Comprehensive Evaluation of Large Language Models on Software Engineering Tasks: A Multi-Task Benchmark
作者: Go Frendi Gunawan, Mukhlis Amien
分类: cs.SE, cs.CL
发布日期: 2026-02-06
备注: 10 pages, 7 figures. Under review. Code and data will be fully released
💡 一句话要点
多任务基准测试全面评估大语言模型在软件工程任务中的表现
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 软件工程 多任务学习 基准测试 自动化评估
📋 核心要点
- 现有软件工程领域的大语言模型评估基准覆盖的任务类型有限,无法全面反映模型能力。
- 构建了一个包含缺陷修复、功能开发等五类任务的多任务评估基准,以更全面地评估LLMs。
- 实验揭示了模型在完成时间、工具效率等方面存在显著差异,并识别出低效率模式。
📝 摘要(中文)
本文针对大语言模型(LLMs)在软件工程领域的应用,提出了一个多任务评估基准。该基准涵盖了五个具有代表性的软件工程任务:缺陷修复、功能开发、代码重构、技术文案撰写和研究综合。通过自动验证框架,评估了11个先进的LLMs的输出质量和完成效率。研究发现:(1)即使模型取得了相同的完美分数,其完成时间、工具效率和预估成本也存在显著差异(分别高达22倍、49倍和53倍);(2)工具使用频率与成功率之间没有相关性(r = 0.077, p = 0.575);(3)识别出两种低效率模式:循环低效和推理低效;(4)编码任务的成功率达到100%,而研究任务更具挑战性(90.9%)。所有实验数据、验证脚本和分析代码均已开源,以保证可复现性。
🔬 方法详解
问题定义:现有的大语言模型在软件工程领域的应用评估缺乏全面性,已有的基准测试无法覆盖软件工程的各类活动,难以有效评估模型在不同任务上的真实能力。此外,现有评估方法对模型效率的考量不足,忽略了模型在完成任务时的时间成本和资源消耗。
核心思路:本文的核心思路是通过构建一个多任务的评估基准,覆盖软件工程中具有代表性的任务类型,从而更全面地评估大语言模型的能力。同时,引入自动化验证框架,不仅评估输出质量,还关注完成效率,包括完成时间、工具效率和预估成本。
技术框架:该研究的技术框架主要包括以下几个部分:1) 任务选择:选取了缺陷修复、功能开发、代码重构、技术文案撰写和研究综合五个代表性的软件工程任务。2) 模型选择:选择了11个先进的大语言模型进行评估。3) 自动化验证框架:构建了自动化的验证框架,用于评估模型的输出质量和完成效率。4) 效率指标:定义了完成时间、工具效率和预估成本等效率指标,用于衡量模型的资源消耗。
关键创新:该研究的关键创新在于:1) 构建了一个更全面的多任务评估基准,覆盖了软件工程中多种类型的任务。2) 引入了自动化验证框架,可以同时评估模型的输出质量和完成效率。3) 发现了模型在完成时间、工具效率和预估成本等方面存在显著差异,并识别出两种低效率模式。
关键设计:在自动化验证框架的设计上,针对不同的任务类型,采用了不同的验证方法。例如,对于缺陷修复任务,采用了单元测试来验证修复后的代码是否能够通过测试用例。对于功能开发任务,采用了人工评估和代码审查相结合的方式来评估代码质量。此外,在效率指标的计算上,考虑了模型调用外部工具的次数和时间,以及预估的计算资源成本。
🖼️ 关键图片

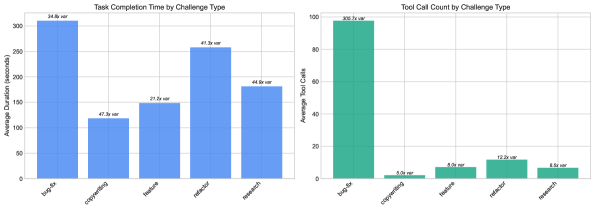

📊 实验亮点
实验结果表明,即使模型在输出质量上表现相同,其完成时间、工具效率和预估成本也存在显著差异(分别高达22倍、49倍和53倍)。工具使用频率与成功率之间没有明显相关性(r = 0.077, p = 0.575)。编码任务的成功率达到100%,而研究任务的成功率相对较低(90.9%)。
🎯 应用场景
该研究成果可应用于指导大语言模型在软件工程领域的选型和优化。开发者可以根据不同任务的需求,选择最适合的模型,并针对模型的不足之处进行改进。此外,该基准测试可以促进大语言模型在软件工程领域的进一步发展,推动自动化软件工程技术的进步。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated remarkable capabilities in software engineering, yet comprehensive benchmarks covering diverse SE activities remain limited. We present a multi-task evaluation of 11 state-of-the-art LLMs across five representative software engineering tasks: bug fixing, feature development, code refactoring, technical copywriting, and research synthesis. Our automated verification framework measures both output quality and completion efficiency. Key findings reveal that (1) models achieving identical perfect scores exhibit 22x variation in completion time, 49x variation in tool efficiency, and 53x variation in estimated cost; (2) tool usage frequency shows no correlation with success (r = 0.077, p = 0.575) - one model used 917 tool calls while another solved the same task with 3 calls; (3) we identify two distinct inefficiency patterns: loop inefficiency and inference inefficiency; and (4) coding tasks achieve 100 percent success while research tasks present greater challenges (90.9 percent). We release all experimental data, verification scripts, and analysis code for full reproducibility.