Efficient Post-Training Pruning of Large Language Models with Statistical Correction
作者: Peiqi Yu, Jinhao Wang, Xinyi Sui, Nam Ling, Wei Wang, Wei Jiang
分类: cs.CL, cs.LG
发布日期: 2026-02-07
备注: 11 pages, 2 figures, 5 tables
💡 一句话要点
提出基于统计校正的高效大语言模型后训练剪枝方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 后训练剪枝 模型压缩 统计校正 通道剪枝
📋 核心要点
- 现有后训练剪枝方法在效率和精度间存在权衡,启发式方法易受激活异常值影响,重构方法计算成本高昂。
- 该论文提出一种基于模型权重和激活统计特性的轻量级剪枝框架,通过统计校正提高剪枝性能。
- 实验结果表明,该方法在保持计算效率的同时,提升了多种LLM的剪枝性能,验证了统计校正的有效性。
📝 摘要(中文)
后训练剪枝是一种有效减小大型语言模型(LLM)尺寸和推理成本的方法,但现有方法通常面临剪枝质量和计算效率之间的权衡。启发式剪枝方法效率高,但对激活异常值敏感,而基于重构的方法提高了保真度,但计算量大。本文提出了一种基于模型权重和激活的一阶统计特性的轻量级后训练剪枝框架。在剪枝过程中,通道级的统计信息用于校准基于幅度的重要性得分,从而减少来自激活主导通道的偏差。剪枝后,我们应用解析能量补偿来校正由权重移除引起的分布失真。这两个步骤都在没有重新训练、梯度或二阶信息的情况下进行。在多个LLM系列、稀疏模式和评估任务上的实验表明,所提出的方法提高了剪枝性能,同时保持了与启发式方法相当的计算成本。结果表明,简单的统计校正对于LLM的后训练剪枝是有效的。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)后训练剪枝方法,要么计算效率高但剪枝质量差(例如,对激活异常值敏感的启发式方法),要么剪枝质量高但计算成本过高(例如,基于重构的方法)。因此,如何在保证剪枝质量的前提下,降低计算复杂度,是本文要解决的核心问题。
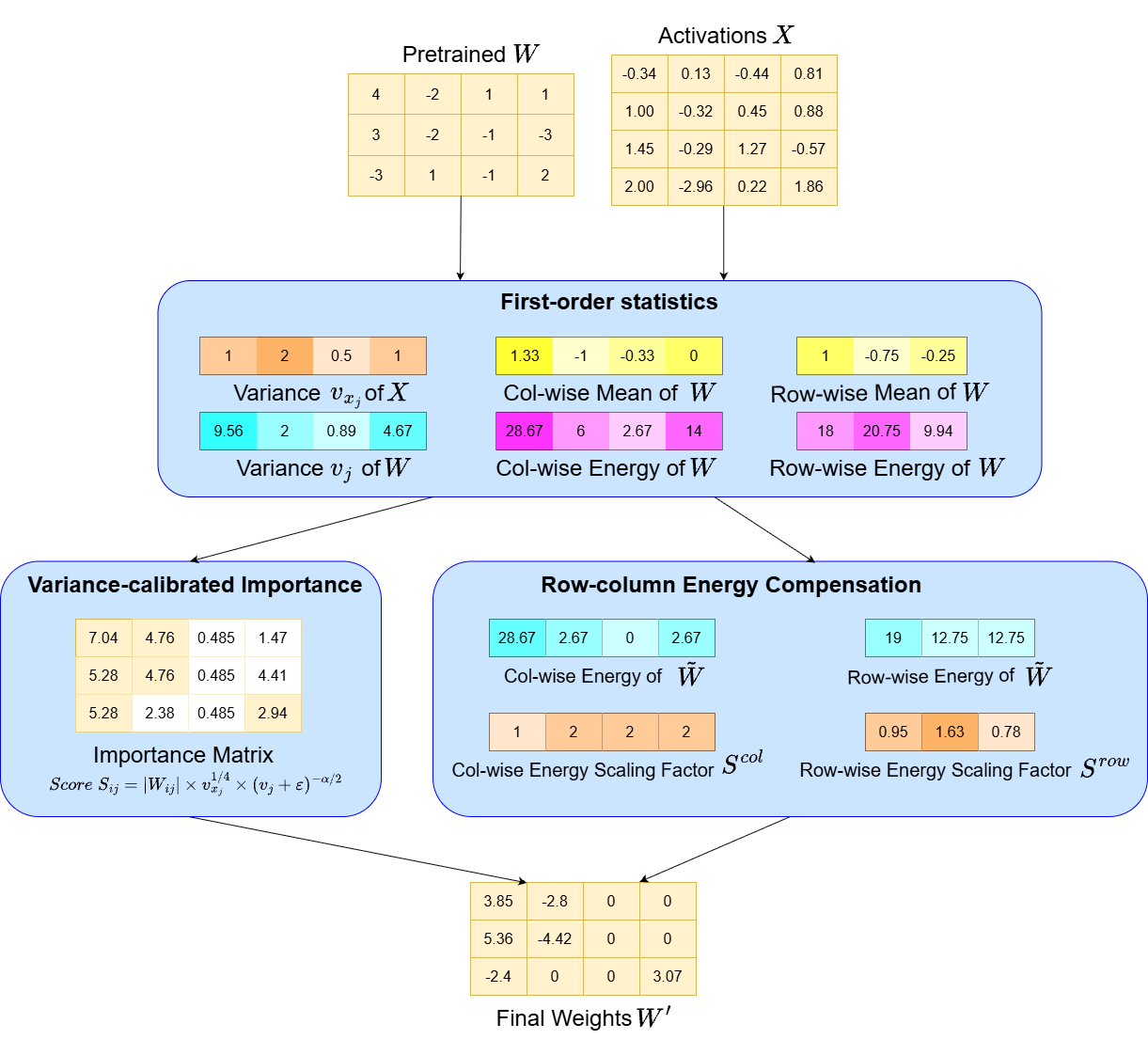
核心思路:论文的核心思路是利用模型权重和激活的一阶统计特性,对剪枝过程进行校正。具体来说,首先利用通道级的统计信息来校准基于幅度的重要性得分,从而减少激活异常值的影响。然后,在剪枝后,通过解析能量补偿来校正由权重移除引起的分布失真。这种方法避免了耗时的重训练、梯度计算或二阶信息的使用,从而实现了高效的剪枝。
技术框架:该框架主要包含两个阶段:1) 基于统计校正的剪枝:利用通道级的统计信息校准基于幅度的重要性得分,减少激活异常值的影响。2) 解析能量补偿:在剪枝后,应用解析能量补偿来校正由权重移除引起的分布失真。这两个阶段都在没有重新训练、梯度或二阶信息的情况下进行。
关键创新:该论文的关键创新在于提出了基于统计校正的剪枝方法,该方法利用模型权重和激活的一阶统计特性,对剪枝过程进行校正,从而在保证剪枝质量的前提下,降低了计算复杂度。与现有方法相比,该方法不需要重训练、梯度计算或二阶信息,因此更加高效。
关键设计:在基于统计校正的剪枝阶段,论文使用通道级的均值和方差来校准基于幅度的重要性得分。具体来说,对于每个通道,计算其激活值的均值和方差,然后利用这些统计信息来调整该通道的权重的重要性得分。在解析能量补偿阶段,论文使用解析方法来估计由权重移除引起的分布失真,然后应用能量补偿来校正这种失真。具体的能量补偿公式未知,需要在论文中查找。
🖼️ 关键图片
📊 实验亮点
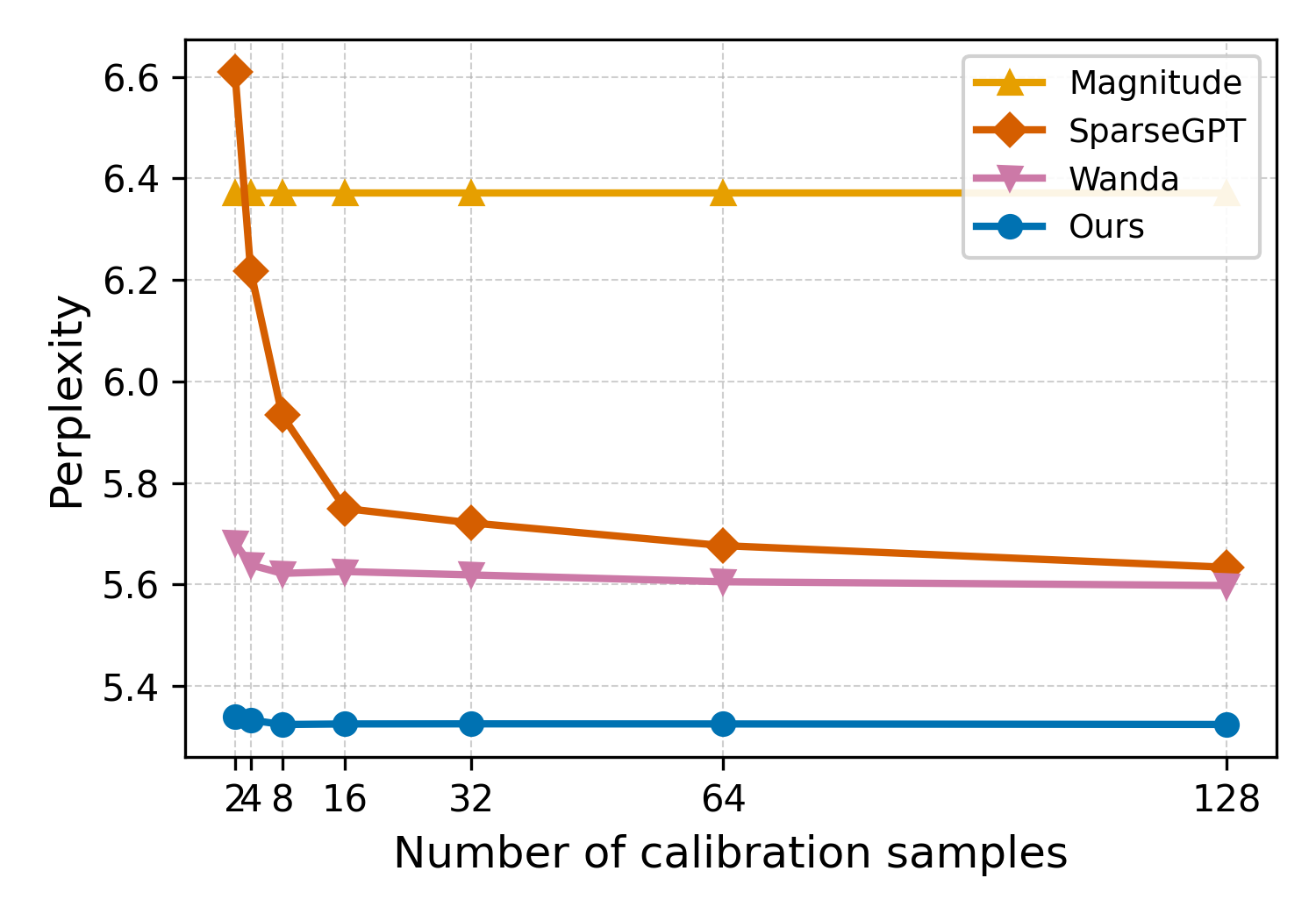
实验结果表明,该方法在多个LLM系列、稀疏模式和评估任务上都取得了显著的性能提升。与现有的启发式方法相比,该方法在保持计算效率的同时,提高了剪枝后的模型精度。具体的性能数据和提升幅度需要在论文中查找。
🎯 应用场景
该研究成果可应用于各种需要部署大型语言模型的场景,尤其是在资源受限的边缘设备或移动设备上。通过高效的后训练剪枝,可以显著减小模型大小和推理成本,从而使得LLM能够在这些设备上运行,并加速LLM在实际应用中的落地。此外,该方法还可以用于模型压缩和加速,提高模型在服务器端的推理效率。
📄 摘要(原文)
Post-training pruning is an effective approach for reducing the size and inference cost of large language models (LLMs), but existing methods often face a trade-off between pruning quality and computational efficiency. Heuristic pruning methods are efficient but sensitive to activation outliers, while reconstruction-based approaches improve fidelity at the cost of heavy computation. In this work, we propose a lightweight post-training pruning framework based on first-order statistical properties of model weights and activations. During pruning, channel-wise statistics are used to calibrate magnitude-based importance scores, reducing bias from activation-dominated channels. After pruning, we apply an analytic energy compensation to correct distributional distortions caused by weight removal. Both steps operate without retraining, gradients, or second-order information. Experiments across multiple LLM families, sparsity patterns, and evaluation tasks show that the proposed approach improves pruning performance while maintaining computational cost comparable to heuristic methods. The results suggest that simple statistical corrections can be effective for post-training pruning of LLMs.