;二是采用对齐的注意力掩码,以避免虚假的上下文-动作信息流。
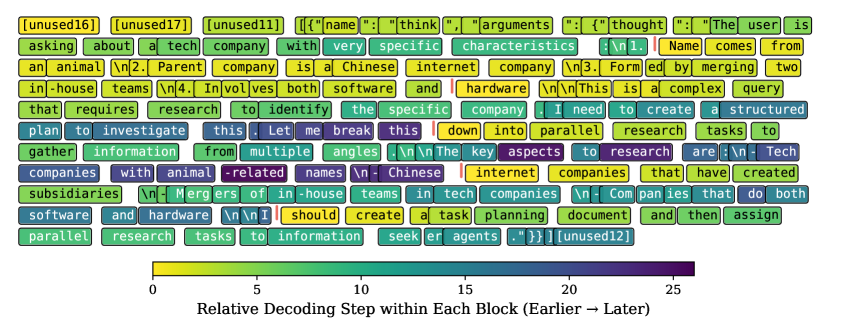
关键设计:在DLLM Agent的设计中,关键的技术细节包括:1) 采用扩散模型作为骨干网络,并进行Agent导向的微调;2) 针对工具调用失败问题,设计了专门的训练策略;3) 针对多轮输入,采用了对齐的注意力掩码。此外,本文还分析了跨工作流阶段的注意力动态,以理解DLLM Agent的规划机制。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在相当的精度下,DLLM Agent的端到端速度平均比AR Agent快30%以上,某些情况下甚至超过8倍。此外,DLLM Agent在完成正确任务的前提下,也需要更少的交互轮次和工具调用,表明其具有更高的规划命中率。这些结果充分验证了DLLM在Agent多步决策中的优势。
🎯 应用场景
该研究成果可应用于需要快速决策和复杂规划的Agent任务中,例如机器人导航、游戏AI、自动化客服、智能助手等。通过提升Agent的效率和规划能力,可以使其更好地适应复杂多变的环境,并完成更具挑战性的任务。未来,该研究有望推动Agent技术在各个领域的广泛应用。
📄 摘要(原文)
Diffusion large language models (DLLMs) have emerged as an alternative to autoregressive (AR) decoding with appealing efficiency and modeling properties, yet their implications for agentic multi-step decision making remain underexplored. We ask a concrete question: when the generation paradigm is changed but the agent framework and supervision are held fixed, do diffusion backbones induce systematically different planning and tool-use behaviors, and do these differences translate into end-to-end efficiency gains? We study this in a controlled setting by instantiating DLLM and AR backbones within the same agent workflow (DeepDiver) and performing matched agent-oriented fine-tuning on the same trajectory data, yielding diffusion-backed DLLM Agents and directly comparable AR agents. Across benchmarks and case studies, we find that, at comparable accuracy, DLLM Agents are on average over 30% faster end to end than AR agents, with some cases exceeding 8x speedup. Conditioned on correct task completion, DLLM Agents also require fewer interaction rounds and tool invocations, consistent with higher planner hit rates that converge earlier to a correct action path with less backtracking. We further identify two practical considerations for deploying diffusion backbones in tool-using agents. First, naive DLLM policies are more prone to structured tool-call failures, necessitating stronger tool-call-specific training to emit valid schemas and arguments. Second, for multi-turn inputs interleaving context and action spans, diffusion-style span corruption requires aligned attention masking to avoid spurious context-action information flow; without such alignment, performance degrades. Finally, we analyze attention dynamics across workflow stages and observe paradigm-specific coordination patterns, suggesting stronger global planning signals in diffusion-backed agents.