Your Language Model Secretly Contains Personality Subnetworks
作者: Ruimeng Ye, Zihan Wang, Zinan Ling, Yang Xiao, Manling Li, Xiaolong Ma, Bo Hui
分类: cs.CL, cs.AI
发布日期: 2026-02-06
备注: ICLR 2026
💡 一句话要点
揭示大语言模型中隐藏的个性子网络,实现无需训练的个性化控制。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 个性化 子网络 模型剪枝 可解释性 对比学习 无训练
📋 核心要点
- 现有方法依赖外部知识调整LLM行为,但忽略了模型自身参数中可能已蕴含个性化信息。
- 通过识别与个性相关的激活特征,并使用掩码策略隔离个性子网络,实现个性化控制。
- 实验表明,该方法无需训练即可实现更强的个性对齐,且效率高于依赖外部知识的基线方法。
📝 摘要(中文)
本文揭示了大语言模型(LLMs)的参数空间中隐藏着特定于不同个性的子网络。与以往通过提示、检索增强生成(RAG)或微调等外部知识来调整模型行为的方法不同,本文探索了LLMs是否已经将这些知识嵌入在其参数中。研究表明,LLMs确实包含个性化的子网络。通过少量校准数据集,可以识别与不同个性相关的独特激活特征。基于这些统计数据,本文提出了一种掩码策略,用于隔离轻量级的个性子网络。此外,还探讨了如何从模型中发现导致二元对立个性(如内向-外向)的对立子网络,并引入了一种对比剪枝策略,以识别负责对立个性之间统计差异的参数。该方法无需任何训练,仅依赖于语言模型现有的参数空间。在各种评估设置中,所得到的子网络表现出比需要外部知识的基线方法更强的个性对齐性,同时效率更高。研究结果表明,多样化的人类行为并非仅仅诱导LLMs产生,而是已经嵌入在其参数空间中,为大型语言模型中可控和可解释的个性化提供了一个新的视角。
🔬 方法详解
问题定义:现有方法通常依赖于外部知识(如提示、RAG或微调)来使大型语言模型适应不同的个性。然而,这些方法增加了额外的计算负担,并且没有充分利用模型本身可能已经具备的个性化能力。因此,本文旨在探索大型语言模型是否在其参数空间中已经包含了特定于不同个性的子网络,从而实现无需额外训练的个性化控制。
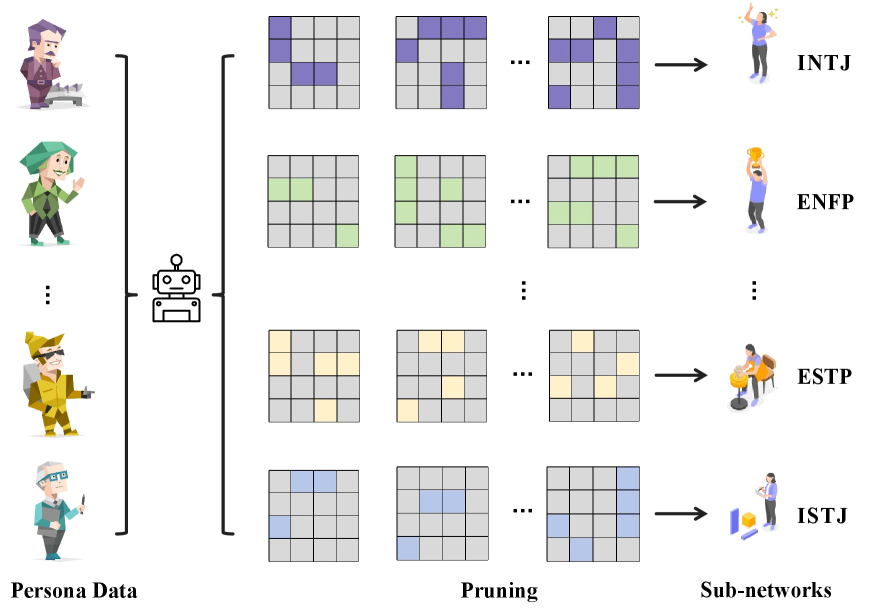
核心思路:本文的核心思路是,不同的个性会在大型语言模型的不同神经元中产生不同的激活模式。通过分析这些激活模式,可以识别出与特定个性相关的子网络。然后,通过掩码策略,可以隔离这些子网络,从而控制模型的个性化行为。对于二元对立的个性,则通过对比剪枝策略来增强子网络之间的差异。
技术框架:该方法主要包含以下几个阶段:1) 数据收集:收集少量校准数据集,包含不同个性的文本样本。2) 激活分析:使用校准数据集,计算模型中每个神经元对不同个性的激活统计信息。3) 子网络隔离:基于激活统计信息,使用掩码策略隔离特定于不同个性的子网络。4) 对比剪枝(针对二元对立个性):使用对比剪枝策略,增强对立个性子网络之间的差异。5) 评估:评估隔离出的子网络在各种个性化任务上的表现。
关键创新:该方法最重要的创新点在于,它揭示了大型语言模型在其参数空间中已经包含了特定于不同个性的子网络,并提出了一种无需训练的方法来隔离和利用这些子网络。这与以往依赖外部知识的方法形成了鲜明对比,提供了一种更高效、更可控的个性化方法。
关键设计:1) 激活统计:使用校准数据集计算每个神经元对不同个性的平均激活值。2) 掩码策略:根据激活统计信息,为每个神经元分配一个掩码值,用于控制其在不同个性下的激活程度。3) 对比剪枝:对于二元对立个性,使用对比损失函数来指导剪枝过程,从而增强对立个性子网络之间的差异。具体而言,对比损失函数旨在最大化对立个性子网络在激活统计上的差异。
🖼️ 关键图片
📊 实验亮点
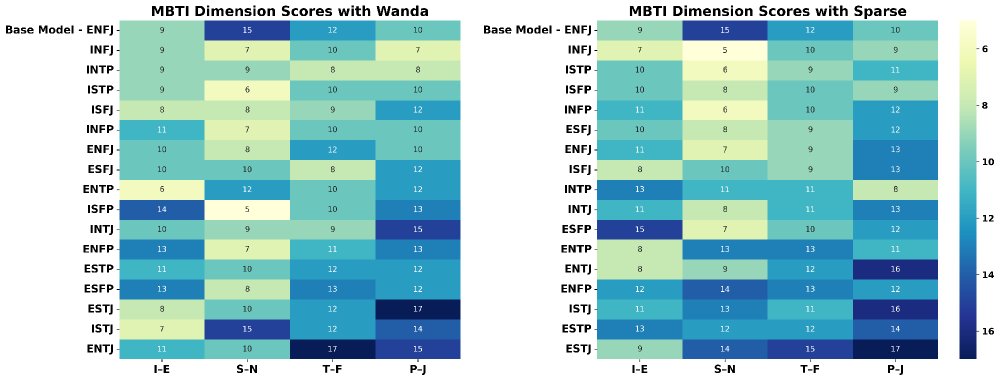
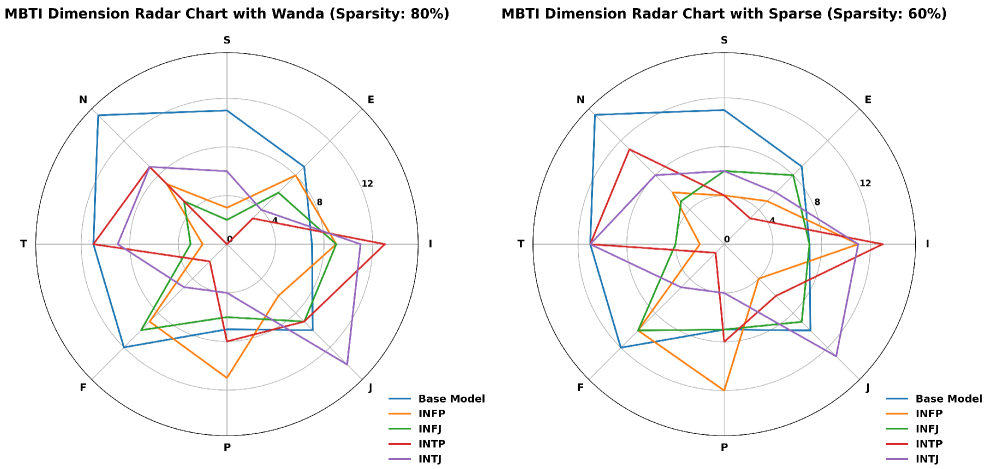
实验结果表明,该方法在各种个性化任务上都取得了显著的性能提升。例如,在个性化对话生成任务中,该方法生成的对话更符合目标个性,且与人类生成的对话更加相似。与需要外部知识的基线方法相比,该方法在性能上取得了显著提升,同时计算效率更高。
🎯 应用场景
该研究成果可应用于个性化对话系统、角色扮演游戏、情感分析等领域。通过控制语言模型的个性,可以创建更具吸引力、更符合用户需求的AI应用。此外,该研究也为理解大型语言模型的内部机制提供了新的视角,有助于开发更可控、更可解释的AI系统。
📄 摘要(原文)
Humans shift between different personas depending on social context. Large Language Models (LLMs) demonstrate a similar flexibility in adopting different personas and behaviors. Existing approaches, however, typically adapt such behavior through external knowledge such as prompting, retrieval-augmented generation (RAG), or fine-tuning. We ask: do LLMs really need external context or parameters to adapt to different behaviors, or do they already have such knowledge embedded in their parameters? In this work, we show that LLMs already contain persona-specialized subnetworks in their parameter space. Using small calibration datasets, we identify distinct activation signatures associated with different personas. Guided by these statistics, we develop a masking strategy that isolates lightweight persona subnetworks. Building on the findings, we further discuss: how can we discover opposing subnetwork from the model that lead to binary-opposing personas, such as introvert-extrovert? To further enhance separation in binary opposition scenarios, we introduce a contrastive pruning strategy that identifies parameters responsible for the statistical divergence between opposing personas. Our method is entirely training-free and relies solely on the language model's existing parameter space. Across diverse evaluation settings, the resulting subnetworks exhibit significantly stronger persona alignment than baselines that require external knowledge while being more efficient. Our findings suggest that diverse human-like behaviors are not merely induced in LLMs, but are already embedded in their parameter space, pointing toward a new perspective on controllable and interpretable personalization in large language models.