When the Model Said 'No Comment', We Knew Helpfulness Was Dead, Honesty Was Alive, and Safety Was Terrified
作者: Gautam Siddharth Kashyap, Mark Dras, Usman Naseem
分类: cs.CL
发布日期: 2026-02-07
备注: Accepted at EACL Mains 2026
💡 一句话要点
AlignX:通过解耦特征空间和校准专家路由,提升LLM的HHH对齐效果
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 对齐 混合专家模型 提示注入 特征解耦 专家路由 分形几何
📋 核心要点
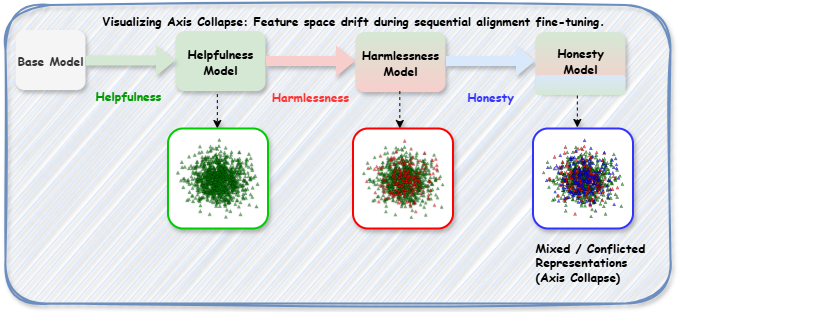
- 现有LLM对齐方法(SFT、MoE)在多目标优化中存在冲突干扰和专家路由错误等问题,导致“轴崩溃”。
- AlignX通过两阶段框架解决轴崩溃:提示注入微调解耦任务特征,MoCaE模块校准专家路由。
- 实验表明,AlignX在帮助性、无害性和诚实性方面显著提升,同时降低了延迟和内存使用。
📝 摘要(中文)
大型语言模型(LLM)需要符合人类价值观——即有帮助性、无害性和诚实性(HHH),这对于安全部署至关重要。现有工作使用监督微调(SFT)和混合专家模型(MoE)来对齐LLM。然而,这些工作在多目标设置中面临挑战,例如SFT导致冲突目标之间的干扰,而MoE则遭受错误校准的路由问题。我们将这种失效模式称为轴崩溃,其特征在于:(1)不相交的特征空间导致灾难性遗忘,以及(2)来自错误路由专家的不可靠推理。为了解决这个问题,我们提出了AlignX,一个两阶段框架。第一阶段使用提示注入微调来提取轴特定的任务特征,从而减轻灾难性遗忘。第二阶段部署了一个MoCaE模块,该模块使用分形和自然几何来校准专家路由,从而提高推理可靠性。AlignX在Alpaca(帮助性)、BeaverTails(无害性)和TruthfulQA(诚实性)上取得了显著的提升,胜率提高+171.5%,真实性-信息性提高+110.1%,安全违规减少4.3%。与之前的MoE相比,它还降低了超过35%的延迟和内存使用。在四个LLM上的结果验证了其泛化性。
🔬 方法详解
问题定义:现有的大型语言模型对齐方法,如监督微调(SFT)和混合专家模型(MoE),在同时优化多个目标(例如,帮助性、无害性和诚实性)时表现不佳。SFT容易导致不同目标之间的干扰,而MoE则可能出现专家路由错误,使得模型无法有效地利用各个专家的知识。这种现象被称为“轴崩溃”,表现为特征空间不连续和推理不可靠。
核心思路:AlignX的核心思路是将多目标对齐问题分解为两个阶段:首先,通过提示注入微调,将不同目标的特征空间解耦,避免灾难性遗忘;然后,使用MoCaE模块,利用分形和自然几何来校准专家路由,提高推理的可靠性。这种方法旨在解决现有方法在多目标优化中存在的冲突和路由问题。
技术框架:AlignX是一个两阶段框架。第一阶段是轴特定特征提取,通过提示注入微调,针对每个目标(例如,帮助性、无害性和诚实性)训练独立的模型,从而提取轴特定的任务特征。第二阶段是MoCaE模块,该模块使用分形和自然几何来校准专家路由,提高推理的可靠性。MoCaE模块的目标是确保输入能够被正确地路由到最合适的专家,从而提高模型的性能。
关键创新:AlignX的关键创新在于两个方面:一是使用提示注入微调来解耦不同目标的特征空间,从而避免灾难性遗忘;二是使用MoCaE模块,利用分形和自然几何来校准专家路由,提高推理的可靠性。与现有方法相比,AlignX能够更有效地解决多目标对齐问题,并且具有更好的泛化性。
关键设计:提示注入微调的具体实现方式是,为每个目标设计特定的提示,然后使用这些提示来微调LLM。MoCaE模块的关键设计在于使用分形和自然几何来建模专家之间的关系,从而更准确地校准专家路由。具体的参数设置和损失函数等技术细节在论文中进行了详细描述。
🖼️ 关键图片

📊 实验亮点
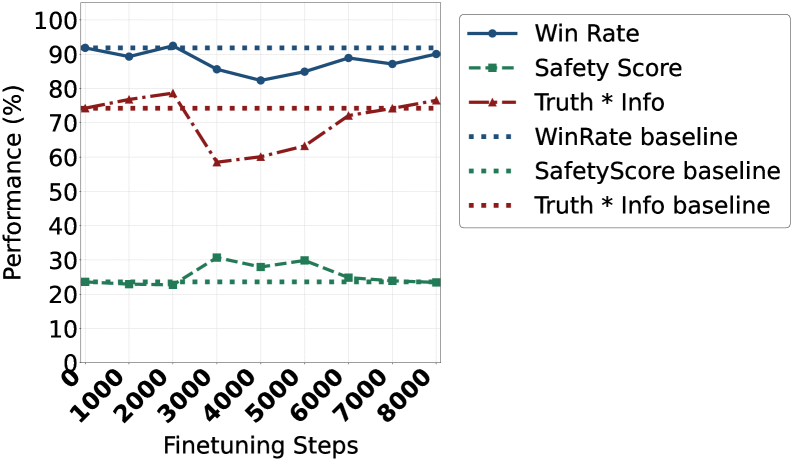
AlignX在Alpaca(帮助性)、BeaverTails(无害性)和TruthfulQA(诚实性)上取得了显著的提升,胜率提高+171.5%,真实性-信息性提高+110.1%,安全违规减少4.3%。与之前的MoE相比,它还降低了超过35%的延迟和内存使用。这些结果表明,AlignX能够有效地提高LLM的HHH对齐效果,并且具有良好的性能。
🎯 应用场景
AlignX具有广泛的应用前景,可以应用于各种需要安全可靠的大型语言模型部署场景,例如智能客服、内容生成、教育辅导等。通过提高LLM的帮助性、无害性和诚实性,AlignX可以减少模型产生有害或不准确信息的风险,从而提高用户体验和信任度。此外,AlignX还可以降低LLM的延迟和内存使用,使其更易于部署在资源受限的环境中。
📄 摘要(原文)
Large Language Models (LLMs) need to be in accordance with human values-being helpful, harmless, and honest (HHH)-is important for safe deployment. Existing works use Supervised Fine-Tuning (SFT) and Mixture-of-Experts (MoE) to align LLMs. However, these works face challenges in multi-objective settings, such as SFT leading to interference between conflicting objectives, while MoEs suffer from miscalibrated routing. We term this failure mode Axis Collapse, marked by (1) disjoint feature spaces causing catastrophic forgetting, and (2) unreliable inference from misrouted experts. To resolve this, we propose AlignX, a two-stage framework. Stage 1 uses prompt-injected fine-tuning to extract axis-specific task features, mitigating catastrophic forgetting. Stage 2 deploys a MoCaE module that calibrates expert routing using fractal and natural geometry, improving inference reliability. AlignX achieves significant gains on Alpaca (Helpfulness), BeaverTails (Harmlessness), and TruthfulQA (Honesty), with +171.5% win rate, +110.1% in truthfulness-informativeness, and 4.3% fewer safety violations. It also reduces latency and memory usage by over 35% compared to prior MoEs. Results across four LLMs validate its generalizability.