TernaryLM: Memory-Efficient Language Modeling via Native 1-Bit Quantization with Adaptive Layer-wise Scaling
作者: Nisharg Nargund, Priyesh Shukla
分类: cs.CL, cs.AI
发布日期: 2026-02-07
🔗 代码/项目: GITHUB
💡 一句话要点
TernaryLM:通过自适应层缩放的原生1比特量化实现内存高效的语言建模。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 三元量化 语言模型 内存高效 边缘计算 直通估计器 自适应缩放 Transformer
📋 核心要点
- 现有大语言模型计算资源需求大,难以在边缘设备上部署,限制了应用场景。
- TernaryLM采用原生1比特三元量化,从头开始学习量化感知表示,降低内存占用。
- 实验表明,TernaryLM在内存减少的同时,保持了良好的语言建模和下游任务性能。
📝 摘要(中文)
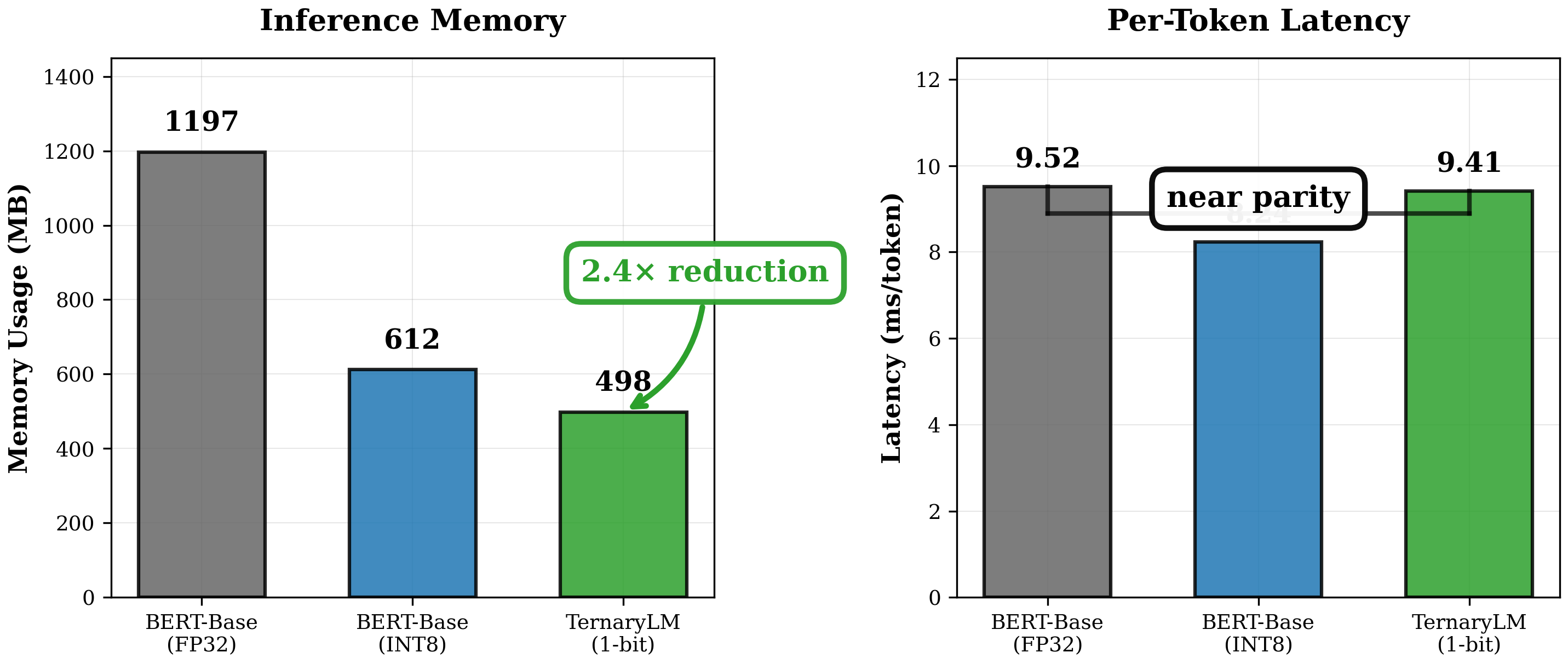
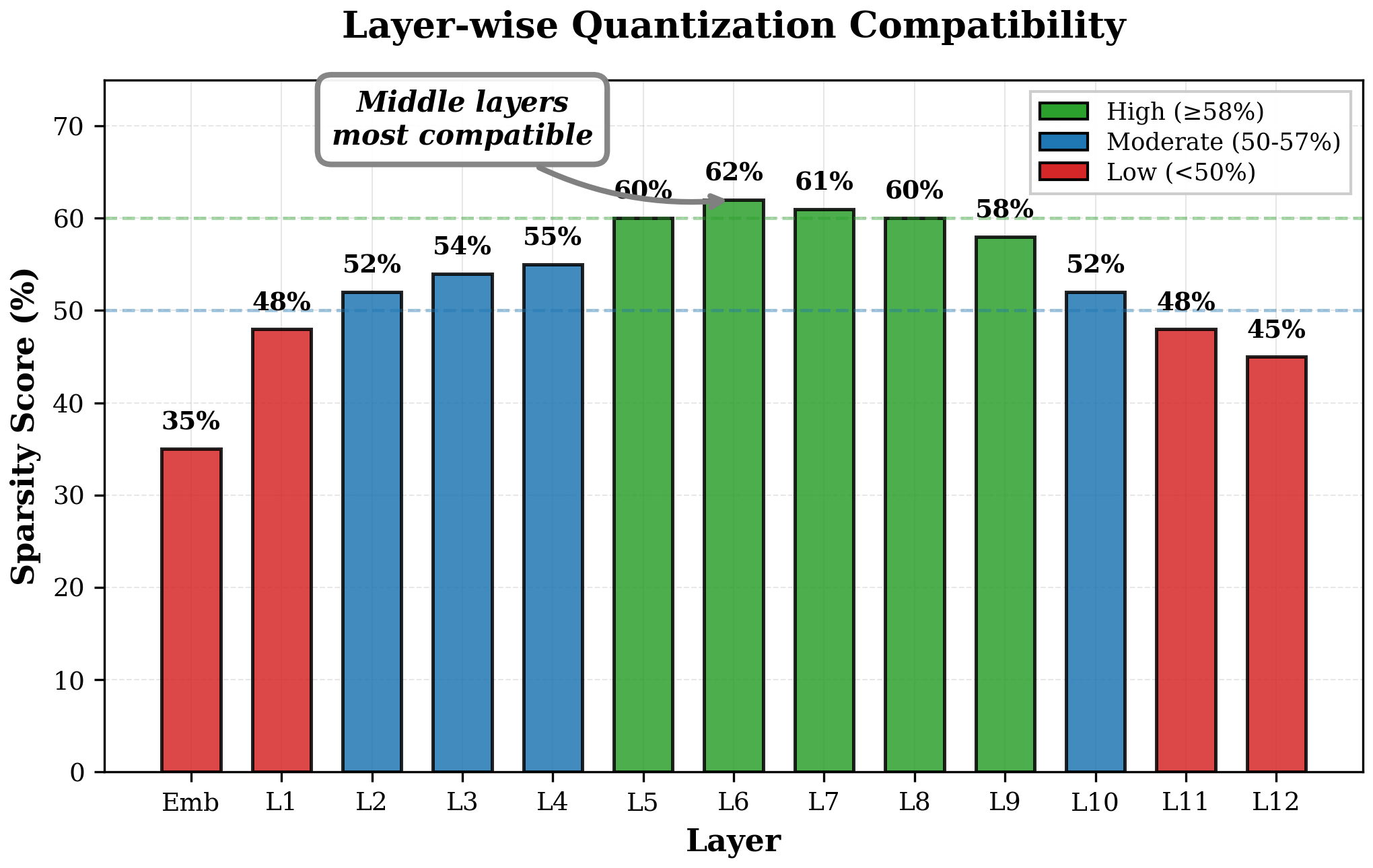
大型语言模型(LLMs)虽然性能卓越,但需要大量的计算资源,限制了其在边缘设备和资源受限环境中的部署。我们提出了TernaryLM,一个拥有1.32亿参数的Transformer架构,它在训练过程中采用原生1比特三元量化{-1, 0, +1},在不牺牲语言建模能力的前提下,实现了显著的内存缩减。与量化预训练全精度模型的后训练量化方法不同,TernaryLM使用直通估计器和自适应的逐层缩放因子,从头开始学习量化感知表示。实验表明:(1)在TinyStories上的验证困惑度为58.42;(2)在MRPC释义检测上的下游迁移F1值为82.47%;(3)内存减少2.4倍(498MB vs 1197MB),且推理延迟相当;(4)在不同的语料库中具有稳定的训练动态。我们提供了逐层量化分析,表明中间Transformer层与极端量化的兼容性最高,为未来的非均匀精度策略提供了信息。我们的结果表明,原生1比特训练是高效神经语言模型的一个有希望的方向。代码可在https://github.com/1nisharg/TernaryLM-Memory-Efficient-Language-Modeling获取。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)计算资源需求高,难以在资源受限环境中部署的问题。现有方法,如后训练量化,通常依赖于预训练的全精度模型,并且可能导致性能下降。因此,需要一种能够在训练过程中直接进行量化,从而实现内存高效的语言建模方法。
核心思路:TernaryLM的核心思路是在训练过程中采用原生1比特三元量化,即权重被量化为{-1, 0, +1}。通过从头开始学习量化感知表示,避免了后训练量化带来的性能损失。此外,使用自适应的逐层缩放因子,可以更好地适应不同层对量化的敏感程度。
技术框架:TernaryLM基于Transformer架构,主要包括以下模块:嵌入层、Transformer编码器层、线性层和量化模块。在训练过程中,权重被量化为三元值,并使用直通估计器(Straight-Through Estimator, STE)来近似梯度,从而实现可微的量化操作。自适应的逐层缩放因子用于调整不同层的量化范围。
关键创新:TernaryLM的关键创新在于原生1比特三元量化训练。与后训练量化方法不同,TernaryLM从头开始学习量化感知表示,避免了全精度模型到低精度模型的转换带来的信息损失。此外,自适应的逐层缩放因子可以更好地适应不同层对量化的敏感程度,从而提高量化模型的性能。
关键设计:TernaryLM的关键设计包括:1) 使用直通估计器来近似梯度,实现可微的量化操作;2) 采用自适应的逐层缩放因子,通过学习得到每个层的最佳量化范围;3) 使用三元量化{-1, 0, +1},在保持模型表达能力的同时,显著降低内存占用;4) 损失函数采用标准的交叉熵损失函数,并结合量化约束,以保证训练的稳定性。
🖼️ 关键图片

📊 实验亮点
TernaryLM在TinyStories数据集上取得了58.42的验证困惑度,在MRPC释义检测任务上取得了82.47%的F1值。与全精度模型相比,TernaryLM实现了2.4倍的内存缩减(498MB vs 1197MB),并且推理延迟相当。此外,实验还表明,TernaryLM在不同的语料库中具有稳定的训练动态。
🎯 应用场景
TernaryLM具有广泛的应用前景,尤其是在边缘计算和资源受限的环境中。例如,它可以被部署在移动设备、嵌入式系统和物联网设备上,从而实现本地化的自然语言处理任务,如语音识别、机器翻译和文本生成。此外,TernaryLM还可以用于构建低功耗的AI加速器,从而降低数据中心的能耗。
📄 摘要(原文)
Large language models (LLMs) achieve remarkable performance but demand substantial computational resources, limiting deployment on edge devices and resource-constrained environments. We present TernaryLM, a 132M parameter transformer architecture that employs native 1-bit ternary quantization {-1, 0, +1} during training, achieving significant memory reduction without sacrificing language modeling capability. Unlike post-training quantization approaches that quantize pre-trained full-precision models, TernaryLM learns quantization-aware representations from scratch using straight-through estimators and adaptive per-layer scaling factors. Our experiments demonstrate: (1) validation perplexity of 58.42 on TinyStories; (2) downstream transfer with 82.47 percent F1 on MRPC paraphrase detection; (3) 2.4x memory reduction (498MB vs 1197MB) with comparable inference latency; and (4) stable training dynamics across diverse corpora. We provide layer-wise quantization analysis showing that middle transformer layers exhibit highest compatibility with extreme quantization, informing future non-uniform precision strategies. Our results suggest that native 1-bit training is a promising direction for efficient neural language models. Code is available at https://github.com/1nisharg/TernaryLM-Memory-Efficient-Language-Modeling.