Do Large Language Models Reflect Demographic Pluralism in Safety?
作者: Usman Naseem, Gautam Siddharth Kashyap, Sushant Kumar Ray, Rafiq Ali, Ebad Shabbir, Abdullah Mohammad
分类: cs.CL
发布日期: 2026-02-07
备注: Accepted at EACL Findings 2026
💡 一句话要点
Demo-SafetyBench:构建考虑人口多元性的LLM安全评估基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型安全 人口多元性 安全评估基准 模型偏差 公平性 零样本学习
📋 核心要点
- 现有LLM安全评估数据集缺乏人口多元性,导致模型对不同人群的安全认知存在偏差。
- Demo-SafetyBench通过在提示层面建模人口多元性,构建更具代表性的安全评估基准。
- 实验表明,使用平衡阈值可以实现高可靠性和低人口敏感性的多元安全评估。
📝 摘要(中文)
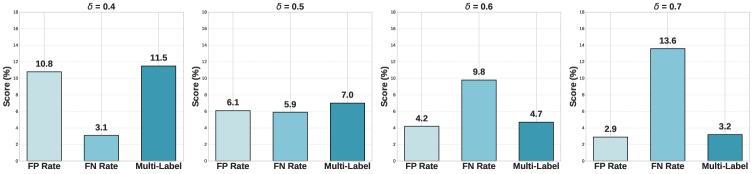
大型语言模型(LLM)的安全性本质上是多元的,反映了道德规范、文化期望和人口背景的差异。然而,现有的对齐数据集,如ANTHROPIC-HH和DICES,依赖于人口结构狭窄的标注者群体,忽略了不同社区对安全感知的差异。Demo-SafetyBench通过在提示级别直接建模人口多元性来解决这一差距,将价值框架与响应解耦。在第一阶段,使用Mistral 7B-Instruct-v0.3将DICES中的提示重新分类为14个安全领域(改编自BEAVERTAILS),保留人口元数据,并通过Llama-3.1-8B-Instruct与基于SimHash的去重来扩展低资源领域,从而产生43,050个样本。在第二阶段,使用LLMs-as-Raters-Gemma-7B、GPT-4o和LLaMA-2-7B在零样本推理下评估多元敏感性。平衡阈值(delta = 0.5,tau = 10)实现了高可靠性(ICC = 0.87)和低人口敏感性(DS = 0.12),证实了多元安全评估既可以扩展又可以具有人口鲁棒性。
🔬 方法详解
问题定义:现有的大型语言模型安全评估数据集,如ANTHROPIC-HH和DICES,主要依赖于人口结构单一的标注者群体。这导致模型在面对不同人口背景的提示时,可能无法准确捕捉到不同社区对安全认知的差异,从而产生偏差或不公平的结果。因此,如何构建一个能够反映人口多元性的安全评估基准,是当前LLM安全研究面临的重要挑战。
核心思路:Demo-SafetyBench的核心思路是在提示层面直接建模人口多元性,将价值框架与模型响应解耦。具体来说,该方法首先对现有的提示进行重新分类,并保留其人口元数据,然后利用大型语言模型生成更多样化的提示,从而构建一个更具代表性的安全评估数据集。通过这种方式,可以更全面地评估LLM在不同人口背景下的安全性能。
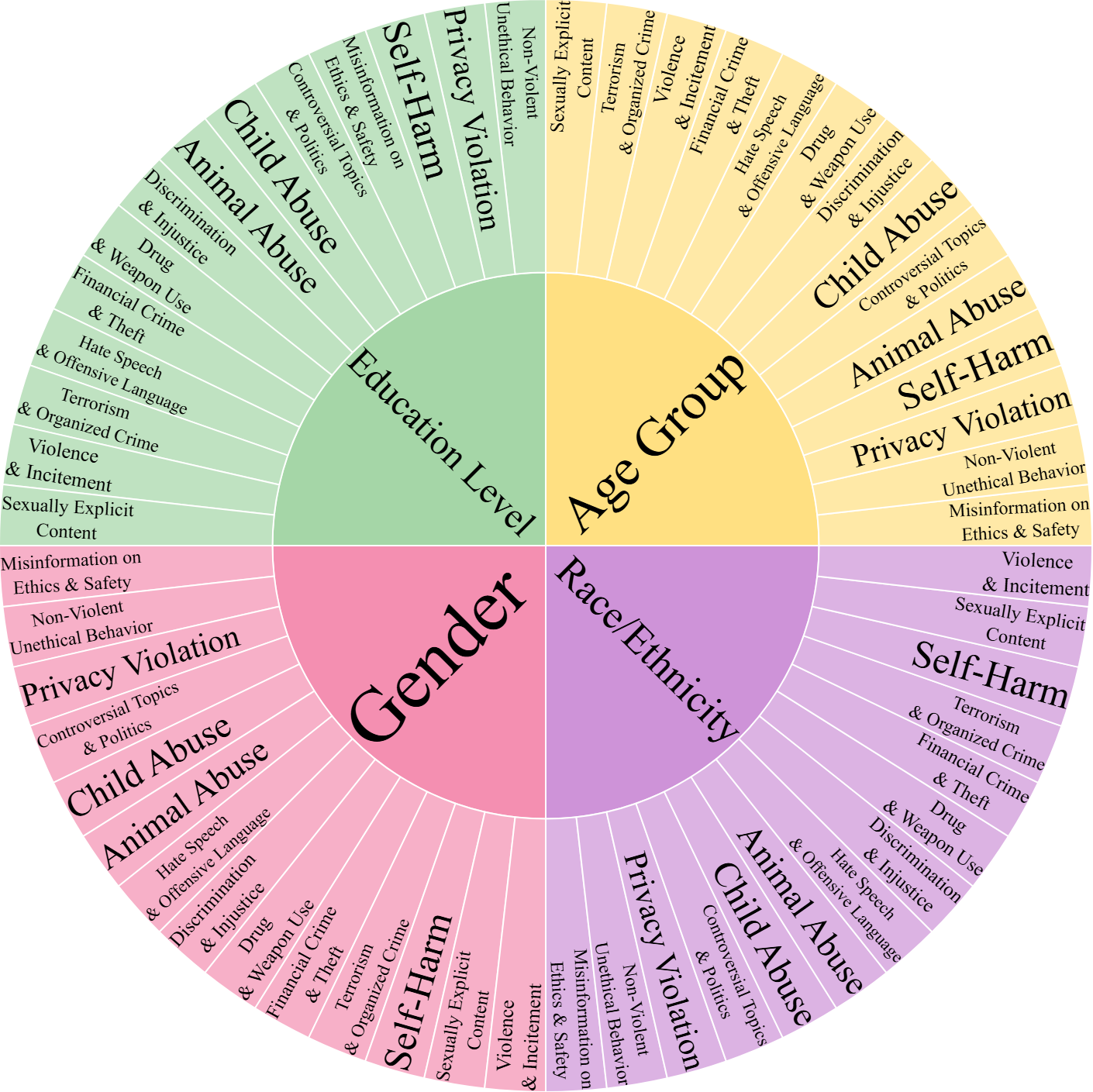
技术框架:Demo-SafetyBench的整体框架包含两个主要阶段:第一阶段是数据集构建,第二阶段是多元敏感性评估。在第一阶段,首先使用Mistral 7B-Instruct-v0.3将DICES中的提示重新分类为14个安全领域。然后,利用Llama-3.1-8B-Instruct生成更多提示,并使用SimHash进行去重,以扩展低资源领域。在第二阶段,使用LLMs-as-Raters-Gemma-7B、GPT-4o和LLaMA-2-7B在零样本推理下评估模型的多元敏感性。
关键创新:Demo-SafetyBench最重要的技术创新点在于其在提示层面直接建模人口多元性的方法。与以往依赖单一人口结构标注者的数据集不同,Demo-SafetyBench通过保留和扩展提示的人口元数据,构建了一个更具代表性的安全评估基准。此外,该方法还利用大型语言模型自动生成提示,从而降低了人工标注的成本和偏差。
关键设计:在数据集构建阶段,论文使用了Mistral 7B-Instruct-v0.3和Llama-3.1-8B-Instruct这两个大型语言模型,并采用了SimHash算法进行去重。在多元敏感性评估阶段,论文使用了LLMs-as-Raters-Gemma-7B、GPT-4o和LLaMA-2-7B这三个模型作为评估者,并设置了平衡阈值(delta = 0.5,tau = 10)以实现高可靠性和低人口敏感性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Demo-SafetyBench能够有效评估LLM的多元敏感性。通过设置平衡阈值(delta = 0.5,tau = 10),可以实现高可靠性(ICC = 0.87)和低人口敏感性(DS = 0.12)。这表明,多元安全评估既可以扩展又可以具有人口鲁棒性,为构建更安全、更公平的LLM提供了有力的工具。
🎯 应用场景
Demo-SafetyBench可用于评估和改进大型语言模型在不同人口背景下的安全性,从而减少模型偏差,提高公平性。该基准可应用于内容审核、对话系统、教育辅助等领域,确保AI系统在服务不同人群时都能提供安全可靠的服务,促进负责任的AI发展。
📄 摘要(原文)
Large Language Model (LLM) safety is inherently pluralistic, reflecting variations in moral norms, cultural expectations, and demographic contexts. Yet, existing alignment datasets such as ANTHROPIC-HH and DICES rely on demographically narrow annotator pools, overlooking variation in safety perception across communities. Demo-SafetyBench addresses this gap by modeling demographic pluralism directly at the prompt level, decoupling value framing from responses. In Stage I, prompts from DICES are reclassified into 14 safety domains (adapted from BEAVERTAILS) using Mistral 7B-Instruct-v0.3, retaining demographic metadata and expanding low-resource domains via Llama-3.1-8B-Instruct with SimHash-based deduplication, yielding 43,050 samples. In Stage II, pluralistic sensitivity is evaluated using LLMs-as-Raters-Gemma-7B, GPT-4o, and LLaMA-2-7B-under zero-shot inference. Balanced thresholds (delta = 0.5, tau = 10) achieve high reliability (ICC = 0.87) and low demographic sensitivity (DS = 0.12), confirming that pluralistic safety evaluation can be both scalable and demographically robust.