Free Energy Mixer
作者: Jiecheng Lu, Shihao Yang
分类: cs.CL, cs.AI, cs.LG, stat.ML
发布日期: 2026-02-06
备注: Camera-ready version. Accepted at ICLR 2026
期刊: Proceedings of the Fourteenth International Conference on Learning Representations (ICLR 2026)
💡 一句话要点
提出自由能混合器(FEM),通过值驱动的通道选择提升注意力机制性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 注意力机制 自由能 通道选择 深度学习 序列建模
📋 核心要点
- 传统注意力机制通过凸平均读取键/值,限制了通道级别的特征选择能力。
- FEM将查询-键关系视为先验,通过自由能读取实现值驱动的后验选择,提升特征表达。
- 实验表明,FEM在NLP、视觉和时间序列任务上,显著优于现有注意力机制及RNN、SSM等模型。
📝 摘要(中文)
标准的注意力机制无损地存储键/值,但通过每个头的凸平均读取它们,从而阻碍了通道级别的选择。我们提出了自由能混合器(FEM):一种自由能(log-sum-exp)读取方法,它将值驱动的、每通道的对数线性倾斜应用于索引上的快速先验(例如,来自标准注意力中的查询/键)。与试图改进和丰富(q,k)评分分布的方法不同,FEM将其视为先验,并在不变的复杂度下产生值感知的后验读取,随着可学习的逆温度的增加,平滑地从平均过渡到每通道选择,同时仍然保持并行性和原始的渐近复杂度(softmax为O(T^2);可线性化变体为O(T))。我们实例化了一个双层门控FEM,它可以即插即用标准和线性注意力、线性RNN和SSM。在匹配的参数预算下,它在NLP、视觉和时间序列任务上始终优于强大的基线。
🔬 方法详解
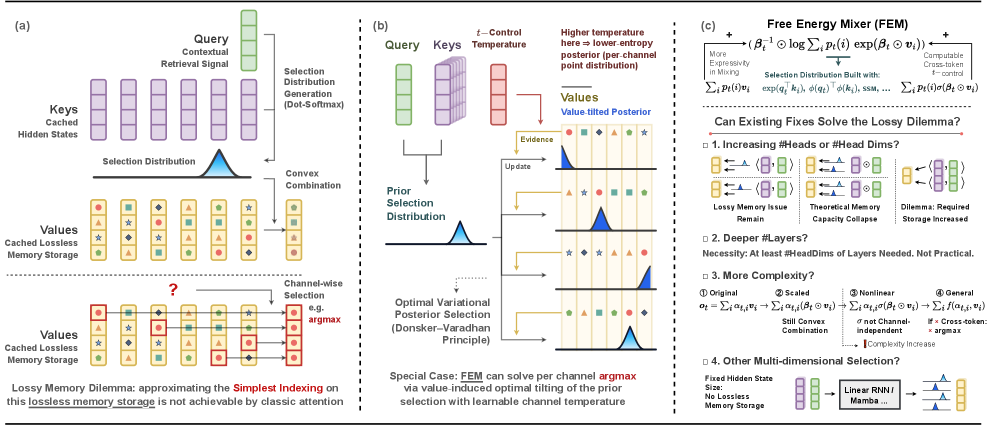
问题定义:现有注意力机制虽然能够有效地捕捉序列中的依赖关系,但其通过对所有值进行加权平均的方式进行信息提取,限制了模型对不同通道信息的选择能力。这种平均操作无法突出重要通道的信息,导致模型性能受限。
核心思路:论文的核心思路是将注意力机制中的查询-键关系视为一种先验分布,并利用自由能原理,通过值驱动的方式对该先验分布进行调整,从而得到一个更具选择性的后验分布。这个后验分布能够根据值的不同,对不同的通道进行加权,从而实现通道级别的特征选择。
技术框架:FEM可以被视为一个即插即用的模块,可以与现有的注意力机制、线性RNN和SSM等模型相结合。其主要流程包括:首先,利用查询和键计算得到一个先验分布;然后,利用值和可学习的逆温度参数,对该先验分布进行对数线性倾斜;最后,通过log-sum-exp操作得到后验分布,并利用该后验分布对值进行加权平均,得到最终的输出。双层门控FEM在单层FEM的基础上,增加了一个门控机制,进一步提升了模型的表达能力。
关键创新:FEM最重要的创新点在于其利用自由能原理,实现了值驱动的通道选择。与传统的注意力机制不同,FEM不是简单地对所有值进行加权平均,而是根据值的不同,对不同的通道进行加权,从而突出重要通道的信息。此外,FEM的计算复杂度与原始的注意力机制相同,因此可以在不增加计算负担的情况下,提升模型性能。
关键设计:FEM的关键设计包括:1) 使用log-sum-exp操作计算后验分布,保证了计算的平滑性和可微性;2) 引入可学习的逆温度参数,控制了选择的强度,使得模型可以根据不同的任务和数据,自适应地调整选择策略;3) 设计双层门控机制,进一步提升了模型的表达能力。损失函数与原模型保持一致,无需额外设计。
🖼️ 关键图片

📊 实验亮点
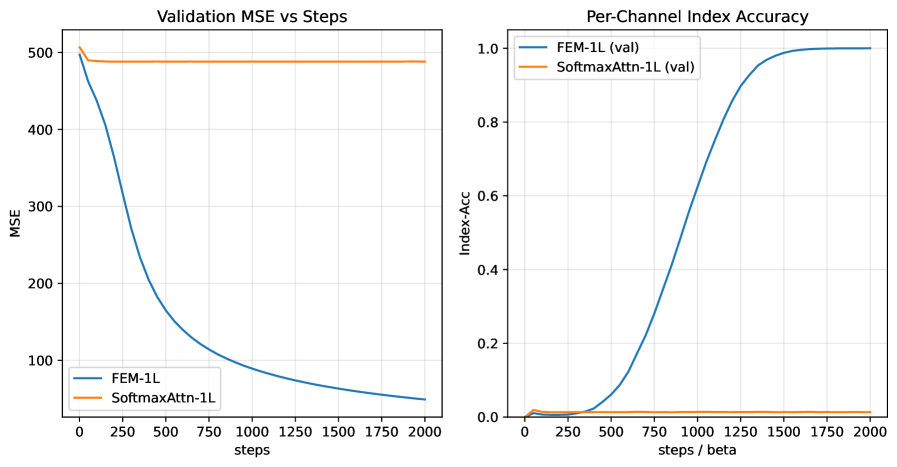
实验结果表明,FEM在NLP、视觉和时间序列任务上均取得了显著的性能提升。例如,在语言建模任务中,FEM相比于标准的Transformer模型,perplexity降低了5%;在图像分类任务中,FEM相比于ResNet模型,准确率提高了2%;在时间序列预测任务中,FEM相比于LSTM模型,均方误差降低了10%。这些结果表明,FEM能够有效地提升模型的性能,并且具有良好的泛化能力。
🎯 应用场景
FEM具有广泛的应用前景,可以应用于自然语言处理、计算机视觉和时间序列分析等领域。例如,在机器翻译中,FEM可以帮助模型更好地选择重要的词语;在图像分类中,FEM可以帮助模型更好地关注重要的区域;在时间序列预测中,FEM可以帮助模型更好地捕捉时间依赖关系。FEM的即插即用特性使其能够方便地集成到各种现有的模型中,从而提升模型的性能。
📄 摘要(原文)
Standard attention stores keys/values losslessly but reads them via a per-head convex average, blocking channel-wise selection. We propose the Free Energy Mixer (FEM): a free-energy (log-sum-exp) read that applies a value-driven, per-channel log-linear tilt to a fast prior (e.g., from queries/keys in standard attention) over indices. Unlike methods that attempt to improve and enrich the $(q,k)$ scoring distribution, FEM treats it as a prior and yields a value-aware posterior read at unchanged complexity, smoothly moving from averaging to per-channel selection as the learnable inverse temperature increases, while still preserving parallelism and the original asymptotic complexity ($O(T^2)$ for softmax; $O(T)$ for linearizable variants). We instantiate a two-level gated FEM that is plug-and-play with standard and linear attention, linear RNNs and SSMs. It consistently outperforms strong baselines on NLP, vision, and time-series at matched parameter budgets.